
")
Каноническое проектирование ис. организация канонического проектирования ис ориентирована на использование главным образом каскадной модели жизненного цикла ис
Организация канонического проектирования ИС ориентирована на использование главным образом каскадной модели жизненного цикла ИС. Стадии и этапы работы описаны в стандарте ГОСТ 34.601-90,( http://www.gostedu.ru/10698.html ).
В зависимости от сложности объекта автоматизации и набора задач, требующих решения при создании конкретной ИС, стадии и этапы работ могут иметь различную трудоемкость. Допускается объединять последовательные этапы и даже исключать некоторые из них на любой стадии проекта. Допускается также начинать выполнение работ следующей стадии до окончания предыдущей.
Стадии и этапы создания ИС, выполняемые организациями-участниками, прописываются в договорах и технических заданиях на выполнение работ:

| Oбследование- это изучение и диагностический анализ организационной структуры предприятия, его деятельности и существующей системы обработки информации. |
Материалы, полученные в результате обследования, используются для:
· обоснования разработки и поэтапного внедрения систем;
· составления технического задания на разработку систем;
· разработки технического и рабочего проектов систем.
На этапе обследования целесообразно выделить две составляющие: определение стратегии внедрения ИС и детальный анализ деятельности организации.
Основная задача первого этапа обследования – оценка реального объема проекта, его целей и задач на основе выявленных функций и информационных элементов автоматизируемого объекта высокого уровня. Эти задачи могут быть реализованы или заказчиком ИС самостоятельно, или с привлечением консалтинговых организаций. Этап предполагает тесное взаимодействие с основными потенциальными пользователями системы и бизнес-экспертами. Основная задача взаимодействия – получить полное и однозначное понимание требований заказчика. Как правило, нужная информация может быть получена в результате интервью, бесед или семинаров с руководством, экспертами и пользователями.
По завершении этой стадии обследования появляется возможность определить вероятные технические подходы к созданию системы и оценить затраты на ее реализацию (затраты на аппаратное обеспечение, закупаемое программное обеспечение и разработку нового программного обеспечения ).
Результатом этапа определения стратегии является документ (технико-экономическое обоснование проекта).
| Технико-экономическое обоснование (ТЭО, англ. business case) — документ, в котором представлена информация, из которой выводится целесообразность (или нецелесообразность) создания продукта или услуги. ТЭО содержит анализ затрат и результатов какого-либо проекта. ТЭО позволяет инвесторам определить, стоит ли вкладывать деньги в предлагаемый проект. |
В данном документе должно быть четко сформулировано, что получит заказчик, если согласится финансировать проект, когда он получит готовый продукт (график выполнения работ) и сколько это будет стоить (для крупных проектов должен быть составлен график финансирования на разных этапах работ). В документе желательно отразить не только затраты, но и выгоду проекта, например время окупаемости проекта, ожидаемый экономический эффект (если его удается оценить).
Ориентировочное содержание этого документа:
· ограничения, риски, критические факторы, которые могут повлиять на успешность проекта;
· совокупность условий, при которых предполагается эксплуатировать будущую систему: архитектура системы, аппаратные и программные ресурсы, условия функционирования, обслуживающий персонал и пользователи системы;
· сроки завершения отдельных этапов, форма приемки/сдачи работ, привлекаемые ресурсы, меры по защите информации;
· описание выполняемых системой функций;
· возможности развития системы;
· информационные объекты системы;
· интерфейсы и распределение функций между человеком и системой;
· требования к программным и информационным компонентам ПО, требования к СУБД;
· что не будет реализовано в рамках проекта.
На этапе детального анализа деятельности организации изучаются задачи, обеспечивающие реализацию функций управления, организационная структура, штаты и содержание работ по управлению предприятием, а также характер подчиненности вышестоящим органам управления. На этом этапе должны быть выявлены:
· инструктивно-методические и директивные материалы, на основании которых определяются состав подсистем и перечень задач;
· возможности применения новых методов решения задач.
Аналитики собирают и фиксируют информацию в двух взаимосвязанных формах:
· функции – информация о событиях и процессах, которые происходят в бизнесе;
· сущности – информация о вещах, имеющих значение для организации и о которых что-то известно.
При изучении каждой функциональной задачи управления определяются:
· наименование задачи; сроки и периодичность ее решения;
· степень формализуемости задачи;
· источники информации, необходимые для решения задачи;
· показатели и их количественные характеристики;
· порядок корректировки информации;
· действующие алгоритмы расчета показателей и возможные методы контроля;
· действующие средства сбора, передачи и обработки информации;
· действующие средства связи;
· принятая точность решения задачи;
· трудоемкость решения задачи;
· действующие формы представления исходных данных и результатов их обработки в виде документов;
· потребители результатной информации по задаче.
Одной из наиболее трудоемких, хотя и хорошо формализуемых задач этого этапа является описание документооборота организации. При обследовании документооборота составляется схема маршрута движения документов, которая должна отразить, (рис. 10):
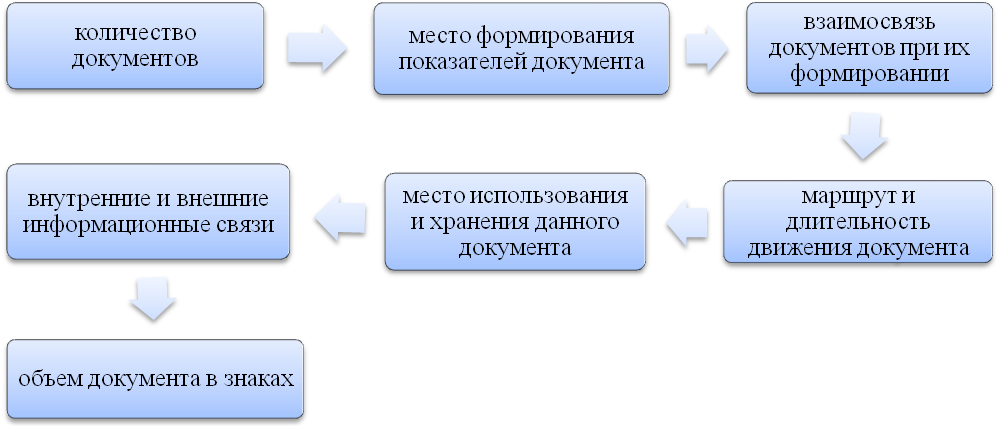
Рисунок 10 – Схема маршрута движения документов.
По результатам обследования устанавливается перечень задач управления, решение которых целесообразно автоматизировать, и очередность их разработки.
На этапе обследования следует классифицировать планируемые функции системы по степени важности. Один из возможных форматов представления такой классификации – MuSCoW.
Эта аббревиатура расшифровывается так: Must have – необходимые функции; Should have – желательные функции; Could have – возможные функции; Won’t have – отсутствующие функции.
Функции первой категории обеспечивают критичные для успешной работы системы возможности.
Реализация функций второй и третьей категорий ограничивается временными и финансовыми рамками: разрабатывается то, что необходимо, а также максимально возможное в порядке приоритета число функций второй и третьей категорий.
Последняя категория функций особенно важна, поскольку необходимо четко представлять границы проекта и набор функций, которые будут отсутствовать в системе.
Модели деятельности организации создаются в двух видах, (рис.11):
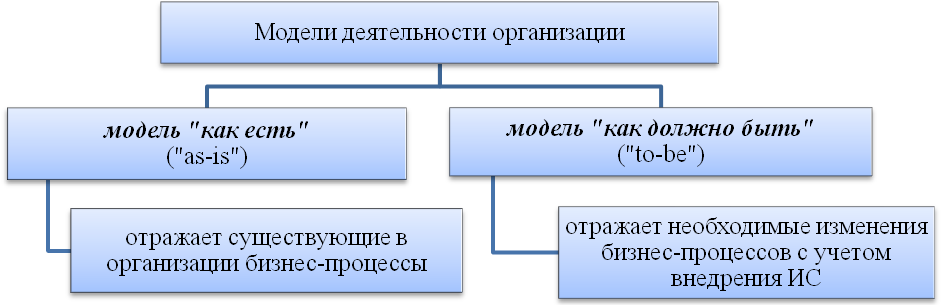
Рисунок 11. Виды моделей деятельности организации.
На этапе анализа необходимо привлекать к работе группы тестирования для решения следующих задач:
· получения сравнительных характеристик предполагаемых к использованию аппаратных платформ, операционных систем, СУБД, иного окружения;
· разработки плана работ по обеспечению надежности информационной системы и ее тестирования.
Привлечение тестировщиков на ранних этапах разработки является целесообразным для любых проектов. Если проектное решение оказалось неудачным и это обнаружено слишком поздно (на этапе разработки или, что еще хуже, на этапе внедрения в эксплуатацию), то исправление ошибки проектирования обходится очень дорого. Чем раньше группы тестирования выявляют ошибки в информационной системе, тем ниже стоимость сопровождения системы. Время на тестирование системы и на исправление обнаруженных ошибок следует предусматривать не только на этапе разработки, но и на этапе проектирования.
Для автоматизации тестирования следует использовать системы отслеживания ошибок (bug tracking). Это позволяет иметь единое хранилище ошибок, отслеживать их повторное появление, контролировать скорость и эффективность исправления ошибок, видеть наиболее нестабильные компоненты системы, а также поддерживать связь между группой разработчиков и группой тестирования (уведомления об изменениях по e-mail и т.п.). Чем больше проект, тем сильнее потребность в bug tracking.
Результаты обследования представляют объективную основу для формирования технического задания на информационную систему.
При разработке технического задания необходимо решить следующие задачи, (рис. 12):

Рисунок 12 – Последовательность решения задач при разработке ТЗ.
Типовые требования к составу и содержанию технического задания приведены в ГОСТ 34.602- 89 (http://www.docload.ru/Basesdoc/6/6565/index.htm ).
Эскизный проект (ГОСТ 2.119-73* http://doc-load.ru:82/SNiP/Data1/4/4568/index.htm ) предусматривает разработку предварительных проектных решений по системе и ее частям.
Выполнение стадии эскизного проектирования не является строго обязательной. Если основные проектные решения определены ранее или достаточно очевидны для конкретной ИС и объекта автоматизации, то эта стадия может быть исключена из общей последовательности работ.
Содержание эскизного проекта задается в ТЗ на систему. Как правило, на этапе эскизного проектирования определяются, (рис.13):

Рисунок 13 – Содержание ЭП.
По результатам проделанной работы оформляется, согласовывается и утверждается документация в объеме, необходимом для описания полной совокупности принятых проектных решений и достаточном для дальнейшего выполнения работ по созданию системы.
На основе технического задания (и эскизного проекта) разрабатывается технический проект ИС.
| Технический проект системы – это техническая документация, содержащая общесистемные проектные решения, алгоритмы решения задач, а также оценку экономической эффективности автоматизированной системы управления и перечень мероприятий по подготовке объекта к внедрению. |
На этом этапе осуществляется комплекс научно-исследовательских и экспериментальных работ для выбора основных проектных решений и расчет экономической эффективности системы. (табл. 3).
Таблица 3 – Содержание технического проекта.
| № пп | Раздел | Содержание |
| 1 | Пояснительная записка |
|
| 2 | Функциональная и организационная структура системы |
|
| 3 | Постановка задач и алгоритмы решения |
|
| 4 | Организация информационной базы |
|
| 5 | Альбом форм документов | |
| 6 | Система математического обеспечения |
|
| 7 | Принцип построения комплекса технических средств |
|
| 8 | Расчет экономической эффективности системы |
|
| 9 | Мероприятия по подготовке объекта к внедрению системы |
|
| 10 | Ведомость документов |
В завершение стадии технического проектирования производится разработка документации на поставку серийно выпускаемых изделий для комплектования ИС, а также определяются технические требования и составляются ТЗ на разработку изделий, не изготовляемых серийно, (рис. 14).
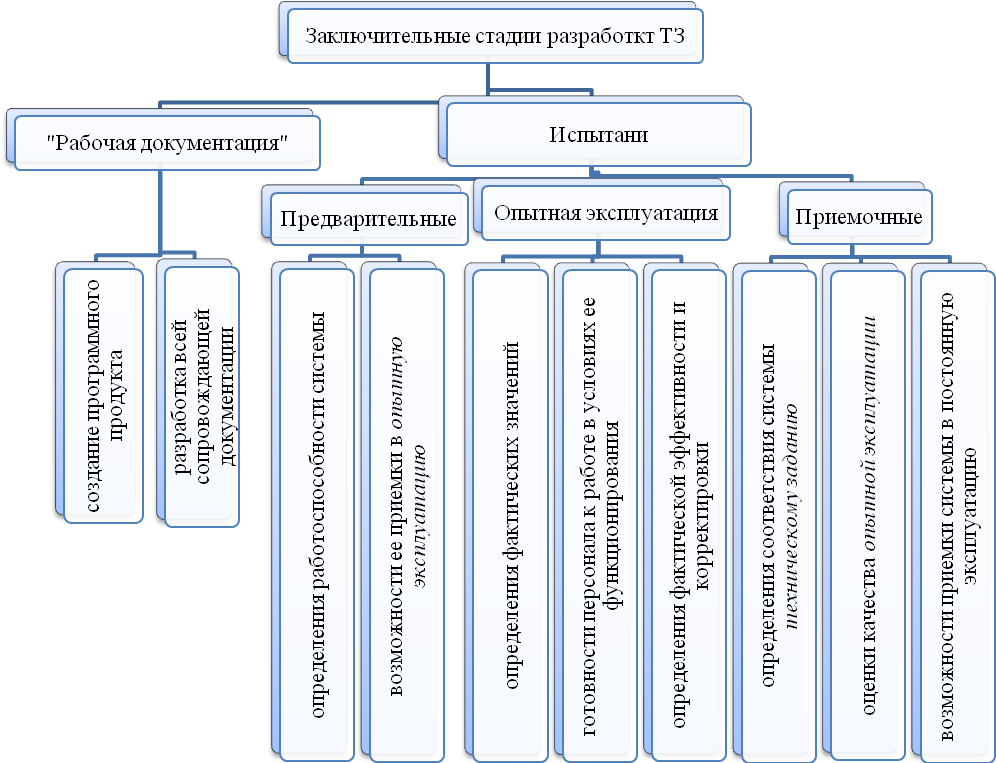
Рисунок 14 – Заключительные стадии разработки ТЗ.
На стадии “рабочая документация” осуществляется создание программного продукта и разработка всей сопровождающей документации. Документация должна содержать все необходимые и достаточные сведения для обеспечения выполнения работ по вводу ИС в действие и ее эксплуатации, а также для поддержания уровня эксплуатационных характеристик (качества) системы. Разработанная документация должна быть соответствующим образом оформлена, согласована и утверждена.
Для ИС, которые являются разновидностью автоматизированных систем, устанавливают следующие основные виды испытаний: предварительные, опытная эксплуатация и приемочные. При необходимости допускается дополнительно проведение других видов испытаний системы и ее частей.
В зависимости от взаимосвязей частей ИС и объекта автоматизации испытания могут быть автономные или комплексные. Автономные испытания охватывают части системы. Их проводят по мере готовности частей системы к сдаче в опытную эксплуатацию. Комплексные испытания проводят для групп взаимосвязанных частей или для системы в целом.
Для планирования проведения всех видов испытаний разрабатывается документ “Программа и методика испытаний”. Разработчик документа устанавливается в договоре или ТЗ. В качестве приложения в документ могут включаться тесты или контрольные примеры.
Предварительные испытания проводят для определения работоспособности системы и решения вопроса о возможности ее приемки в опытную эксплуатацию. Предварительные испытания следует выполнять после проведения разработчиком отладки и тестирования поставляемых программных и технических средств системы и представления им соответствующих документов об их готовности к испытаниям, а также после ознакомления персонала ИС с эксплуатационной документацией.
Опытную эксплуатацию системы проводят с целью определения фактических значений количественных и качественных характеристик системы и готовности персонала к работе в условиях ее функционирования, а также определения фактической эффективности и корректировки, при необходимости, документации.
Приемочные испытания проводят для определения соответствия системы техническому заданию, оценки качества опытной эксплуатации и решения вопроса о возможности приемки системы в постоянную эксплуатацию.
Типовое проектирование ИС
Типовое проектирование ИС предполагает создание системы из готовых типовых элементов. Основополагающим требованием для применения методов типового проектирования является возможность декомпозиции проектируемой ИС на множество составляющих компонентов (подсистем, комплексов задач, программных модулей и т.д.). Для реализации выделенных компонентов выбираются имеющиеся на рынке типовые проектные решения, которые настраиваются на особенности конкретного предприятия.
| Типовое проектное решение (ТПР)- это тиражируемое (пригодное к многократному использованию) проектное решение. |
Принятая классификация ТПР основана на уровне декомпозиции системы. Выделяются следующие классы ТПР, (рис.15).

Рисунок 15 – Классы ТПР.
Для реализации типового проектирования используются два подхода, (рис. 16):
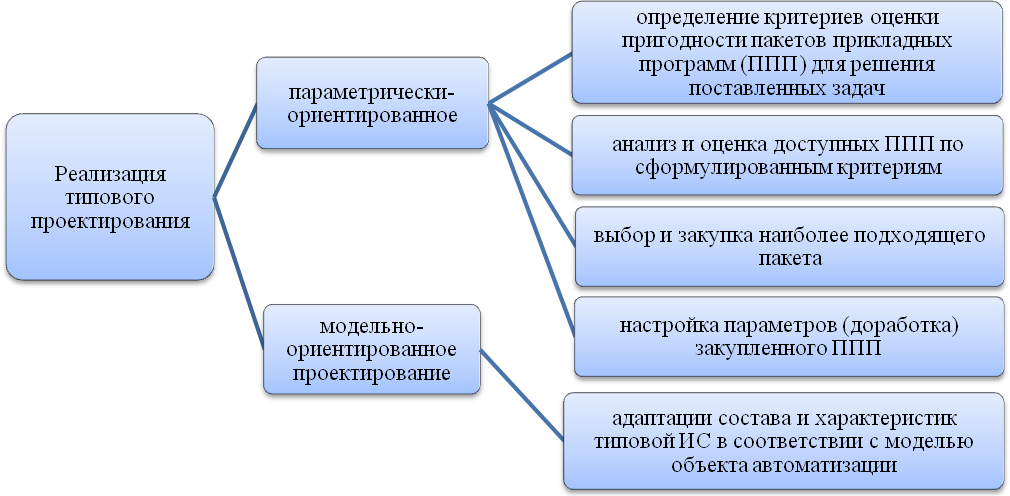
Рисунок 16 – Подходы при реализации ТП.
Параметрически-ориентированное проектирование включает следующие этапы: определение критериев оценки пригодности пакетов прикладных программ (ППП) для решения поставленных задач, анализ и оценка доступных ППП по сформулированным критериям, выбор и закупка наиболее подходящего пакета, настройка параметров (доработка) закупленного ППП.
Критерии оценки ППП делятся на следующие группы:
· назначение и возможности пакета;
· отличительные признаки и свойства пакета;
· требования к техническим и программным средствам;
· документация пакета;
· факторы финансового порядка;
· особенности установки пакета;
· особенности эксплуатации пакета;
· помощь поставщика по внедрению и поддержанию пакета;
· оценка качества пакета и опыт его использования;
· перспективы развития пакета.
Внутри каждой группы критериев выделяется некоторое подмножество частных показателей, детализирующих каждый из десяти выделенных аспектов анализа выбираемых ППП. Достаточно полный перечень показателей можно найти в литературе
Числовые значения показателей для конкретных ППП устанавливаются экспертами по выбранной шкале оценок (например, 10-балльной). На их основе формируются групповые оценки и комплексная оценка пакета (путем вычисления средневзвешенных значений). Нормированные взвешивающие коэффициенты также получаются экспертным путем.
Модельно-ориентированное проектирование заключается в адаптации состава и характеристик типовой ИС в соответствии с моделью объекта автоматизации.
Технология проектирования в этом случае должна обеспечивать единые средства для работы как с моделью типовой ИС, так и с моделью конкретного предприятия.
Типовая ИС в специальной базе метаинформации – репозитории – содержит модель объекта автоматизации, на основе которой осуществляется конфигурирование программного обеспечения. Таким образом, модельно-ориентированное проектирование ИС предполагает, прежде всего, построение модели объекта автоматизации с использованием специального программного инструментария (например, SAP Business Engineering Workbench (BEW), BAAN Enterprise Modeler). Возможно также создание системы на базе типовой модели ИС из репозитория, который поставляется вместе с программным продуктом и расширяется по мере накопления опыта проектирования информационных систем для различных отраслей и типов производства.
Репозиторий содержит базовую (ссылочную) модель ИС, типовые (референтные) модели определенных классов ИС, модели конкретных ИС предприятий.
Базовая модель ИС в репозитории содержит описание бизнес-функций, бизнес-процессов, бизнес-объектов, бизнес-правил, организационной структуры, которые поддерживаются программными модулями типовой ИС.
Типовые модели описывают конфигурации информационной системы для определенных отраслей или типов производства.
Модель конкретного предприятия строится либо путем выбора фрагментов основной или типовой модели в соответствии со специфическими особенностями предприятия (BAAN Enterprise Modeler), либо путем автоматизированной адаптации этих моделей в результате экспертного опроса (SAP Business Engineering Workbench).
Построенная модель предприятия в виде метаописания хранится в репозитории и при необходимости может быть откорректирована. На основе этой модели автоматически осуществляется конфигурирование и настройка информационной системы.
Бизнес-правила определяют условия корректности совместного применения различных компонентов ИС и используются для поддержания целостности создаваемой системы.
Модель бизнес-функций представляет собой иерархическую декомпозицию функциональной деятельности предприятия (подробное описание см. в разделе “Анализ и моделирование функциональной области внедрения ИС”).
Модель бизнес-процессов отражает выполнение работ для функций самого нижнего уровня модели бизнес-функций (подробное описание см. в разделе “Спецификация функциональных требований к ИС”). Для отображения процессов используется модель управления событиями (ЕРС – Event-driven Process Chain). Именно модель бизнес-процессов позволяет выполнить настройку программных модулей – приложений информационной системы в соответствии с характерными особенностями конкретного предприятия.
Модели бизнес-объектов используются для интеграции приложений, поддерживающих исполнение различных бизнес-процессов (подробное описание см. в разделе “Этапы проектирования ИС с применением UML”).
Модель организационной структуры предприятия представляет собой традиционную иерархическую структуру подчинения подразделений и персонала (подробное описание см. в разделе “Анализ и моделирование функциональной области внедрения ИС”).
Внедрение типовой информационной системы начинается с анализа требований к конкретной ИС, которые выявляются на основе результатов предпроектного обследования объекта автоматизации (см. раздел “Анализ и моделирование функциональной области внедрения ИС”). Для оценки соответствия этим требованиям программных продуктов может использоваться описанная выше методика оценки ППП. После выбора программного продукта на базе имеющихся в нем референтных моделей строится предварительная модель ИС, в которой отражаются все особенности реализации ИС для конкретного предприятия. Предварительная модель является основой для выбора типовой модели системы и определения перечня компонентов, которые будут реализованы с использованием других программных средств или потребуют разработки с помощью имеющихся в составе типовой ИС инструментальных средств (например, ABAP в SAP, Tools в BAAN).
Реализация типового проекта предусматривает выполнение следующих операций:
· установку глобальных параметров системы;
· задание структуры объекта автоматизации;
· определение структуры основных данных;
· задание перечня реализуемых функций и процессов;
· описание интерфейсов;
· описание отчетов;
· настройку авторизации доступа;
настройку системы архивирования.
§
Области применения баз данных
Автоматизированные информационные системы (АИС), основу которых составляют базы данных, появились в 60-х годах XX века в военной промышленности и бизнесе — там, где были накоплены значительные объемы полезных данных.
Первоначально АИС были ориентированы лишь на работу с информацией фактического характера — числовыми или текстовыми характеристиками объектов. Затем по мере развития техники появилась возможность обработки текстовой информации на естественном языке.
Принципы хранения разных видов информации в АИС аналогичны, но алгоритмы ее обработки определяются характером информационных ресурсов. Соответственно различают два класса АИС: документальные и фактографические, (рис.17) .
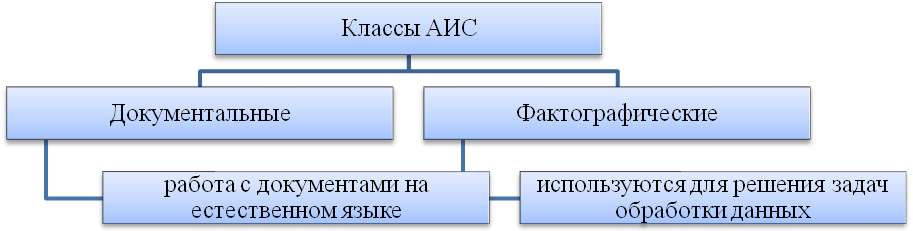
Рисунок 17 – Классы Автоматизирований ИС.
| Документальная база данных – база данных (сформированная структура), предназначенная для размещения записей, каждая из которых, отражая конкретный документ, содержит его библиографическое описание и, возможно, иную информацию о нем. |
Документальные АИС служат для работы с документами на естественном языке. Наиболее распространенный тип документальных АИС — информационно-поисковые системы, предназначенные для накопления и подбора документов, удовлетворяющих заданным критериям. Эти системы могут выполнять просмотр и подборку монографий, публикаций в периодике, сообщений пресс-агентств, текстов законодательных актов и т.д.
| Фактографическая база данных – база данных, содержащая информацию, относящуюся непосредственно к предметной области. |
Фактографические АИС оперируют фактическими сведениями, представленными в формализованном виде, и используются для решения задач обработки данных.
| Обработка данных — специальный класс решаемых на ЭВМ задач, связанных с вводом, хранением, сортировкой, отбором и группировкой записей данных однородной структуры. |
К задачам этого класса относятся: учет товаров в магазинах и на складах; начисление зарплаты; управление производством, финансами, телекоммуникациями и т.п.
Различают фактографические АИС оперативной обработки данных, подразумевающие быстрое обслуживание относительно простых запросов от большого числа пользователей, и фактографические АИС аналитической обработки, ориентированные на выполнение сложных запросов, требующих проведения статистической обработки исторических (накопленных за некоторый промежуток времени) данных, моделирования процессов предметной области и прогнозирования развития этих процессов.
Таким образом, АИС применяются в следующих областях:
• организация хранилищ данных;
• системы анализа данных;
• системы принятия решений;
• мобильные и персональные базы данных;
• географические базы данных;
• мультимедиа базы данных;
• распределенные информационные системы;
• базы данных для всемирной сети World Wide Web
Основные понятия и определения
В Государственном комитета по науке и технике (ГКНТ), изданных в 1982 г., приводятся следующие определения банка данных, базы данных и СУБД:
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений и рассматриваемой предметной области.
Предметная область – один или несколько объектов управления (или определенные их части), информация которых моделируется с помощью БД и используется для решения различных функциональных задач.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
В ней можно выделить:
· ядро СУБД, которое обеспечивает организацию ввода, обработки и хранения данных,
· компоненты, которые обеспечивают отладку системы, средства тестирования,
· утилиты, которые обеспечивают выполнение вспомогательных функций (например, ведение журнала статистики работы системы и др.).
Важной задачей СУБД является обеспечение независимости данных. Практически одна и одна и та же СУБД может быть использована для ведения абсолютно разных файлов, которые используются для решения разноплановых, не связанных между собою задач управления. Все функции СУБД можно объединить в такие группы:
1. Управление данными. Задачами управления данных является подготовка данных и их контроль, внесение данных в базу, структуризация данных, обеспечение целостности, секретности данных.
2. Доступ к данным. Поиск и селекция данных, преобразование данных в форму, удобную для дальнейшего использования.
3. Организация и ведение связи с пользователем. Ведение диалога, выдача диагностических сообщений об ошибках в работе по БД и т.д.
Для обработки запросов к БД разрабатывают программы, которые составляют прикладное программное обеспечение. Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистема складского учета, четвертое приложение посвящено планированию производственного процесса. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
§
Языковые средства СУБД, необходимые для описания данных, организации общения и выполнения процедур поиска и различных преобразований данных. Классификация языковых средств БнД, разработана американским комитетом CODASYL по проектированию и созданию БД, (рис.18).
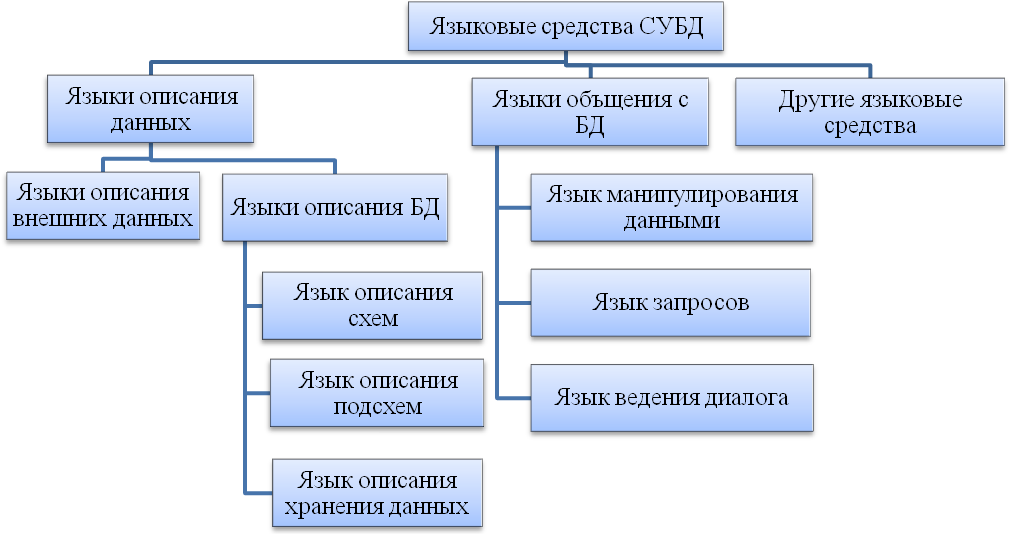
Рисунок 18 – Классификация языковых средств БнД.
Схема имеет общий характер и ориентирована на различные СУБД. Однако не каждая СУБД, которая сейчас используется на практике и распространена на рынке программных продуктов, имеет весь набор указанных языковых средств.
Язык описания данных (DDL – Data Definition Language), предназначен для описания данных на разных уровнях абстракции: внешнем, логическом и внутреннем. Исходя из предложений CODASYL, языки описания данных на логическом (концептуальном) и внутреннем уровнях независимые и разные. Однако в большинстве промышленных СУБД языки не делится на два отдельных языка описания логической и физической организации данных, а существует единый язык, которая еще называется языком описания схем. В известных и широко используемых на практике СУБД семьи dBASE применяется единый язык описания данных. Он предназначен для представления данных на логическом и физическом уровнях. Этот язык имеет свой синтаксис: например, имя файла не должно превышать восьми символов, а имя поля – десяти; при этом каждое имя может начинаться с буквы, поля календарной даты обозначаются символом D (DATA), символьные поля — С (CHARACTER), числовые — N (NUMERIC), логические — L (LOGICAL), примечаний — М (MEMO).
Описание всех имен, типов и размеров полей сохраняется в памяти вместе с данными; эти структуры в случае необходимости можно просмотреть и исправить. Если логический и физический уровни отделены, то в состав СУБД может входить язык описания сохранения данных. В некоторых СУБД используется еще язык описания подсхем, который нужен для описания части БД, которая отражает информационные потребности отдельного пользователя или прикладной программы. В составе СУБД типа dBASE такой язык не используется.
Язык описания данных на внешнем уровне используется для описания требований пользователей и прикладных программ и создания инфологической модели БД. Этот язык не имеет ничего общего с языками программирования. Так, языковым средством, которое используются для инфологического моделирования, является обычный естественный язык или его подмножество, а также язык графов и матриц.
Язык манипулирования данными (DML – Data Manipulation Language) используется для обработки данных, их преобразований и написания программ. DML может быть базовым или автономным.
Базовый язык DML — это один из традиционных языков программирования (BASIC, C, FORTRAN и др.). Системы, которые используют базовый язык, называют открытыми. Использование базовых языков как языков описания данных сужает круг лиц, которые могут непосредственно обращаться к БД, поскольку для этого нужно знать язык программирования. В таких случаях для упрощения общения конечных пользователей с БД предполагается язык ведения диалога, который значительно проще для овладения, чем язык программирования.
Автономный язык DML — это собственный язык СУБД, который дает возможность выполнять различные операции с данными. Системы с собственным языком называют закрытыми.
В современных СУБД для упрощения процедур поиска данных в БД предусмотрен язык запросов. Наиболее распространенными языками запросов являются SQL и QBE.
Язык запросов SQL (Structured Query Language – структурированный язык запросов) был создан фирмой IBM в рамках работы над проектом построения системы управления реляционными базами данных в начале 70-х годов. Американский национальный институт стандартов (ANSI) положил этот язык в основу стандарта языков реляционных баз данных, принятого Международной организацией стандартов (ISO). Ядром существующего стандарта SQL-86, которые часто называют SQL-2 или SQL-92, являются функции, реализованные практически во всех известных коммерческих реализациях языка, а полный стандарт вмещает такие усовершенствования, которые некоторые разработчики будут должны еще реализовать.
Кроме стандарта SQL-86 существует коммерческий стандарт языка SQL, разработанный консорциумом производителей баз данных SQL Access Group. Эта группа создала такой вариант языка, который используется большинством систем и дает возможность им «понимать» одна другую.
Был разработан стандартный интерфейс языка CLI (Common Language Interface) для всех основных вариантов языка SQL. Этот интерфейс, формализованный фирмой Microsoft, получил название ODBC (Open DataBase Connectivity — открытый доступ к данным). ODBC — это интерфейс доступа к данным, которые сохраняются под управлением разных СУБД. ODBC имеет целый набор драйверов, с помощью которых одна СУБД может работать с данными других систем.
Язык запросов QBE (Query By Example) — это реализация запросов по образцу в виде таблиц. Для определения запроса к БД пользователь должен заполнить предоставленную системой таблицу QBE и определить в ней критерии поиска и выбора данных.
Пользователи банков данных
Как любой программно-организационно-технический комплекс, банк данных существует во времени и в пространстве. Он имеет определенные стадии своего развития, (рис. 19):
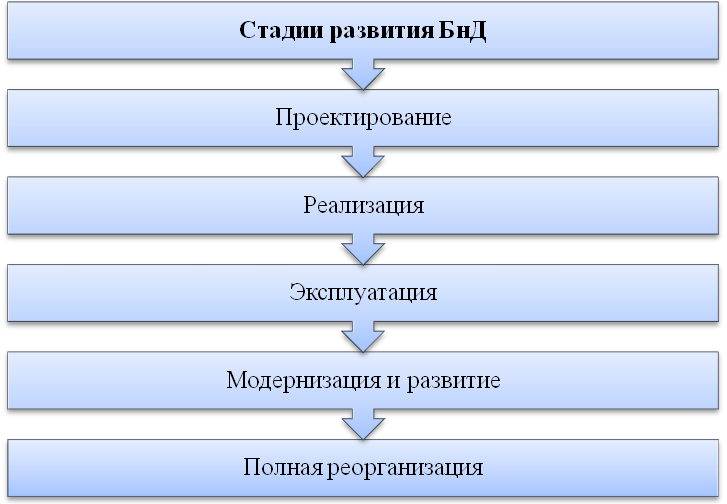
Рисунок 19 – Стадии развития БнД.
На каждом этапе своего существования с банком данных связаны разные категории пользователей.
Определим основные категории пользователей и их роль в функционировании банка данных:
1. Конечные пользователи. Это основная категория пользователей, в интересах которых и создается банк данных.
2. Администраторы банка данных. Это группа пользователей, которая на начальной стадии разработки банка данных отвечает за его оптимальную организацию с точки зрения одновременной работы множества конечных пользователей, на стадии эксплуатации отвечает за корректность работы данного банка информации и многопользовательском режиме. На стадии развития и реорганизации эта группа пользователей отвечает за возможность корректной реорганизации банка без изменения или прекращения его текущей эксплуатации.
3. Разработчики и администраторы приложений. Это группа пользователей, которая функционирует во время проектирования, создания и реорганизации банка данных. Администраторы приложений координируют работу разработчиков при разработке конкретного приложения или группы приложений, объединенных в функциональную подсистему. Разработчики конкретных приложений работают с той частью информации из базы данных, которая требуется для конкретного приложения.
В составе группы администратора БД должны быть:
1) системные аналитики;
2) проектировщики структур данных и внешнего по отношению к банку данных информационного обеспечения;
3) проектировщики технологических процессов обработки данных;
4) системные и прикладные программисты:
5) операторы и специалисты по техническому обслуживанию.
Если речь идет о коммерческом банке данных, то важную роль здесь играют специалисты по маркетингу.
§
Самым жизнеспособным способы реализации СУБД оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, (рис.20).
Рисунок 20 – Трехуровневая модель системы управления базой данных, предложенная ANSI.
1. Уровень внешних моделей— самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
2. Концептуальный уровень— центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
3. Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем. Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных.
Классификация банков данных
| Банки данных — это очень сложная система, которую можно классифицировать по целому спектру признаков, касающихся как банка в целом, так и отдельных его компонентов. |
По назначению БнД бывают, (рис.21):
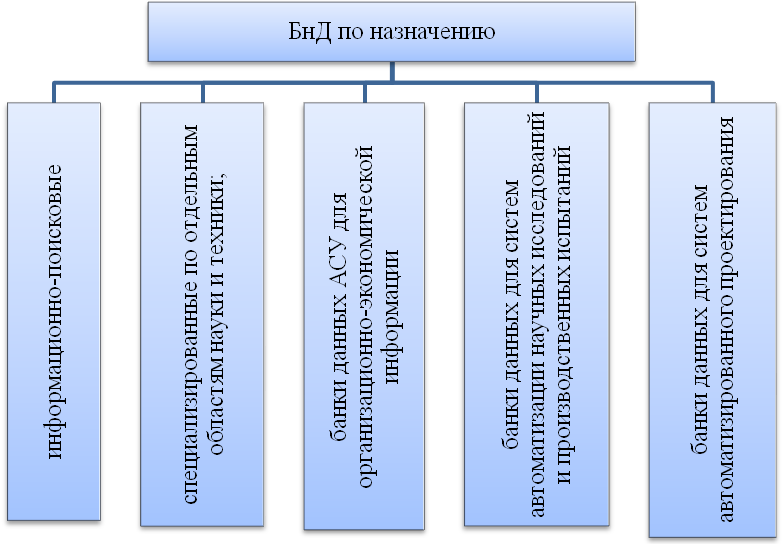
Рисунок 21 – Банки данных по назначению.
Также Банки Данных классифицируют, (рис. 22):
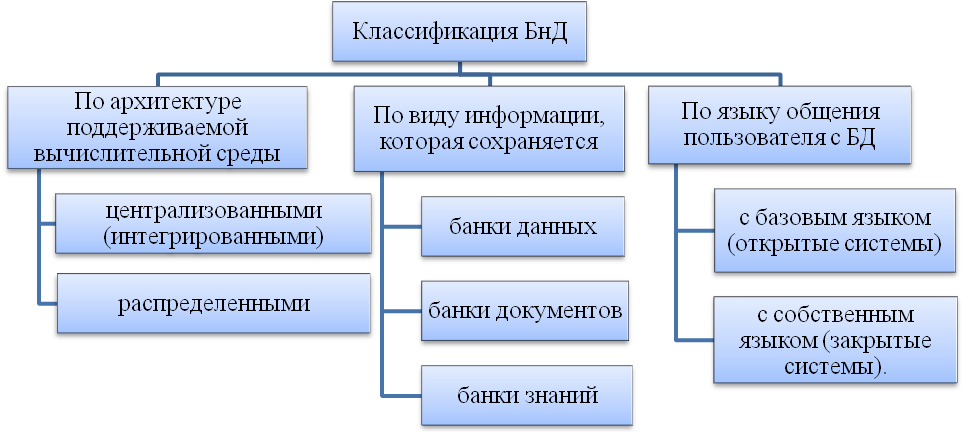
Рисунок 22 – Классификация Банков Данных.
В открытых системах языковым средством общения с БД один из языков программирования, например C, Pascal. В таких системах для общения с БД нужен посредник, то есть программист, который владеет избранным языком программирования.
Закрытые системы имеют собственный язык общения. Он, как правило, намного проще, чем язык программирования. Поэтому в таких системах не нужен посредник-программист для общения с БД. Сами пользователи, которые имеют соответствующую подготовку, смогут работать с БД.
Центральным понятием в области баз данных является понятие модели.
| Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними. |
В соответствии с рассмотренной ранее трехуровневой архитектурой приходится сталкиваться с понятием модели данных по отношению к каждому уровню, (рис. 23).
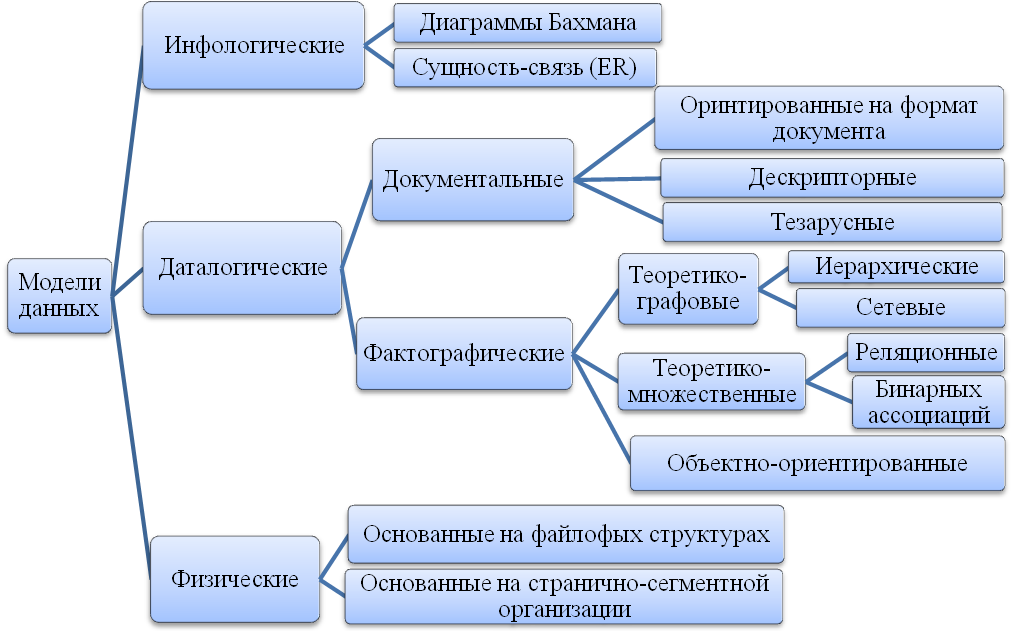
Рисунок 23 – Модели данных.
Инфологические модели используются на ранних стадиях проектирования баз данных для формального описания предметной области. Они содержат информацию о классах объектов, их свойствах и взаимосвязях, описания структур данных без привязки к какой-либо конкретной СУБД. Инфологические (или семантические) модели отражают в естественной и удобной для разработчиков и других пользователей форме информацию о предметной области в процессе разработки структуры будущей базы данных.
Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных списков. Кроме того, современные СУБД широко используют страничную организацию данных. В этом случае база данных представлена минимальным количеством файлов, а задачи поиска, чтения и записи данных выполняет сама СУБД, а не операционная система. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Даталогические модели являются моделями концептуального уровня и разрабатываются для конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, ориентированные на формат документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. Гораздо более простой и удобный, чем SGML, язык HTML (HyperText Markup Language – язык разметки гипертекста) позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. В настоящее время все большую популярность приобретает язык XML (eXtensible Markup Language – расширяемый язык разметки), позволяющий описывать документы произвольной структуры и содержания.
Тезаурусные модели основаны на принципе организации словарей. Они содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескриптпорные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имеет жесткую структуру и описывает документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной базе данных. Например, для БД, содержащей описание патентов, дескриптор содержит название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных ведется исключительно по дескрипторам, то есть по тем параметрам, которые характеризуют патент, а не по самому тексту патента.
Теоретико-графовые модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. Математической основой таких моделей является теория графов.
§
| Проектирование баз данных — это итерационный, многоэтапный процесс принятия обоснованных решений в процессе анализа информационной модели предметной области, требований к данным со стороны прикладных программистов и пользователей, синтеза логических и физических структур данных, анализа и обоснования выбора программных и аппаратных средств. |
Этапы проектирования баз данных связаны с многоуровневой организацией данных. Рассматривая вопрос проектирования баз данных, будем придерживаться такого многоуровневого представления данных: внешнего, инфологического, логического (даталогического) и внутреннего.
Такое представление уровней данных не единственное. Существуют и другие варианты многоуровневого представления данных. Так, в соответствии с предложениями исследовательской группы по системам управления данными Американского национального института стандартов ANSI/X3/SPARC, а также CODASYL (Conference on Data Systems Languages), как правило, выделяется три уровня представления данных:
1) внешний уровень (с точки зрения конечного пользователя и прикладного программиста),
2) концептуальный уровень (с точки зрения СУБД),
3) внутренний уровень (с точки зрения системного программиста).
В соответствии с этой концепцией внешний уровень это часть (подмножество) концептуальной модели, необходимая для реализации какого-либо запроса или прикладной программы. То есть, если концептуальная модель выступает как схема, поддерживаемая конкретной СУБД, то внешний уровень — это некоторая совокупность подсхем, необходимых для реализации конкретной прикладной программы или запроса пользователя.
Существует также другая точка зрения, в соответствии с которой под внешним уровнем понимают более общие понятия, связанные с изучением и анализом информационных потоков предметной области и их структуризацией. Некоторые авторы вводят вспомогательный уровень (промежуточный между внешним и даталогическим уровнями), который называется инфологическим. Он может выступать как самостоятельный или быть составной частью внешнего уровня. Такая концепция более целесообразна с точки зрения понимания процесса проектирования БД.
Поэтому будем рассматривать инфологический уровень как самостоятельный уровень представления данных. Внешний уровень в этом случае выступает как отдельный этап проектирования, на котором изучается все внемашинное информационное обеспечение, то есть формы документирования и представления данных, а также внешняя среда, в которой будет функционировать банк данных с точки зрения методов фиксации, сбора и передачи информации в базу данных.
При проектировании БД на внешнем уровне необходимо изучить функционирование объекта управления, для которого проектируется БД, всю первичную и выходную документацию с точки зрения определения того, какие именно данные необходимо сохранять в базе данных. Внешний уровень это, как правило, словесное описание входных и выходных сообщений, а также данных, которые целесообразно сохранять в БД. Описание внешнего уровня не исключает наличия элементов дублирования, избыточности и несогласованности данных. Поэтому для устранения этих аномалий и противоречий внешнего описания данных выполняется инфологическое проектирование. Инфологическая модель является средством структуризации предметной области и понимания концепции семантики данных. Инфологическую модель можно рассматривать в основном как средство документирования и структурирования формы представления информационных потребностей, которая обеспечивает непротиворечивое общение пользователей и разработчиков системы.
Все внешние представления интегрируются на инфологическом уровне, где формируется инфологическая (каноническая) модель данных, которая не является простой суммой внешних представлений данных.
Инфологический уровень представляет собой информационно-логическую модель (ИЛМ) предметной области, из которой исключена избыточность данных и отображены информационные особенности объекта управление без учета особенностей и специфики конкретной СУБД. То есть инфологическое представление данных ориентированно преимущественно на человека, который проектирует или использует базу данных.
Логический (концептуальный) уровень построен с учетом специфики и особенностей конкретной СУБД. Этот уровень представления данных ориентирован больше на компьютерную обработку и на программистов, которые занимаются ее разработкой. На этом уровне формируется концептуальная модель данных, то есть специальным способом структурированная модель предметной области, которая отвечает особенностям и ограничениям выбранной СУБД. Модель логического уровня, поддерживаемую средствами конкретной СУБД, называют еще даталогической.
Инфологическая и даталогическая модели, которые отображают модель одной предметной области, зависимы между собой. Инфологическая модель может легко трансформироваться в даталогическую модель.
Внутренний уровень связан с физическим размещением данных в памяти ЭВМ. На этом уровне формируется физическая модель БД, которая включает структуры сохранения данных в памяти ЭВМ, в т.ч. описание форматов записей, порядок их логического или физического приведения в порядок, размещение по типам устройств, а также характеристики и пути доступа к данным.
От параметров физической модели зависят такие характеристики функционирования БД: объем памяти и время реакции системы. Физические параметры БД можно изменять в процессе ее эксплуатации с целью повышения эффективности функционирование системы. Изменение физических параметров не предопределяет необходимости изменения инфологической и даталогической моделей.
Схема взаимосвязи уровней представления данных в БД изображена на рис. 24. В соответствии с этими уровнями проектируется БД. Проектирование БД— это сложный и трудоемкий процесс, который требует привлечения многих высококвалифицированных специалистов. От того, насколько квалифицированно спроектирована БД, зависят производительность информационной системы и полнота обеспечения функциональных потребностей пользователей и прикладных программ. Неудачно спроектированная БД может усложнить процесс разработки прикладного программного обеспечения, обусловить необходимость использования более сложной логики, которая, в свою очередь, увеличит время реакции системы, а в дальнейшем может привести к необходимости перепроектирования логической модели БД. Реструктуризация или внесение изменений в логическую модель БД это очень нежелательный процесс, поскольку он является причиной необходимости модификации или даже перепрограммирование отдельных задач.
Все работы, которые выполняются на каждом этапе проектирования, должны интегрироваться со словарем данных. Каждый этап проектирования рассматривается как определенная последовательность итеративных процедур, в результате которых формируется определенная модель БД.
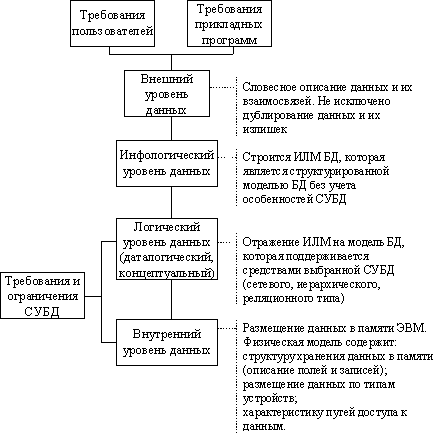
Рисунок 24 – Схема взаимосвязи уровней представление данных в БД
Внешний уровень — подготовительный этап инфологического проектирования
Целью проектирования на внешнем уровне является разработка внемашинного информационного обеспечения, которое включает систему входной (первичной) документации, характеризующую определенную предметную область, систему классификации и кодирования технико-экономической информации, а также перечень соответствующих выходных сообщений, которые нужно формировать с помощью БнД.
Существуют два подхода к проектированию баз данных на внешнем уровне: «от предметной области» и «от запроса».Подход «от предметной области» состоит в том, что формируется внешнее информационное обеспечение всей предметной области без учета потребностей пользователей и прикладных программ. Иногда этот подход называют еще объектным или непроцессным.
При подходе «от запроса» основным источником информации о предметной области есть изучение запросов пользователей и потребностей прикладных программ. Этот подход также называется процессным или функциональным. При таком подходе БД проектируется для выполнения текущих задач управления без учета возможности расширение системы и возникновение новых задач управление.
Преимущество подхода «от предметной области» это его объективность, системность при отображении ПО и стойкость информационной модели, возможность реализации большого количества прикладных программ и запросов, в том числе незапланированных при создании БД. Недостатком этого подхода является значительный объем работ, которые необходимо выполнить при определении информации. подлежащей хранению в БД, что, соответственно, усложняет и увеличивает срок разработки проекта.
Функциональный подход ориентирован на реализацию текущих требований пользователей и прикладных программ без учета перспектив развития системы. При его использовании могут возникнуть сложности в агрегации требований разных пользователей и прикладных программ. Тем не менее, при таком подходе значительно уменьшается трудоемкость проектирования, и поэтому возможно создать систему с высокими эксплуатационными характеристиками.
Однако взятый в отдельности любой из этих методов не может дать достаточно информации для проектирования рациональной структуры БД. Поэтому при проектировании БД целесообразно совместно использовать эти два подхода. Если схематично представить процесс проектирования БД на внешнем уровне, то он состоит из таких работ.
1. Определение функциональных задач предметной области, которые подлежат автоматизированному решению. Поскольку основной целью создания БД есть обеспечение информацией функций обработки данных, то, прежде всего, необходимо изучить все функции предметной области (объекта управления), для которой разрабатывается база данных, и проанализировать их особенности. Функции и функциональные особенности объекта управление необходимо изучать в неразрывной связи с изучением функциональных требований к данным со стороны будущих пользователей информационной системы. Изучение и анализ предусматривают выявление информационных потребностей и определения информационных потоков. Эти работы можно выполнять обследованием предметной области и анкетированием ее сотрудников. Результатом такого изучения может быть перечень функциональных задач, которые должны решаться автоматизированным способом с использованием БД.
2. Изучение и анализ оперативных первичных документов. Изучив функции и определив перечень функциональных задач, которые подлежат автоматизированному решению, переходят к изучению оперативных документов, которые используются на входе каждой задачи или их комплекса. Изучив и проанализировав все оперативные документы (как внешние, так и внутренние), которые используются на входе каждой задачи, определяют, какие реквизиты этих документов нужно сохранять в БД.
3. Изучение нормативно-справочных документов. На третьем шаге изучают и анализируют всю нормативно-справочную документацию. К такой документации принадлежат различные классификаторы, сметы, договоры, нормативы, законодательные акты по налоговой политике, плановая документация и т.п. Распределение и отдельный анализ оперативной и нормативно-справочной информации обусловлены технологически. В базы данных различаются технологии создания и ведения файлов условно-постоянной информации, размещенной в нормативно-справочной документации, и файлов оперативной информации.
4. Изучение процессов преобразования входных сообщений в выходные. Прежде всего, изучаются все выходные сообщения, которые выдаются на печать или на экран и сохраняются в виде выходных массивов на МД. Это необходимо для того, чтобы определить, которые из атрибутов входных сообщений нужно сохранять в БД для получения выходных сообщений. Кроме того, на этом этапе определяются те показатели, которые получают во время решения задачи в результате выполнения определенных вычислений. По каждому расчетному показателю следует определить алгоритм его формирования и убедиться в том, что этот показатель можно получить на основе атрибутов оперативной и нормативно-справочной информации, которые были определены на втором и третьем шагах. Если определенных данных не хватает для полного выполнения расчетов, необходимо возвратиться назад, провести дополнительное исследование и определить, где и каким способом можно получить атрибуты, которых не хватает.
Кроме того, нужно определиться, какие из расчетных показателей целесообразно сохранять в БД. Показатели, полученные расчетным путем, как правило, в БД не сохраняются. Исключением являются случаи, когда расчетный показатель нужно использовать для решения других задач или для данной задачи, но в следующие календарные периоды.
При проведении проектных работ на внешнем уровне надо учитывать то, что для выполнения определенных функций в БД необходимо сохранять дополнительные данные, которые не отображены в документах (данные календаря, статистические данные и т.п.). Обобщенная схема процесса изучения документов и данных при проектировании на внешнем уровне изображена на рис. 25.
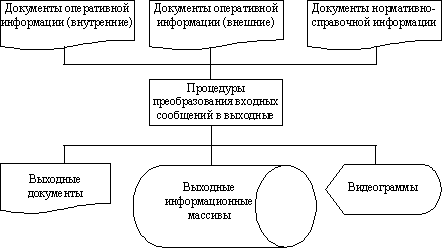
Рисунок 25 – Обобщенная схема процесса проектирование на внешнем уровне
Такое изучение необходимо провести по каждой функциональной задаче или их комплексу, которые будут решаться с помощью БД.
Результатом проектирования на внешнем уровне будет перечень атрибутов (реквизитов) оперативной и условно-постоянной информации, которые необходимо хранить в БД, с указанием источников их получения и формы представления. Однако этот перечень не исключает возможности существования в нем избыточности, дублирования, несогласованности и других недостатков. Поэтому на этом процесс не заканчивается, а осуществляется переход к этапу инфологического проектирования.
§
Основными составными элементами инфологической модели являются сущности (информационные объекты), связи между ними и их атрибуты (свойства).
Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей. Атрибуты используются для определения того, какая информация должна быть собрана о сущности.
Ключ – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся. Для сущности Расписание ключом является атрибут Номер_рейса или набор: Пункт_отправления, Время_вылета и Пункт_назначения (при условии, что из пункта в пункт вылетает в каждый момент времени один самолет).
Связь– ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.
Требования и подходы к инфологическому проектированию
Целью инфологического проектирования есть создание структурированной информационной модели ПО, для которой будет разрабатываться БД. При проектировании на инфологическом уровне создается информационно-логическая модель (ИЛМ), которая должна отвечать таким требованиям:
· обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных;
· корректность схемы БД, то есть адекватное отображение моделированной ПО;
· простота и удобство использования на следующих этапах проектирования, то есть ИЛМ может легко отображаться на модели БД, которые поддерживаются известными СУБД (сетевые, иерархические, реляционные и др.);
· ИЛМ должна быть описана языком, понятным проектировщикам БД, программистам, администратору и будущим пользователям.
Суть инфологического моделирования состоит в выделении сущностей (информационных объектов ПО), которые подлежат хранению в БД, а также в определении характеристик (атрибутов) объектов и взаимосвязей между ними.
Существует два подхода к инфологическому проектированию: анализ объектов и синтез атрибутов. Подход, который базируется на анализе объектов, называется нисходящим, а на синтезе атрибутов — восходящим.
Фактографические информационные системы
Фактографические АИС накапливают и хранят данные в виде множества экземпляров одного или нескольких типов структурных элементов (информационных объектов). Каждый из таких экземпляров структурных элементов или некоторая их совокупность отражают сведения по какому-либо факту, событию и т. д., отделенному (вычлененному) от всех прочих сведений и фактов. Структура каждого типа информационного объекта состоит из конечного набора реквизитов, отражающих основные аспекты и характеристики сведений для объектов данной предметной области. К примеру, фактографическая АИС, накапливающая сведения по лицам, каждому конкретному лицу в базе данных ставит в соответствие запись, состоящую из определенного набора таких реквизитов, как фамилия, имя, отчество, год рождения, место работы, образование и т. д. Комплектование информационной базы в фактографических АИС включает, как правило, обязательный процесс структуризации входной информации из документального источника. Структуризация при этом осуществляется через определение (выделение, вычленение) экземпляров информационных объектов определенного типа, информация о которых имеется в документе, и заполнение их реквизитов.
§
В архитектуре подсистемы представления и обработки информации фактографических АИС можно выделить различные уровни представления информации, отображенные на рис. 1
| Локальное представление пользователей о предметной области |
| Модель организацииданных СУБД |
| Схема БД (логическая структура) |
| Информационно-логическая схема, (модель), предметной области, (формальное представление об объектах и отношениях предметной области. |
| Концептуальная модель использования информационных систем |
| Информационные потребности абонентов |
| Информационные массивы (файлы данных) |
Рисунок 26 – Уровни представления информации в АИС.
Начальный уровень определяется локальными представлениями о предметной области пользователей-абонентов информационной системы и их представлениями о своих информационных потребностях.
На основе анализа этих представлений определяется информационно-логическая или сокращенно инфологическаясхема предметной области, подлежащей отображению информационной системой, и концептуальная модель использования информационной системы. Инфологическая схема представляет собой формализованное представление (описание) объектов и отношений фрагмента действительности.
Наиболее часто формализация представлений о предметной области осуществляется в рамках модели «объекты-связи» (так называемая ER-людель — от англ. Entity Relationship). При этом под информационным объектом в общем плане понимается некоторая сущность фрагмента действительности, например организация, документ, сотрудник, место, событие и т. д. В предметной области выделяются различные типы объектов, представляемые в информационной системе в каждый момент времени конечным набором экземпляров данного типа. Каждый тип объекта включает (идентифицируется) присущий ему набор атрибутов (свойств, характерных признаков, параметров).
Атрибут представляет логически неделимый элемент структуры информации, характеризующийся множеством атомарных значений. Для примера можно привести атрибут «Имя» объекта типа «Лицо», который характеризуется множеством всех возможных имен, и атрибут «Текст» объекта типа «Документ», который характеризуется множеством средств смыслового выражения в определенном национальном языке.Экземпляр объекта образуется совокупностью конкретных значений атрибутов данного типа объекта. Один или некоторая группа атрибутов объекта данного типа могут исполнять роль ключевого атрибута, по которому идентифицируются (различаются) конкретные экземпляры объектов. К примеру, для объектов типа «Лицо» ключом может являться совокупность атрибутов «Фамилия», «Имя», «Отчество» или один атрибут, выражающий номер паспорта (удостоверения личности).Различные типы объектов и различные экземпляры одного типа объекта могут быть охвачены определенными отношениями, которые в рамках ER-модели выражаются т. н. связями. Так, например, объекты «Сотрудник» и «Организация» могут быть охвачены отношением «Работа», т. е. связаны этим отношением. При этом связи могут быть двух типов — иерархические, или, иначе говоря, структурные (владелец-подчиненный) и одноуровневые, например, родственная связь «Брат-сестра» между двумя экземплярами объекта типа «Лицо» (в отличие от иерархической родственной связи—«Отец-сын»). Объекты-владельцы иерархических связей-отношений иногда называют структурными объектами, в противовес простым объектам, которые таковыми не являются (не являются владельцами).Структурные и одноуровневые связи (отношения), в свою очередь, по признаку множественности могут быть трех типов — «один-к-одному» (например, отношение «Лицо-Паспорт», имея в виду под «Паспортом» не атрибут объекта Лицо, а самостоятельный объект, состоящий из атрибутов «Номер», «Вид паспорта», «Владелец», «Место выдачи», «Дата выдачи» и т. д.), «один-ко-многим» (например, отношение «Подразделение-Сотрудник», имея в виду, что в одном подразделении мо-жет работать много сотрудников, но каждый сотрудник работает только в одном подразделении) и «многие-ко-многим» (например, отношение «Лицо-Документ», имея в виду, что один человек может быть автором, или иметь какое-либо другое отношение ко многим документам, и, в свою очередь, один документ может иметь много авторов.Помимо этого информационные потребности абонентов информационной системы могут включать также и оперирование опосредованными (т. е. косвенными, непрямыми, ассоциативными) связями. Примерами таких непрямых связей является совместная работа нескольких человек на одном предприятии (подразделении). Прямая непосредственная связь в данном случае, как правило, устанавливается только между объектами «Лицо» и «Организация», но не между различными экземплярами объекта «Лицо».Одним из способов представления формализованного описания предметной области информационной системы в рамках модели «объекты-связи» является использование техники специальных диаграмм, которая была предложена известным американским специалистом в области баз данных Ч. Бахманом. В диаграммах Бахмана объекты (сущности) представляются вершинами некоторого математического графа, а связи —дугами графа. Виды и свойства связей-отношений объектов отображаются направленностью, специальным оформлением дуг и расположением вершин графа.В качестве примера можно привести инфологическую схему предметной области сведений информационной системы, предназначенной для накопления данных о научной работе в каком-либо учебном или исследовательском учреждении (см. рис. 27).
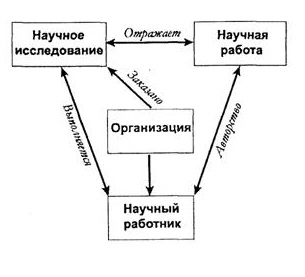
Рис. 27. Мифологическая схема предметной области информационной системы со сведениями о научной работе
На приведенном рисунке однонаправленность дуг означает структурность связи «владелец-подчиненный», двунаправленность дуг означает одноуровневые связи, двойные стрелки означают множественность отношения «один-ко-многим», дву-направленность двойных стрелок означает одноуровневые отношения «многие-ко-многим».Одним из недостатков использования ER-диаграмм Бахмана для описания формализованных схем (моделей) предметных областей информационных систем является их статичность, не позволяющая наглядно и непосредственно отображать процессы, в которые вовлечены сущности и которым подвержены отношения (связи). Отчасти подобные проблемы преодолеваются введением дополнительных сущностей, выражающих собственно процессы и ситуации — событие, действие, момент времени. Аналогичным образом в некоторых случаях вводятся пространственные сущности для адекватного представления сущностей и отношений предметной области—маршрут, место, населенный пункт, здание, элемент здания, зона и т. д.Вторым уровнем представления информации в информационной системе (см. рис. 1) является схема базы дачных, (называемая еще логической структурой данных), представляющая описание средствами конкретной СУБД инфологической схемы предметной области (информационные объекты, реквизиты, связи).Совокупность средств и способов реализации схемы базы данных в конкретной СУБД составляет модель организации данных.Схема базы данных содержит также ограничения целостности данных. Ограничения целостности представляют собой набор установок и правил по типам, диапазонам, соотношениям (и т. д.) значений атрибутов объектов, характеристик и особенностей связей между объектами. К примеру, диапазон значения атрибута «Дата рождения» объекта лицо не может выходить за рамки текущей даты, значение атрибута «Дата приобретения» объекта «Имущество» не может быть позднее значения атрибута «Дата продажи», значение атрибута «Количество» объекта «Материал» не должно быть меньше минимально необходимого на складе и т. п. Ограничения целостности данных лежат в основе контроля корректности информации при ее вводе в систему и периодического контроля наличия смысловых и других ошибок в базе данных после проведения операций добавления, удаления и изменения данных.Третий и самый «низкий» уровень представления информации в фактографических информационных системах выражается внутренней схемой базы данных, определяющей структуру организации и особенности хранения информационных массивов, в которых и находятся собственно сами данные (см. рис. 1).Более конкретные особенности представления и организации данных определяются конкретным типом и особенностями СУБД, используемой для создания фактографической информационной системы.
§
Для построения системы должен использоваться минимальный набор неизменяемых компонент, если компоненты должны быть структурированы и связаны единым способом построения. Для оценки качества классов и объектов, выделяемых в системе, предлагаются следующие пять критериев:
· -взаимосвязанность (зацепление), степень глубины связи между отдельными модулями;
· -связность, степень взаимодействия между элементами отдельного модуля (наиболее предпочтительна наибольшая связанность);
· -достаточность, наличие в классе или модуле всего необходимого для реализации логичного и необходимого поведения;
· – полнота, наличие в интерфейсной части класса всех необходимых характеристик абстракции. Существует формализованная описание абстракции и теория вывода полноты.
· -простота/примитивность, все операции должны быть простыми.
Объектно-ориентированный анализ.
Задача классификации
Определение классов и объектов – одна из сложных задач объектно-ориентированного проектирования. Но, к сожалению, пока не разработаны строгие методы классификации и нет правила, позволяющего выделять классы и объекты. Но имеется богатый опыт классификации в других областях науки, на основе которого разработаны методики объектно-ориентированного анализа. Каждая методика предлагает свои правила идентификации классов и объектов.
Целью классификации является нахождение общих свойств в объектах. Классифицируя, мы объединяем в одну группу объекты, имеющие одинаковое строение или одинаковое поведение. Разумная классификация -часть любой точной науки. Классификация – последовательный и итерационный процесс. Трудность классификации обуславливается в основном широким выбором возможных равноправных решений.
Исторически сложились три основных подхода к классификации:
· – классическое распределение по категориям,
· – концептуальная кластеризация,
· – теория прототипов.
Классическое распределение по категориям (группирование по свойствам). В классическом подходе все вещи, обладающие данным свойством или совокупностью свойств, формируют некоторую категорию, то есть наличие свойства является основным критерием схожести объекта. При этом объекты можно разделить на непересекающиеся множества в зависимости от наличия или отсутствия некоторого признака. По предложению Мински М., наиболее подходящий набор свойств для такой классификации характеризуется высокой независимостью этих свойств относительно друг друга. Этим объясняется такой популярный набор критериев как размер, цвет, форма, и материал. Свойства необязательно должны быть определены измеряемыми характеристиками, в качестве их можно использовать наблюдаемое поведение. Конкретные свойства, которые необходимо выделить при классификации определяются решаемой проблемой. Концептуальная кластеризация (классификация по понятиям) возникла из попыток формального представления знаний. При таком подходе сначала формируется концептуальное описание классов (кластеров объектов) и затем объекты классифицируются согласно описанию, тем самым, образуя классы. Такое распределение объектов по классам имеет явно выраженные вероятностные свойства. Концептуальную кластеризацию можно связать с теорией нечетких (многозначных) множеств, в которой объект может принадлежать к нескольким категориям одновременно с разной степенью точности.
Теория прототипов относится к более современным методам классификации. Существуют некоторые абстракции, которые не имеют ни чётких свойств, ни чёткого определения (например, игры) и рассмотренные методы не работают. В теории прототипов класс определён одним объектом-прототипом и новый объект можно включить при условии, что он определён образом похож на прототип.
Эти три способа классификации составляют теоретические основы объектно-ориентированного анализа групп, которые мы можем применить для идентификации классов и объектов при проектировании сложной системы. На практике мы идентифицируем классы и объекты исходя, прежде всего из свойств рассматриваемой предметной области. Если с помощью этого подхода не удается составить приемлемую структуру, приходится концептуально группировать объекты. Если и в этом случае не можем адекватно смоделировать задачу, то приходится прибегать к классификации с помощью ассоциативных методов, выделяя группы объектов по признаку сходства их с некоторым объектом прототипом.
§
В процессе объектно-ориентированного анализа мы моделируем задачу, определяя классы и объекты, которые формируют словарь предметной области.
Классические подходы. Они основывается на классическом распределении по категориям.
Кандидаты для классов и объектов, предлагаемые С. Шлаером и С.Меллолором:
· – материальные предметы
· – роли (учитель, телезрители, и т. д.)
· – события (прерывание, требование)
· – взаимодействие (встреча, пересечение).
При моделировании баз данных Р. Росс прелагает свой аналогичный список:
· -люди;
· -места;
· -предметы;
· -организации;
· -концепции;
· -события;
Коад и Йордан предложили свой список кандидатов:
· – структуры;
· – другие системы;
· – устройства;
· – события;
· – роли, в которых находятся пользователи;
· – местоположение;
· – организационные единицы.
Анализ поведения.В то время как классические подходы концентрируют внимание на осязаемых элементах предметной области, другое направление объектно-ориентированного анализа считает в качестве первоисточника объектов и классов динамическое поведение. Этот подход подобен концептуальной кластеризации: классы формируются, основываясь на группах объектов, имеющих сходное поведение. Предлагается понятие ответственности объекта, которое определяет его “знания и умения”.
Ответственность объекта – совокупность всех услуг, которые он может предоставлять по всем его контрактам. В иерархии классов каждый подкласс выполняет обязательства суперкласса и добавляет свои дополнительные услуги.
Анализ предметной области. Для поиска общих классов и объектов рекомендуется обратиться ко всем приложениям в рамках предметной области. Здесь выделяются те объекты, операции, связи, которые эксперты данной предметной области считают наиболее важными. В роли эксперта часто выступают просто пользователи системы.
Анализ вариантов ( анализ сценариев).Классический подход, поведенческий подход и изучение предметной области по отдельности сильно зависят от индивидуальных способностей и опыта аналитика. Анализ вариантов – это подход, который можно успешно сочетать с тремя первыми, делая их применение более упорядоченными. Этот вид анализа начинается вместе с анализом требований, когда пользователи, эксперты и разработчики перечисляют сценарии, наиболее существенные для работы с системой.
Затем сценарии тщательно прорабатывается, раскладывается по кадрам. При этом устанавливается, какие объекты участвуют в сценарии, обязанности каждого объекта и как они взаимодействуют в терминах операций, т.е. четко распределяются области влияния абстракций. Далее набор сценариев расширяется, чтобы учесть исключительные ситуации и вторичное поведение. В результате появляются новые и уточняются существующие абстракции CRC карточки. (Class-Responsibilities-Collaborators, Класс-Ответственность-Участники). Это простой и эффективный способ анализа сценариев. На карточке пишется карандашом сверху название класса, в левой половине – за что он отвечает, в правой – с кем сотрудничает. Проходя по сценарию, на каждый обнаруженный класс заводится по карточке. После анализа ответственности класса, возможно, часть ответственности с одного большого класса передается другому классу, или выделяются новые более детальные классы. Карточки можно раскладывать так, чтобы представить формы сотрудничества объектов. С точки зрения динамики сценария, их расположение показывает поток сообщений между объектами, с точки зрения статики они представляют иерархии классов.
Неформальное описание.В описание проблемы на обычном языке подчеркиваются существительные и глаголы. Существительные представляют собой кандидаты для классов; глаголы- кандидаты для операций. Подход весьма приблизителен и не подходит для сложных проблем.
Структурный анализ.Возможно, использование структурного анализа для целей объектно-ориентированного проектирования, но этот подход не рекомендуется из-за опасности непроизвольно перейти к алгоритмической декомпозиции. Но если нет другой альтернативы и уже имеется модель системы, описанная диаграммами потоков данных. В результате анализа диаграмм потоков данных выделяют следующие кандидаты для объектов:
· внешние сущности;
· хранилища данных;
· хранилища управляющих сущностей.
Кандидаты для классов:
· потоки данных;
· потоки управления.
§
Язык UML.
Важный вопрос любой методологии – система обозначения, для визуального модулирования – графическая нотация для описания различных аспектов системы. Множество разработчиков предлагали свои варианты решения этого вопроса для объектно-ориентированной методологии.
Наибольшую поддержку из них получили: нотация Буча, технология объектного моделирования OMT, разработанная Джеймсом Рамбо, объектно-ориентированное проектирование программного обеспечения OOSE Ивара Якобсона. В последствии эти три автора начали внедрять свои разработки идеи двух других, а затем начали работу по объединению этих методов в компании Rational Software. Первая версия стандартной нотации UML появилась в январе 1997 года и большинство производителей ПО и производители CASE-средств поддерживают этот язык. В 1997 году группа OMG (Object Management Group) объявила UML промышленным стандартом. В настоящее время UML находится в процессе представления в качестве стандарта ISO.
UML это графический язык для специфицирования создания визуализации и документирования систем, в которых большая роль принадлежит программному обеспечению. С помощью UML можно разработать модель создаваемой системы, которая отображает не только ее концептуальные элементы, такие как функции системы и бизнесc-процессы ну и конкретные детали системы: классы языков программирования, схемы БД, повторно используемые компоненты ПО.
UML выделяет девять типов диаграмм. При рассмотрении статических аспектов системы используются:
· диаграммы классов;
· диаграммы объектов;
· диаграммы компонентов;
· диаграммы развертывания.
Для работы с динамическими частями системы применяются:
· диаграммы прецедентов;
· диаграммы последовательности;
· диаграммы кооперации;
· диаграммы состояний;
· диаграммы деятельности.
Диаграммы последовательностей и диаграммы кооперации также называются диаграммами взаимодействия.
В языке UML применяются четыре общих механизма:
1. спецификация,
2. дополнение (adornments),
3. принятые деления (common divisions) и
4. механизмы расширения (extensibility mechanisms).
Самой важной разновидность дополнения являются примечания, которые представляют собой графические символы для изображения ограничения или комментариев. Они используются для включения в модель дополнительной информации. В UML заложена открытость, т.е. возможность расширять язык контролируемым способом. К механизмам расширения UML относятся:
· стереотипы (stereotype) предназначенные для расширения словаря UML (например, стереотип класса);
· помеченное значение (tagged value) позволяет включать новую информацию в спецификацию элемента;
· ограничение (constraint) позволяет добавлять или изменять существующие правила.
Спецификация – это неграфическая форма, используемая для полного описания элемента системы обозначений: класса, объекта, операции, диаграммы в целом. Большинство параметров класса определяется в спецификации.
Спецификация класса содержит: имя, текстовое описание, стереотип, атрибуты, операции, ограничения, мощность или множественность класса (cardinality), параметры для параметризированного класса, сохраняемость/устойчивость (мгновенная, долговременная), параллельность (последовательная, охраняемая, синхронная, активная), объём памяти.
При последовательной параллельности (sequential) гарантируется нормальное поведение класса только при наличии одного потока управления.
Охраняемый (guarded) класс- при наличии нескольких потоков, обращения к его операциям должны быть упорядочены, т.е. только одна операция в один момент времени.
Синхронный класс может сам обрабатывать взаимные исключения.
Активный класс будет иметь свой поток управления.
Спецификация операций содержит: имя, текстовое описание, класс возвращаемого значения, аргументы, стереотип, квалификация (является ли функция виртуальной, статической), видимость (открытая, защищенная, реализация), предусловие, действие, постусловие, ограничения, параллельность (последовательная, охраняемая, синхронная), время выполнения, объём памяти требуемой операции во время выполнения.
При моделировании объектно-ориентированных систем используются два подхода к делению реальности. Прежде всего, существует разделение на классы и объекты. Практически все строительные блоки UML характеризуются дихотомией класс/объект. В графическом представлении для объекта принято использовать тот же символ, что и для его класса, а название объекта подчеркивать. Второй вариант деления – это разделение на интерфейс и его реализацию. Интерфейс декларирует контракт, а реализация представляет конкретное воплощение этого контракта и обязуется точно следовать объявленной семантике интерфейса. Интерфейс применяется для моделирования стыковочных узлов.
Интерфейсом называется набор операций, используемый для определения услуг, предоставляемых классом или компонентом, выполняемых прецедентом или подсистемой. Интерфейс изображается в виде круга, присоединенному к реализующему его классу или компоненту.
Интерфейс может быть изображен также как стереотипный класс с множеством операций. Для интерфейса определена операция реализации.
Он может быть реализован несколькими классами и наоборот один класс может реализовывать несколько интерфейсов. Отметим, что у интерфейса нет атрибутов и нет непосредственных экземпляров.
§
Общие сведения и классификация CASE-средств.
В последние годы на мировом рынке программных продуктов появилось много программных средств, называемых CASE-системами, CASE-инструментами или CASE-средствами (CASE-tools). Это программные системы, позволяющие автоматизировать использование новых методов проектирования ПО для разработки сложных систем на всех этапах разработки (особенно на ранних стадиях разработки). Термин CASE трактуется весьма широко. Первоначально он расшифровывался как Computer Aided Software Ingeneering (компьютерная поддержка проектирования ПО), и связано это было с автоматизацией разработки программных систем. В дальнейшем понятие CASE приобрело новый смысл, все чаще его стали расшифровывать как Computer Aided System Ingeneering (компьютерная поддержка проектирования систем), а CASE-средства все больше стали ориентироваться на создание спецификаций, проектирование и моделирование сложных систем широкого назначения.
Применение CASE-продуктов позволяет отслеживать процесс принятия решений при разработке больших проектов, систематизировать информацию о проекте и его компонентах, упрощая тем самым верификацию проекта и сопутствующей ему документации. Важным аспектом CASE-подхода является поддержка коллективной работы, при которой каждый из разработчиков создает свою подсистему, причем в любой момент времени эти подсистемы могут быть объединены в общий проект.
Современные CASE-средства охватывают обширную область поддержки многочисленных технологий проектирования программных систем: от простых средств анализа и документирования до полномасштабных средств автоматизации, покрывающих весь жизненный цикл ПО. Наиболее трудоемкими этапами разработки являются этапы анализа и проектирования, в процессе которых CASE-средства обеспечивают качество принимаемых технических решений и подготовку проектной документации. При этом большую роль играют методы визуального представления информации. Это предполагает построение структурных или иных диаграмм в реальном масштабе времени, использование многообразной цветовой палитры, сквозную проверку синтаксических правил. Графические средства моделирования предметной области позволяют разработчикам в наглядном виде изучать существующую ИС, перестраивать ее в соответствии с поставленными целями и имеющимися ограничениями. Применение CASE-продуктов требует от потенциальных пользователей специальной подготовки и обучения. Опыт показывает, что внедрение этих продуктов осуществляется медленно. Однако по мере приобретения пользователями практических навыков и повышения общей культуры проектирования эффективность этих средств резко возрастает.
Если термин CASE понимать буквально, то CASE-системой можно считать всякую программную систему, помогающую в разработке программ, включая любой транслятор или систему программирования. Но CASE-системы, первоначально появившиеся на рынке программных продуктов под этим названием – это системы, поддерживающие этап анализа проектируемой системы и фиксацию результатов этой работы в виде соответствующих спецификаций.
Обычно к CASE-средствам относят любое программное средство, автоматизирующее ту или иную совокупность процессов жизненного цикла ПО и обладающее следующими основными характерными особенностями:
· мощные графические средства для описания и документирования системы, обеспечивающие удобный интерфейс с разработчиком и
· развивающие его творческие возможности; – интеграция отдельных компонент CASE-средств, обеспечивающая
· управляемость процессом разработки системы;
· – использование специальным образом организованного хранилища проектных метаданных (репозитория).
По мере того как слово CASE входило в моду, им стали называть самые разные инструментальные программные средства, относящиеся к автоматизации проектирования и разработкам программ. Поэтому необходимо ввести некоторую классификацию CASE-систем.
Прежде всего, CASE-системы классифицируются по уровням или этапам разработки программ, которые они охватывают, т.е. содержат средства, помогающие в работах, относящихся к этим уровням или этапам.
Различают верхние (upper) и нижние (lower) системы.
Верхние CASE-системы поддерживают работы по уточнению постановки задачи и анализу проектируемых систем, в ходе которых составляются, корректируются и анализируются спецификации систем. Так как верхние CASE-систем поддерживают те же виды работ, что и упомянутые выше первоначальные CASE-системы, их называют еще нормальными.
Нижние CASE-системы поддерживают работы по проектированию программ, следующие за системным анализом, а также в той или иной степени собственно построение программ (кодирование, генерация кода). Границу между верхними или нижними CASE-системами проводят и несколько иначе, а также выделяют средние (middle) CASE-системы, поддерживающие уровень, промежуточный между верхним и нижним и частично пересекающийся с ними. Для верхних CASE-систем характерно использование графических средств, позволяющих строить, преобразовывать и анализировать разные виды диаграмм, сетей, деревьев. Появление первых CASE-систем связано с развитием графических средств на персональных компьютерах и рабочих станциях.
В этом смысле они как системы автоматизации проектирования программ подобны системам автоматизации проектирования промышленных изделий (САПР), в которых главенствующую роль играют графические средства.
Специфика нормальных CASE-систем, отличающая их от традиционных сред программирования и средств разработки программ, состоит в поддержке верхних уровней поддержки программ. Все современные CASE-средства могут быть классифицированы в основном по типам и категориям. Классификация по типам отражает функциональную ориентацию CASE-средств на те или иные процессы ЖЦ.
Классификация по типам в основном совпадает с компонентным составом CASE-средств и включает следующие основные типы:
· средства анализа (Upper CASE), предназначенные для построения и анализа моделей предметной области (Design/IDEF (Meta Software), BPwin (Logic Works));
· средства анализа и проектирования (Middle CASE), поддерживающие наиболее распространенные методологии проектирования и использующиеся для создания проектных спецификаций (Vantage Team Builder (Cayenne), Designer/2000 (ORACLE), Silverrun (CSA), PRO-IV (McDonnell Douglas), CASE.Аналитик (МакроПроджект)). Выходом таких средств являются спецификации компонентов и интерфейсов системы, архитектуры системы, алгоритмов и структур данных;
· средства проектирования баз данных, обеспечивающие моделирование данных и генерацию схем баз данных (как правило, на языке SQL) для наиболее распространенных СУБД. К ним относятся ERwin (Logic Works), S-Designor (SDP) и DataBase Designer (ORACLE).
· Средства проектирования баз данных имеются также в составе CASE- средств Vantage Team Builder, Designer/2000, Silverrun и PRO-IV;
· средства разработки приложений. К ним относятся средства 4GL (Uniface (Compuware), JAM (JYACC), PowerBuilder (Sybase), Developer/2000 (ORACLE), New Era (Informix), SQL Windows (Gupta), Delphi (Borland) и др.) и генераторы кодов, входящие в состав Vantage Team Builder, PRO-IV и частично – в Silverrun;
· средства реинжиниринга, обеспечивающие анализ программных кодов и схем баз данных и формирование на их основе различных моделей и проектных спецификаций. Средства анализа схем БД и формирования ERD входят в состав Vantage Team Builder, PRO-IV, Silverrun, Designer/2000, ERwin и S-Designor. В области анализа программных кодов наибольшее распространение получают объектно-ориентированные CASE-средства, обеспечивающие реинжиниринг программ на языке С (Rational Rose (Rational Software), Object Team (Cayenne)).
Вспомогательные типы включают:
· средства планирования и управления проектом (SE Companion, Microsoft Project и др.);
· средства конфигурационного управления (PVCS (Intersolv));
– средства тестирования (Quality Works (Segue Software));
· средства документирования (SoDA (Rational Software)).
Классификация по категориям определяет степень интегрированности по выполняемым функциям и включает отдельные локальные средства, решающие небольшие автономные задачи (tools), набор частично интегрированных средств, охватывающих большинство этапов жизненного цикла ИС (toolkit) и полностью интегрированные средства, поддерживающие весь ЖЦ системы и связанные общим репозитарием (workbench).
Существует классификация CASE-средств по поколениям. Первое поколение характеризуется наличием разобщенных средств, повышающих производительность труда и улучшающих качество проектирования на отдельных этапах или операциях разработки. В настоящее время реализация CASE-средств направлена на создание интегрированной среды комплексной автоматизации процессов проектирования, разработки и сопровождения, реализующих некоторую методологию проектирования ПС. Это направление названо второй генерацией CASE. В средствах этой генерации охватываются не только традиционные процессы проектирования и разработки, но и работы по анализу готового ПС (re-engineering) с целью устранения ошибок и, главное, оптимизации характеристик, а также и по укрупненному описанию готового ПС с целью проектирования нового по прототипу уже созданного (reverse engineering). Эти процессы, в первую очередь, традиционны для сопровождения и модификации ПС. Средства второго поколения, как правило, ориентированы на решение задачи комплексной автоматизации процесса разработки и сопровождения систем.
Помимо этого, CASE-средства можно классифицировать по следующим признакам:
· применяемым методологиям и моделям систем и БД;
· степени интегрированности с СУБД;
· доступным платформам.
Интегрированное CASE-средство (или комплекс средств, поддерживающих полный ЖЦ ПО) содержит следующие компоненты:
· репозиторий, являющийся основой CASE-средства. Он должен обеспечивать хранение версий проекта и его отдельных компонентов, синхронизацию поступления информации от различных разработчиков при групповой разработке, контроль метаданных на полноту и непротиворечивость;
· графические средства анализа и проектирования, обеспечивающие создание и редактирование иерархически связанных диаграмм (DFD, ERD и др.), образующих модели ИС;
· средства разработки приложений, включая языки 4GL и генераторы кодов;
· средства конфигурационного управления;
· средства документирования;
· средства тестирования;
· средства управления проектом.
Нормальные CASE-системы могут содержать не все эти средства (например, может не быть средств прототипирования), и возможности средств того или иного вида могут быть представлены в них по-разному (например, графический редактор только для одного типа диаграмм или же для нескольких типов).
Обычная схема реализации upper CASE состоит в том, что сердцем такого средства является объектно-ориентированное хранилище (repository), доступ к которому имеют все подсистемы. Хранилище содержит сведения о каждом элементе проекта отдельно вне зависимости от способа их получения: из графического редактора или таблиц. Общую схему современного upper CASE можно охарактеризовать наличием подсистем для ввода и проверки моделей, управления конфигурацией проекта, интерфейсов с СУБД и языком четвертого поколения и генерации кода (включая средства реинжиниринга), а также средствами документирования проекта и средствами коммуникаци с другими upper CASE.
Направления развития CASE-средств определяются потребностями практики и ориентированы на:
· расширение применяемых моделей описания автоматизируемых систем;
· охват автоматизацией новых архитектур ИС, включая схему клиент/сервер;
· более глубокий уровень контроля целостности проекта;
· интеграцию со многими 4GL, СУБД и CASE;
· использованием новых платформ, прежде всего рабочих станций.
CASE системы позволяет существенно ускорить не только разработку системы, но также и ее сопровождение, так как внесение изменений существенно упрощается, поскольку информация о разработке хранится в базе данных CASE системе и может быть легко модифицирована.
По некоторым данным использование CASE в процессе разработки позволяет сократить ее сроки в 3 раза, а сроки внесения изменений в 200 раз.
Проекты средней, высокой сложности и уникальные рекомендуется создавать с помощью CASE-средств и языков четвертого поколения (4GL).
Целесообразность применения CASE-средств (upper CASE), прежде всего интегрированных, определяется возможностью точного учета требований конечного пользователя к проектируемой системе, значительным снижением уровня системных ошибок в проекте до начала программирования и тем самым снижением общей трудоемкости разработки и особенно отладки программ.
§
Одной из наиболее известных CASE систем, поддерживающей OOM является семейство CASE-средств объектно-ориентированного анализа, проектирования и программирования Rational Rose фирмы Rational Software Corp.
Rational Rose предназначено для автоматизации этапов анализа и проектирования ПО, а также для генерации кодов на различных языках и выпуска проектной документации. Rational Rose использует синтез-методологию объектно-ориентированного анализа и проектирования, основанную на подходах трех ведущих специалистов в данной области: Буча, Рамбо и Джекобсона и поддерживает универсальную нотацию для моделирования объектов UML. Конкретный вариант Rational Rose определяется языком, на котором генерируются коды программ (C , Visual C, Java, Smalltalk, Visual Basic, PowerBuilder, Ada, и др.). Основной вариант -Rational Rose позволяет разрабатывать проектную документацию в виде диаграмм и спецификаций, а также генерировать программные коды. Кроме того, Rational Rose содержит средства реинжиниринга программ, обеспечивающие повторное использование программных компонент в новых проектах.
Структура и функции
В основе работы Rational Rose лежит построение различного рода диаграмм и спецификаций, определяющих логическую и физическую структуры модели, ее статические и динамические аспекты. В их число входят диаграммы классов, прецедентов, состояний, последовательностей и кооперации, компонентов, процессов.
В составе Rational Rose можно выделить шесть основных структурных компонент: репозиторий, графический интерфейс пользователя, средства просмотра проекта (browser), средства контроля проекта, средства сбора статистики и генератор документов. К ним добавляются генератор кодов (индивидуальный для каждого языка) и анализатор, обеспечивающий реинжиниринг – восстановление модели проекта по исходным текстам программ.
Репозиторий представляет собой объектно-ориентированную базу данных. Средства просмотра обеспечивают “навигацию” по проекту, в том числе, перемещение по иерархиям классов и подсистем, переключение от одного вида диаграмм к другому и т. д. Средства контроля и сбора статистики дают возможность находить и устранять ошибки по мере развития проекта, а не после завершения его описания. Генератор отчетов формирует тексты выходных документов на основе содержащейся в репозитории информации.
Средства автоматической генерации кодов программ на языке С , используя информацию, содержащуюся в логической и физической моделях проекта, формируют файлы заголовков и файлы описаний классов и объектов. Создаваемый таким образом скелет программы может быть уточнен путем прямого программирования на языке С . Анализатор создает модули проектов в форме Rational Rose на основе информации, содержащейся в определяемых пользователем исходных текстах на С . В процессе работы анализатор осуществляет контроль правильности исходных текстов и диагностику ошибок. Модель, полученная в результате его работы, может целиком или фрагментарно использоваться в различных проектах.
Анализатор обладает широкими возможностями настройки по входу и выходу. Например, можно определить типы исходных файлов, базовый компилятор, задать, какая информация должна быть включена в формируемую модель, и какие элементы выходной модели следует выводить на экран. Таким образом, Rational Rose обеспечивает возможность повторного использования программных компонент.
В результате разработки проекта с помощью CASE-средства Rational Rose формируются следующие документы:
· диаграммы классов;
· диаграммы состояний;
· диаграммы взаимодействия;
· диаграммы модулей;
· диаграммы процессов;
· спецификации классов, объектов, атрибутов и операций заготовки текстов программ;
· модель разрабатываемой программной системы.
Последний из перечисленных документов является текстовым файлом, содержащим всю необходимую информацию о проекте (в том числе необходимую для получения всех диаграмм и спецификаций).
Тексты программ являются заготовками для последующей работы программистов. Они формируются в рабочем каталоге в виде файлов типов .h (заголовки, содержащие описания классов) и .cpp (заготовки программ для методов). Система включает в программные файлы собственные комментарии, которые начинаются с последовательности символов //##.
Состав информации, включаемой в программные файлы, определяется либо по умолчанию, либо по усмотрению пользователя. В дальнейшем эти исходные тексты развиваются программистами в полноценные программы.
Для организации групповой работы в Rational Rose возможно разбиение модели на управляемые подмодели. Каждая из них независимо сохраняется на диске или загружается в модель. В качестве подмодели может выступать категория классов или подсистема.
Для управляемой подмодели предусмотрены операции:
· загрузка подмодели в память;
· выгрузка подмодели из памяти;
· сохранение подмодели на диске в виде отдельного файла;
· установка защиты от модификации;
· замена подмодели в памяти на новую.
Наиболее эффективно групповая работа организуется при интеграции Rational Rose со специальными средствами управления конфигурацией и контроля версий (PVCS). В этом случае защита от модификации устанавливается на все управляемые подмодели, кроме тех, которые выделены конкретному разработчику. В этом случае признак защиты от записи устанавливается для файлов, которые содержат подмодели, поэтому при считывании “чужих” подмоделей защита их от модификации сохраняется и случайные воздействия окажутся невозможными.
§
Общие организационно-методические указания по выполнению лабораторного практикума
Методические указания построены по следующему принципу: сначала ставится цель задания, затем дается методика достижения цели, потом на примере разбирается решение, и только после этого выдаются индивидуальные задания по вариантам .
Рассмотренные в методических указаниях в качестве примеров задачи должны быть решены студентом. Только после этого студент самостоятельно решает задачи в соответствии с выбранным вариантом. Письменные выводы, сделанные в ходе выполнения заданий заносятся студентом в тетрадь, с указанием варианта и номеров задания.
Решенные примеры сохраняются в файле рабочей книги в каталоге студента, указанном преподавателем, на ПК.
СТРУКТУРА
ЦЕЛИ И ЗАДАЧИ
Цель
Научиться пользоваться системой бизнес-моделирования на примере Business Studio.
Задача
Научиться пользоваться программой и самостоятельно построить модель предложенного предприятия.
ПРИОБРЕТАЕМЫЕ НАВЫКИ
· Умение работать программой бизнес-моделирования
· Умение создать бизнес-модель любого предприятия
· Умение решать вопросы в области финансового управления
ЛАБОРАТОРНАЯ РАБОТА 1
ЗАДАНИЕ 1
Создание системы целей и показателей (на примере предложенном на сайте Business Studio)
ТЕХНОЛОГИЯ РАБОТЫ
Для достижения успеха любая компания должна обеспечить свою стратегию и обеспечить ее понимание руководителями и сотрудниками компании. Так же не мало важным является регулярный контроль реализации стратегии одним из инструментов процессов реализации стратегии в понимаемой форме является сбалансированная система показателей. Так система экономических показаний компании основана на оценке ее эффективности по набору подобранных показателей отражающих все аспекты деятельности организации как финансовые, так и не финансовые. Название системы отражает то равновесие, которое сохраняется между краткосрочными и долгосрочными целями, а так же финансовыми и не финансовыми показателями. При формулировании стратегии на основе сбалансированных показателей деятельность компании рассматривается в рамках четырех перспектив, (рис.1):
1. Финансы
2. Клиенты
3. Обучение
4. Развитие

Рисунок 1. Формулировании стратегии на основе сбалансированных показателей деятельность компании.
Система Business Studio позволяет произвести как формализацию стратегии, так и ее реализацию.
Для создания системы целей и показателей необходимо использовать подраздел <Цели и показатели> в разделе <Управление>, (рис.2).
Рисунок 2. Подраздел Цели и показатели.
Сформируем верхний уровень системы Целей и показателей,откроем разделПерспективы стратегической карты,он предназначен для разделов наиболее значимых сфер в которых предприятие стремится достигнуть результата.
По умолчанию определены четыре перспективы:
1. Финансы
2. Клиенты
3. Внутренние бизнес-процессы
4. Обучение и развитие
Рассмотрим деятельность компании в рамках этих перспектив. Для построения системы стратегического управления декомпозируем стратегию компании на конкретные стратегические цели. Цели в одноименном разделе, можно сгруппировать по папкам, (рис.3).
Например с названиями перспектив. Добавляем папку Финансы и спомощью команды Добавить от текущего (рис.4), добавляем цель «Рост прибыли»(рис.5), достижение данной цели зависит от достижения двух целей (рис.6): Увеличение количества клиентов и Сокращение издержек.
Рисунок 3. Группировка Целей по папкам.

Рисунок 4.
Рисунок 5.
Рисунок 6.
Подобным образом добавляем все необходимые цели. В результате можно сформировать следующий перечень Целей, (рис.7):

Рисунок 7.
Отобразить причины следственной связи графически на стратегической карте, для этого в одноименном разделе создаем новую (в контекстном меню «добавить от текущего») карту и называем ее «Стратегическая карта ООО ИнТехПроект», преходим к ее построению, (рис.8).
Рисунок 8.
Каждая стратегическая цель связана с одной из перспектив. На стратегическую карту из навигатора перетягиваем по одной перспективе. Выбираем горизонтальное расположение строк перспектив на диаграмме, (рис. 9, 10).
Рисунок 9.
Рисунок 10.
При работе с диаграммой размеры строк перспектив можно изменять.
Каждую цель перетягиваем в строку перспектив на которую она влияет, т.е. Рост прибыли, Сокращение издержек, Увеличение количества клиентов – в перспективу Финансы и т.д. (Размеры Целей на диаграмме так же можно изменять). Устанавливаем причины следственной связи целей с помощью стрелок, (рис.11), стрелки добавляем на диаграмму при помощи стрелок на палитре элементов(рис. 12).

Рисунок 11.
Рисунок 12.
Силу влияния можно изменять в свойствах стрелки, (рис. 13)
Рисунок 13.
По умолчанию устанавливается Нормальное влияние. Нажмите Закрыть.
Рисунок 14.
Для того чтобы сохранить диаграмму нажмите на панели инструментов значок «дискета», или нажмите Ctrl S, (рис.15).

Рисунок 15.
СПИСОК ЛИТЕРАТУРЫ
1. Буч Г. Объектно-ориентированный анализ и проектирование с примерами
приложений на С , 2-е изд,.Пер. с англ. -М.: “Издательство Бином”,
СПб:”Невский диалект”, 1998. -560с.
2. Буч Г., Рамбо Д., Джекобсон А. Язык UML. Руководство пользователя:
Пер. с англ. – М.:ДМК, 2000. -432с.
3. Липаев В.В., Филинов Е.Н. Мобильность программ и данных в открытых
информационных системах. – М.: Научная книга, -1997. -368с.
4. Боггс У.,Боггс М. UML и Rational Rose,Пер. с англ. -М.: Издательство
“ЛОРИ”, 2000. -580с.
5. Вендров А.М. Проектирование программного обеспечения
экономических информационных систем: Учебник. -М. Финансы и
статистика, 2000. -352с





