
Доверительный интервал, погрешность и размер выборки
Возьмем самое первое уравнение и выразим оттуда ширину доверительного интервала (Ур. 2).
В некоторых случаях мы можем заменить t-статистику Стьюдента на z стандартного нормального распределения. Еще одним упрощением заменим половину от w на погрешность измерения E. Тогда наше уравнения примет вид (Ур. 3).
Как видим погрешность действительно уменьшается вместе с ростом количества входных данных. Откуда легко вывести искомое (Ур. 4).
Использованные материалы
- Sample sizes
- Hypothesis testing
Методы определения минимально необходимого объема выборки в медицинских исследованиях
ЭЛЕКТРОННЫЙ НАУЧНЫЙ ЖУРНАЛ 2021*65(6)
Социальные аспекты здоровья населения / Social aspects of Population Health ‘
27.12.2021 г.
DOI: 10.21045/2071-5021-2021-65-6-10
Наркевич А.Н., Виноградов К.А.
МЕТОДЫ ОПРЕДЕЛЕНИЯ МИНИМАЛЬНО НЕОБХОДИМОГО ОБЪЕМА ВЫБОРКИ В МЕДИЦИНСКИХ ИССЛЕДОВАНИЯХ
ФГБОУ ВО «Красноярский государственный медицинский университет им. проф. В.Ф. Войно-Ясенецкого» Министерства здравоохранения Российской Федерации, Красноярск, Россия
Резюме
Актуальность. Одним из важнейших вопросов, который встает перед исследователем еще на этапе планирования медицинского исследования, является определение минимально необходимого объема выборки исследуемых единиц наблюдения. Неверное или халатное отношение к решению данного вопроса может свести результаты исследования, длящегося несколько лет, на нет.
Целью данной статьи является систематизация и рассмотрение различных методы расчета минимально необходимого объема выборки при планировании медицинских исследований.
Результаты. В статье представлены наиболее часто применяемые при планировании медицинских исследований методы определения минимально необходимого объема выборки. Представленная группировка методов определения объема выборки включает такие основные группы, как методы, которые не требуют предварительных знаний об изучаемом явлении и методы, которые требуют от исследователя предварительных данных о том, что будет исследоваться. Представлены примеры использования данных методов.
Заключение. На текущий момент в практике медицинских исследований отсутствует четко установленная методология определения минимально необхо-
димого объема выборки, однако, при представлении диссертационных исследований это является обязательным условием для обеспечения достоверности полученных результатов.
Область применения результатов. Представленные в данной статье методы могут быть использованы для определения минимально необходимого объема выборки при планировании медицинских исследований, в том числе диссертационных.
Ключевые слова: объем выборки; выборка; репрезентативность; медицинские исследования; диссертационные исследования.
Контактная информация: Наркевич Артем Николаевич, e-mail: narkevichart@gmail.com
Финансирование. Исследование не имело спонсорской поддержки. Конфликт интересов. Авторы заявляют об отсутствии конфликта интересов.
Для цитирования: Наркевич А.Н., Виноградов К.А. Методы определения минимально необходимого объема выборки в медицинских исследованиях. Социальные аспекты здоровья населения [сетевое издание] 2021; 65(6):10. URL: http://referat-zona.ru/content/view/1123/30/lang.ru/ DOI: 10.21045/2071-50212021-65-6-10
Narkevich A.N., Vinogradov K.A.
METHODS FOR DETERMINING THE MINIMUM REQUIRED SAMPLE SIZE IN MEDICAL RESEARCH
Prof. V.F. Voino-Yasenetsky Krasnoyarsk State Medical University, Krasnoyarsk, Russia
Abstract
Significance. One of the most important challenges faced by a researcher at the planning stage of a medical research is to decide on the minimum required sample size of the studied units under observation. Incorrect or negligent attitude to this issue can bring the results of the study, which lasts for several years, to naught.
The purpose of this article is to systematize and consider various methods for calculating the minimum required sample size in planning a medical research.
Results. The article presents the most frequently used in the planning stage of a medical research methods for determining the minimum required sample size. The presented grouping of sample methods includes such basic groups as methods that do not require previous knowledge about the phenomenon under study and methods that require preliminary data collection on the study subject from the researcher. The article also exemplifies these methods.
Conclusions. Currently, there is no clear methodology for determining the minimum required sample size in the practice of medical research, however, it is the must for ensuring reliability of the results in presenting a dissertation research.
Scope of application. The methods presented in this article can be used to determine the minimum required sample size in planning a medical research, including a dissertation one.
Keywords: sample size; sample; representativeness; medical research; dissertation research.
Corresponding author: Artem N. Narkevich, e-mail: narkevichart@gmail.com Information about authors:
Narkevich A.N., http://orcid.org/0000-0002-1489-5058 Vinogradov K.A., http://orcid.org/0000-0001-6224-5618 Acknowledgments. The study had no sponsorship. Conflict of interests. The authors declare no conflict of interest.
For citation: Narkevich A.N., Vinogradov K.A. Methods for determining the minimum required sample size in medical research. Social’nye aspekty zdorov’a naselenia / Social aspects of population health [serial online] 2021; 65(6):10. Available from: http://referat-zona.ru/content/view/1123/30/lang.ru/. (In Rus). DOI: 10.21045/2071-5021-2021-65-6-10
Введение
Одним из важнейших вопросов, который встаёт перед исследователем ещё на этапе планирования медицинского исследования, является определение минимально необходимого объема выборки исследуемых единиц наблюдения [1,2]. Неверное или халатное отношение к решению данного вопроса может свести результаты исследования, длящегося несколько лет, на нет [3,4].
При этом, в медицинских исследованиях существует как проблема недостаточности выборки, когда полученная выборка не отражает генеральную совокупность и, соответственно, результаты, полученные на такой выборке, не могут быть экстраполированы на всю генеральную совокупность, так и проблема неоправданно большой выборки. Неоправданно большая выборка, во-первых, повышает денежные и трудовые затраты необходимые для проведения исследования, а во-вторых, неоправданно большой объем выборки повышает вероятность найти случайные статистически значимые закономерности, которые отсутствуют в генеральной совокупности [5].
В данной статье совершена попытка систематизировать и рассмотреть различные методы расчета минимально необходимого объема выборки при планировании медицинских исследований.
Необходимо отметить, что все методы определения объема выборки можно разделить на две группы. Первая группа – методы, которые не требуют предварительных знаний об изучаемом явлении. Вторая – методы, которые требуют от исследователя предварительных данных о том, что будет исследоваться. При использовании методов, входящих во вторую группу, как правило, объем выборки получается меньшим, но их применение более обременительно и с финансовой и с организационной точек зрения.
Методы, не требующие предварительных знаний об изучаемом явлении
К первой группе методов можно отнести использование для определения минимального объема выборки таблиц К.А. Отдельновой [6], В.И. Паниотто [7] и N. Fox [8].
Согласно таблице К.А. Отдельновой (таблица 1) исследования можно классифицировать по 3 уровням точности: ориентировочное знакомство, исследование средней точности, исследование повышенной точности. Такие три уровня точности весьма условно с практической точки зрения можно разделить следующим образом. Уровень точности «ориентировочное знакомство» соответствует пилотному исследованию, «исследование средней точности» – подойдет для исследования, результаты которого можно будет опубликовать в качестве научной статьи с последующим более глубоким изучением, ну а «исследование повышенной точности» – для диссертационного исследования и формирования окончательных заключений.
Таблица 1
Определение объема выборки по методике К.А. Отдельновой
Уровень значимости (p) Уровень точности
Ориентировочное знакомство Исследование средней точности Исследование повышенной точности
0,05 44 100 400
0,01 100 225 900
В связи с тем, что в медицинских исследованиях принято в качестве границы статистической значимости результатов использовать уровень значимости равный 0,05, то согласно методике К.А. Отдельновой объем выборки диссертационного исследования должен составить 400 единиц наблюдения. Естественно, если исследователь планирует получить уровень значимости меньше, чем 0,05, то и необходимый объем выборки должен быть больше.
Методика определения объема выборки по методике В.И. Паниотто также предусматривает использование таблицы (таблица 2). В данной таблице приведено соответствие объема генеральной совокупности и необходимого объема выборки при уровне значимости 0,05. Следует обратить внимание, что согласно таблице К.А. Отдельновой и В.И. Паниотто для диссертационного исследования, в котором объем генеральной совокупности довольно велик, достаточно сформировать выборку, включающую 400 единиц наблюдения.
Таблица 2
Определение объема выборки по методике В.И. Паниотто при уровне
значимости 0,05
Объем генеральной совокупности 500 1000 2000 3000 4000 5000 10000 100000 ж
Объем выборки 222 286 333 350 360 370 385 398 400
Таблица, разработанная N. Fox (таблица 3), предусматривает для определения необходимого объема выборки оценку величины допускаемой ошибки.
Таблица 3
Определение объема выборки по методике N. Fox
Величина допускаемой ошибки, % Объем выборки
10 88
5 350
3 971
2 2188
1 8750
Необходимо отметить, что приведенные выше методики разрабатывались для социологических опросов и для социально-гигиенических исследований, но они плотно закрепились и при планировании медицинских клинических исследований, так что они вполне могут быть использованы для определения объема выборки, но как уже было сказано выше, использование данных методик дает довольно большие объемы выборок.
Очень важно отметить, что если исследователь планирует изучать несколько исследуемых групп, в том числе путем сравнения этих групп между
собой, то необходимо определение по описанным выше методикам объема каждой группы – каждая группа, то есть выборка, должна быть извлечена из своей генеральной совокупности с собственным расчетом объема выборки.
Методы, требующие от исследователя предварительных данных
Вторая группа методик определения объема выборки зависит от дизайна исследования и вида признаков, которые будут исследоваться в исследовании, и основывается на использовании специализированных формул. Все эти формулы приведены в таблицах 4-6 [9].
Таблица 4
Формулы для расчета объема выборки при проведении описательного исследования одной группы
Вид изучаемых признаков
Количе ственный Качественный
1. При неизвестном объеме генеральной совокупности ,.2 * 2 “= Д2 2. При известном объеме генеральной совокупности ^ * ст2 * ^ Д2 * N Ь2 * СТ2 1. При неизвестном объеме генеральной совокупности Ь2 * Р * 0 П= Д2 2. При известном объеме генеральной совокупности Ь2 * Р * 0 * N п= 2 7 д2 * N г7 * Р * 0
1. Ь2 – критическое значение критерия Стьюдента при соответствующем уровне значимости (как правило в медицинских исследованиях используется в качестве критического используется уровень значимости
0,05, то при таком уровне значимости Ь2 – 1,96);
2. ст – стандартное отклонение признака, который будет изучаться в исследовании;
3. Д – предельно допустимая ошибка (в медицинских исследованиях как правило 5%).
4. N – объем генеральной совокупности.
5. Р – доля случаев, в которых встречается изучаемый признак.
6. Q – доля случаев, в которых не встречается изучаемый признак
(100-Р).
Для примера приведем расчеты объема выборки по формулам, приведенным во втором столбце таблицы 4. Рассмотрим для начала случай с неизвестной генеральной совокупностью. Исследователь изучает удельный вес неблагоприятных исходов беременности и хочет определить объем выборки с уровнем значимости 0,05 и предельно допустимой ошибкой 5%. Из литературных данных или пилотного исследования установлено, что удельный вес неблагоприятных исходов у беременных составляет 10%. В соответствии с имеющимися условиями объем выборки рассчитывается следующим образом:
I2 * p * р 1 9б2 * 10 * 90 3,8416 * 10 * 90 3457,44
п= -^ = ^- = = = 138,3^139
Д2 52 25 25
То есть для поставленной исследователем задачи достаточно сформировать выборку, включающую 139 беременных женщины. Теперь предположим, что у исследователя имеется информация об объеме генеральной совокупности (5000 беременных в год) и используя те же условия исследовательской задачи рассчитаем объем выборки:
= Ь2 * Р * О * N = 1.962 * 10 * 90 * 5000 = 3,8416 * 4500000 = 17287200 = 17287200 = 1346 Д2*N t2*P*О 52*5000 1,962*10 *90 25*5000 3,8416* 900 125000 3457,44 128457,44 ~135
Таким образом, при использовании дополнительной информации в виде объема генеральной совокупности был получен чуть меньший объем выборки. Естественно, при увеличении объема генеральной совокупности объем выборки будет увеличиваться, так при объеме генеральной совокупности 100000 человек, объем выборки будет равен объему, полученному при использовании формулы, которая не учитывает генеральную совокупность при расчете:
п=
¿2*Р*О* N 1,962*10*90*100000 3,8416 * 90000000 345744000 345744000 1381
Д2*N t2*P*О 52*100000 1,962*10*90 25*100000 3,8416*900 2500000 3457,44 2503457,44 ~139
Таблица 5
Формулы для расчета объема выборки при проведении исследования, в котором предполагается сравнение двух несвязанных групп
Вид изучаемых признаков
Количественный
Качественный
2 2 2 2 о о2*г
(*1-К)
1 2/ 22 о 2*г
( * 1-X 2 )
22 1*г
Р1*01*г2 Р2*02*г2
(Р1-Р2 Г
Р 2*02*г2
2
, ,2 Р1*01*г (Р- Р 2)2- 1 П1
п
п
1
1
п
2
п
1
1
1. Ь2 – критическое значение критерия Стьюдента при соответствующем уровне значимости (как правило в медицинских исследованиях используется в качестве критического используется уровень значимости
0,05, то при таком уровне значимости Ь2 – 1,96);
2. о – стандартное отклонение признака, который будет изучаться в исследовании в каждой группе;
3. X – среднее арифметическое признака, который будет изучаться в каждой группе.
4. Р – доля случаев, в которых встречается изучаемый признак.
5. Q – доля случаев, в которых не встречается изучаемый признак (100-Р.).
Далее рассмотрим использование формул для расчета объема выборки при проведении исследования, в котором предполагается сравнение двух несвязанных групп. Рассмотрим пример расчета объема выборки при сравнении двух несвязанных групп и изучении качественного признака. Например, исследователем предполагается сравнение удельного веса неблагоприятных исходов беременности у женщин до 40 лет с удельным весом неблагоприятных исходов у женщин старше 40 лет. В пилотном исследовании получено, что удельный вес неблагоприятных исходов беременности у женщин до 40 лет составляет 5%, а у
женщин старше 40 лет – 15%. Предполагается рассчитать объем выборки для получения результатов сравнения как минимум с уровнем значимости 0,05. Воспользуемся формулами, приведенными во втором столбце таблицы 27 и рассчитаем сначала объем первой группы:
_P1*Q1*t2 P2*Q2*t2 _5*95* 1,962 15*85*1,962 _ 475*3,8416 1275*3,8416 _ 1824,76 4898,04_ 6722,8
= 67,2 и 63
(р1-р2)2 (5-15 )2 -102 100 100
И объем второй группы:
2 2
P2*Q2* 15*85*1,962 1275*3,8416 4898,04 4898,04 4898,04 п
п2 =-7 =-г=-=-=-=-= 68,9и 69
2 2 Р^ * (5_15)2_5*95*1,962 _102_ 475*3,8416 100_ 1824,76 100-28,96 71,04 ‘
(р1-р2)–п- ^ ‘ 63 63 63
п1
Таким образом, для проведения планируемого исследования необходимый объем I группы должен составить 63 беременных женщины, а II группы – 69 женщин. Естественно при сравнении двух несвязанных групп объемы сравниваемых групп могут отличаться, чего нельзя сказать о сравнении связанных групп, когда их объем должен быть одинаковым.
Таблица 6
Формулы для расчета объема выборки при проведении исследования, в котором предполагается сравнение двух связанных групп
Вид изучаемых признаков
Количе ственный Качественный
2 2 2 2 о1*t о2* P1*Q1*t2 P2*Q2*t2
п1= ¡г г 12 (* 1_ * 2) (Р1_ Р2)2
1. Ь2 – критическое значение критерия Стьюдента при соответствующем уровне значимости (как правило в медицинских исследованиях используется в качестве критического используется уровень значимости
0,05, то при таком уровне значимости Ь2 – 1,96);
2. о – стандартное отклонение признака, который будет изучаться в исследовании в каждой группе;
3. X – среднее арифметическое признака, который будет изучаться в каждой группе.
4. Р – доля случаев, в которых встречается изучаемый признак.
5. Q – доля случаев, в которых не встречается изучаемый признак (100-Р).
Рассмотрим использование формул для расчета объема выборки при проведении исследования, в котором предполагается сравнение двух связанных групп. Например, исследователем предполагается сравнение удельного веса пациентов, страдающих раком легкого, у которых имеется превышение нормативных показателей СОЭ до лечения и после. В пилотном исследовании получено, что удельный вес больных раком легкого, у которых имеется превышение нормативных показателей СОЭ составляет 50%, а после лечения – 40%. Предполагается рассчитать объем выборки для получения результатов сравнения как минимум с уровнем значимости 0,05. Воспользуемся формулами, приведенными во втором столбце таблицы 28 и рассчитаем сначала объем первой группы:
_Р1*01*г:2 Р2*02*^ 50*50* 1,962 20*80 1,962_ 2500*3,8416 1600*3,8416 _ 9604 6146,56_ 15750,56
(р1-р2)2 (50-40 )2 102 100 100
– = 175,5 -176
Таким образом, объем каждой группы должен составить по 176 единиц наблюдения.
Источниками для определения X, о и Р при использовании методов, представленных в таблицах 4-6, как правило, служат либо результаты пилотного исследования, либо данные литературы, в которой описываются аналогичные исследования. Что же делать, когда в литературе не удается найти необходимые данные, а проведение пилотного исследования по каким-либо причинам невозможно? В таком случае параметры X и о можно получить следующим расчетным путем. Исследователю необходимо (как правило из личного опыта) оценить минимальное и максимальное значения изучаемого признака, после чего параметры X и о можно рассчитать по следующим формулам:
X _ X
-у-_ -у” max min
X — Xmin 2
X _x
_ max min
о —-
6
Такой расчетный путь основывается на том, что расстояние между максимальным и минимальным значениями признака примерно равно шести стандартным отклонениям, что вытекает из правила трех сигм, а среднее арифметическое – примерно середина расстояния между максимальным и минимальным значениями признака.
Если проводится расчет объема выборки исследования, в котором будут изучаться качественные признаки, то можно использовать параметр P равный 50. В таком случае произведение P * Q будет максимальным (50*50=2500). Такой подход естественно приведет к завышению объема выборки, но если другого выхода у исследователя нет, то этот вариант будет единственным для того чтобы не получить заниженное минимально необходимое число исследуемых.
Таким образом, использование для расчета объема выборки формул, приведенных в таблицах 4-6 дает существенно меньшие результаты, чем табличные методы, однако их использование в некоторых случаях может привести к необоснованному занижению необходимого объема выборки.
В научно-методической литературе также описываются другие методы определения объема выборки. Одним из таких методов является номограмма Альтмана [10,11]. Метод заключается в использовании номограммы, приведенной на рисунке 1. Номограмма имеет 2 оси: левая ось Д представляет стандартизованную разность, а правая ось 1-ß – мощность. Метод заключается в том, что необходимо провести линию от значения оси Д к значению оси 1-ß. На пересечении такой линии и линии, соответствующей необходимому уровню значимости и будет представлен необходимый объем выборки.
В медицинских исследованиях мощность (1-ß) как правило выбирается равной 0,80 или 0,90, но чаще всего мощности 0,80 вполне достаточно. Расчет
стандартизованной разности зависит от вида признака, который будет изучаться в исследовании и связанности сравниваемых групп.
Если планируется исследование со сравнением количественного показателя между несвязанными группами, то стандартизованная разность рассчитывается:
X1 _ X 2
д= —-2
о
где Х1 – среднее арифметическое признака в первой сравниваемой группе, Х2 – среднее арифметическое признака во второй сравниваемой группе, о -стандартное отклонение сравниваемого признака.
Если планируется исследование со сравнением количественного показателя между связанными группами, то стандартизованная разность рассчитывается:
д=2*( X!_ X 2) о
где Х1 – среднее арифметическое признака в первой сравниваемой группе, Х2 – среднее арифметическое признака во второй сравниваемой группе, о -стандартное отклонение сравниваемого признака.
Рис. 1. Номограмма Альтмана
Если планируется исследование со сравнением качественного показателя между группами, то стандартизованная разность рассчитывается:
Р=
Д:
Р Р
12
2
Р _ Р
Г1 2
V Р(100_ Р)
где Р1 – доля признака в первой сравниваемой группе, Р2 – доля признака во второй сравниваемой группе.
Таким образом, после расчета стандартизованной разности и выбора необходимой мощности с помощью номограммы Альтмана можно рассчитать необходимый объем выборки. Воспользуемся следующим примером. Исследователем из литературных данных получено, что удельный вес изучаемого признака в первой группе составляет 60%, а во второй 40%. Для расчета объема выборки мощность выбрана равной 0,80. Рассчитаем стандартизованную разность:
Р_ Р1 Р2 _ 60 40 _ 100 _50 _ 2 _ 2 _ 2 _
Д _ Р1-Р2 _ 60-40 _ 20 _ 20 _ 20 _04 _ VР(100-Р) _ 750*(100-50)_ V50*50 ~ V2500 _ 50 _ ‘
После необходимых вычислений проведем линию, соединяющую ось стандартизованной разности в точке 0,4 и ось мощность в точке 0,80 (рисунок 2).
Таким образом, объем выборки такого исследования при желаемом уровне значимости результатов равном 0,05 примерно равен 200, а при уровне значимости равном 0,01 – 300. Необходимо отметить, что полученный объем выборки отражает общий объем сравниваемых групп, то есть при уровне значимости 0,05 объем первой группы может составить 120, а второй 80 в случае несвязанных групп, а в случае связанных групп – по 100 в каждой группе.
Довольно часто в научно-методической литературе также встречается использование для расчета объема выборки формулы Лера [12]:
16
п _—
д
где Д – стандартизованная разность, которая рассчитывается точно также, как и при использовании номограммы Альтмана.
Рис. 2. Определение объема выборки с помощью номограммы Альтмана
Данная формула позволяет рассчитать объем выборки при мощности 0,80 и уровне значимости 0,05. Так в предыдущем примере Д было равно 0,4. Объем выборки согласно формуле Лера составит:
16 16 „ п =—=—=40 Д 0,4
То есть каждая из изучаемых групп должна составить по 40 единиц наблюдения.
Заключение
На текущий момент в практике медицинских исследований отсутствует четко установленная методология определения минимально необходимого объема выборки, однако, при представлении диссертационных исследований это является обязательным условием для обеспечения достоверности полученных результатов. Такая ситуация складывается как в российской, так и в зарубежной научной практике. Одни методы, «кочуют» от исследования к исследованию и являются уже «общепринятыми». В какой-то момент появляются новые методы, предлагаемые различными авторами. В связи с этим исследователю довольно сложно определится с методами, которые следует применить при планировании собственного исследования. Особо остро данная проблема стоит перед аспирантами и соискателями, которые планируют диссертационные исследования. Это связано с необходимостью быстрого и оперативного планирования своего диссертационного исследования.
Таким образом, в данной работе представлены наиболее часто применяемые методы определения необходимого объема выборки, которые могут быть применены при планировании исследований, в том числе диссертационных.
Библиография
1. Machin D., Campbell M., Fayers P., Pinol A. Sample size tables for clinical studies. 3nd ed. Oxford: Blackwell Science. 2009: 315.
2. Chow Sh.-Ch., Shao J., Wang H. Sample size calculations in clinical research. New-York: Marcel Dekker, Inc. 2003: 358 p.
3. Röhrig B., Prel J.-B., Wachtlin D., Kwiecien R., Blettner M. Sample Size Calculation in Clinical Trials. Part 13 of a Series on Evaluation of Scientific Publications. Deutsches Ärzteblatt International. 2021; 107 (31-32): 552-556.
4. Whitley E., Ball J. Statistics review 2: Samples and populations. Critical Care. 2002; 6 (2): 143-148.
5. Наркевич А.Н., Виноградов К.А. Настольная книга автора медицинской диссертации: пособие. М., Инфра-М. 2021: 454.
6. Отдельнова К. А. Определение необходимого числа наблюдений в социально-гигиенических исследованиях. Сб. трудов 2-го ММИ. 1980; 150 (6): 18-22.
7. Паниотто В. И., Максименко В. С. Количественные методы в социологических исследованиях. Киев: Наукова Думка. 1982: 272.
8. Fox N., Hunn A., Mathers N. Sampling and sample size calculation. -Yorkshire & the Humber: The NIHR RDS for the East Midlands. 2007: 41.
9. Сырцова Л.Е., Косаговская И.И., Авсентьева М.В. Основы эпидемиологии и статистического анализа в общественном здоровье и управлении здравоохранением: учебное пособие. М., 2004: 194.
10.Altman D.G. How large a sample? In: Gore SM, Altman DG (eds.). Statistics in Practice. London, UK: British Medical Association. 1982: 100.
11.Whitley E., Ball J. Statistics review 4: Sample size calculations. Critical Care. 2002; 6 (4): 335-341.
12.Lehr R. Sixteen s-squared over d-squared: a relation for crude sample size estimates. Statistics in medicine. 1992; (11): 1099-1102.
References
1. Machin D., Campbell M., Fayers P., Pinol A. Sample size tables for clinical studies. 3nd ed. Oxford: Blackwell Science. 2009: 315.
2. Chow Sh.-Ch., Shao J., Wang H. Sample size calculations in clinical research. New-York: Marcel Dekker, Inc. 2003: 358.
3. Rohrig B., Prel J.-B., Wachtlin D., Kwiecien R., Blettner M. Sample Size Calculation in Clinical Trials. Part 13 of a Series on Evaluation of Scientific Publications. Deutsches Arzteblatt International. 2021; 107 (31-32): 552-556.
4. Whitley E., Ball J. Statistics review 2: Samples and populations. Critical Care. 2002; 6 (2): 143-148.
5. Narkevich A.N., Vinogradov K.A. Nastol’naya kniga avtora meditsinskoy dissertatsii: posobie [Handbook of the author of the medical dissertation. Manual]. Moscow, Infra-M. 2021: 454. (In Russian).
6. Otdel’nova K. A. Opredelenie neobkhodimogo chisla nablyudeniy v sotsial’no-gigienicheskikh issledovaniyakh [Determination of the required number of observations in social and hygienic studies]. Sb. trudov 2-go MMI. 1980; 150 (6): 18-22. (In Russian).
7. Paniotto V. I., Maksimenko V. S. Kolichestvennye metody v sotsiologicheskikh issledovaniyakh [Quantitative methods in sociological research]. Kiev: Naukova Dumka. 1982: 272. (In Russian).
8. Fox N., Hunn A., Mathers N. Sampling and sample size calculation. -Yorkshire & the Humber: The NIHR RDS for the East Midlands. 2007: 41.
9. Syrtsova L.E., Kosagovskaya I.I., Avsent’eva M.V. Osnovy epidemiologii i statisticheskogo analiza v obshchestvennom zdorov’e i upravlenii zdravookhraneniem: uchebnoe posobie [Fundamentals of epidemiology and statistical analysis in public health and healthcare management. A training manual]. Moscow, 2004: 194. (In Russian).
10.Altman D.G. How large a sample? In: Gore SM, Altman DG (eds.). Statistics in Practice. London, UK: British Medical Association. 1982: 100.
11.Whitley E., Ball J. Statistics review 4: Sample size calculations. Critical Care. 2002; 6 (4): 335-341.
12.Lehr R. Sixteen s-squared over d-squared: a relation for crude sample size estimates. Statistics in medicine. 1992; (11): 1099-1102.
Дата поступления: 22.09.2021
Определение минимального объема выборки
Для определения вероятностей интересующих нас событий мы применяем выборочный метод: проводим n независимых экспериментов, в каждом из которых может произойти (или не произойти) событие А (вероятность р появления события А в каждом эксперименте постоянна). Тогда относительная частота p* появлений событий А в серии из n испытаний принимается в качестве точечной оценки для вероятности p появления события А в отдельном испытании. При этом величину p* называют выборочной долей появлений события А, а р — генеральной долей.
В силу следствия из центральной предельной теоремы (теорема Муавра-Лапласа) относительную частоту события при большом объеме выборки можно считать нормально распределенной с параметрами M(p*)=p и ![]()
Поэтому при n>30 доверительный интервал для генеральной доли можно построить, используя формулы:
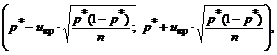
где uкрнаходится по таблицам функции Лапласа с учетом заданной доверительной вероятности γ: 2Ф(uкр)=γ.
При малом объеме выборки n≤30 предельная ошибка ε определяется по таблице распределения Стьюдента:
![]() где tкр=t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
где tкр=t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
Формулы справедливы, если отбор проводился случайным повторным образом (генеральная совокупность бесконечна), в противном случае необходимо сделать поправку на бесповторность отбора (таблица).
Средняя ошибка выборки для генеральной доли
Формулы расчета численности выборки при собственно-случайном способе отбора
На вопрос «Накрывает ли доверительный интервал заданное значение p0?» — можно ответить, проверив статистическую гипотезу H0:p=p0. При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p* появления события A:![]() где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
Таблица 1 – Гипотезы о генеральной доле
Пример №1. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал, с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
![]()
Значение uкр находим по таблице функции Лапласа из соотношения 2Ф(uкр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка ![]() и искомый доверительный интервал
и искомый доверительный интервал
(p – ε, p ε) = (0.3 – 0.18; 0.3 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение. Выборочная доля «удачных» дней составляет ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности ![]()
Ф(2.23) = 0.49, uкр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40, N = 365 (дней). Отсюда ![]()
и доверительный интервал для генеральной доли: (p – ε, p ε) = (0.6 – 0.17; 0.6 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение. Сформулируем основную и альтернативную гипотезы.
H0:p=p0=0,97 — неизвестная генеральная доля p равна заданному значению p0=0,97. Применительно к условию — вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H1:p<0,97 – вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K (таблица) вычислим при заданных значениях p0=0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-Kkp)= (-∞;-2,05). Наблюдаемое значение Кнабл=-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода — 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
Решение. Это задача о сравнении генеральных долей двух совокупностей. Сформулируем основную и альтернативную гипотезы.
H0:p1=p2 — генеральные доли равны. Применительно к условию — вероятность появления бракованного изделия в продукции первого завода равна вероятности появления бракованного изделия в продукции второго завода (качество продукции одинаково).
H0:p1≠p2 — заводы изготавливают детали разного качества.
Для вычисления наблюдаемого значения статистики K (таблица) рассчитаем оценки по выборке.
![]()
![]()
Наблюдаемое значение равно

Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства ![]()
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение Kнабл=2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
Поправка на ветер
На самом деле нет никаких причин, полагать, что нам будет известна σ (дисперсия), в то время как μ (среднее) нам еще только предстоит оценить. Из-за этого уравнение 4 имеет мало практической пользы, кроме особо рафинированных примеров из области комбинаторики, а реалистичное уравнение для n несколько сложнее при неизвестной σ (Ур. 5).
Обратите внимание, что σ в последнем уравнении не с шапкой (^), а тильдой (~). Это следствие того, что в самом начале у нас нет даже оценочного стандартного отклонения случайной выборки —  запланированное —
запланированное — 
 поправка Гюнтера.
поправка Гюнтера.
Помимо уравнений 4 и 5 есть еще несколько приблизительно-оценочных формул, но это уже заслуживает отдельного поста.
Практика — считаем с r
Проверим гипотезу о том, что среднее значение данной выборки количества насекомых в ловушке равно 1.
> x <- read.table("/tmp/tcounts.txt")
> y = unlist(x, use.names="false")
> mean(z);sd(z)
[1] 1.636364
[1] 1.654883Обратите внимание, что среднее и стандартное отклонение практически равны, что естественно для распределения Пуассона. Доверительный интервал 95% для t-статистики Стьюдента и df=32.
> qt(.975, 32)
[1] 2.036933и наконец получаем критический интервал для среднего значения: 1.05 — 2.22.
> μ=mean(z)
> st = qt(.975, 32)
> μ st * sd(z)/sqrt(33)
[1] 2.223159
> μ - st * sd(z)/sqrt(33)
[1] 1.049568В итоге, следует отбраковать H0 и принять H1 так как с вероятностью 95%, μ > 1.
В том же самом примере, если принять, что нам известно действительное стандартное отклонение — σ, а не ее оценка полученная с помощью случайной выборки, можно рассчитать необходимое n для данной погрешности. Посчитаем для E=0.5.
> za2 = qnorm(.975)
> (za2*sd(z)/.5)^2
[1] 42.08144Теоретический минимум
Не будет лишним освежить память, эти термины нам пригодятся далее.
Уже в самих определениях ошибки первого и второго рода имеется простор для дебатов и толкований. Как с ними определиться и какую выбрать в качестве нулевой? Если вы исследуете уровень загрязнения почвы или вод, то как сформулируете нулевую гипотезу: загрязнение присутствует, или нет загрязнения? А ведь от этого зависит объем выборки из общей популяции объектов.
Исходная популяция, также как и выборка может иметь любое распределение, однако среднее значение имеет нормальное или гауссово распределение благодаря Центральной Предельной Теореме.
Относительно параметров распределения и среднего значения в частности возможно несколько типов умозаключений. Первое из них называется доверительным интервалом. Он указывает на интервал возможных значений параметра, с указанным коэффициентом доверия. Так например 100(1-α)%доверительный интервал для μ будет таким (Ур. 1).
Второе из умозаключений — проверка гипотезы. Оно может быть примерно таким.
С доверительным интервалом100(1-α) для μ можно сделать выбор в пользу H1 и H2 :
Если нам нужно проверить значение μ для одной выборки из общей совокупности, то критерий обретет вид.
Где 





