

Многофункциональные статистические критерии

ГЛАВА 5
МНОГОФУНКЦИОНАЛЬНЫЕ СТАТИСТИЧЕСКИЕ КРИТЕРИИ
5.1. Понятие многофункциональных критериев
Многофункциональные статистические критерии – это критерии, которые могут использоваться по отношению к самым разнообразным | данным, выборкам и задачам.
Это означает, что данные могут быть представлены в любой шкале, начиная от номинативной (шкалы наименований).
Это означает также, что выборки могут быть как независимыми, так и “связанными”, то есть мы можем с помощью многофункциональных критериев сравнивать и разные выборки испытуемых, и показатели одной и той же выборки, измеренные в разных условиях. Нижние границы выборок – 5 наблюдений, но возможно применение критериев и по отношению к выборкам с п=2, с некоторыми оговорками (см. разделы “Ограничения критерия φ*” и “Ограничения биномиального критерия m”)
Верхняя граница выборок задана только в биномиальном критерии – 50 человек. В критерии φ* Фишера верхней границы не существует – выборки могут быть сколь угодно большими.
Многофункциональные критерии позволяют решать задачи сопоставления уровней исследуемого признака, сдвигов в значениях исследуемого признака и сравнения распределений.
К числу многофункциональных критериев в полной мере относится критерий φ* Фишера (угловое преобразование Фишера) и, с некоторыми оговорками – биномиальный критерий m.
Многофункциональные критерии построены на сопоставлении долей, выраженных в долях единицы или в процентах. Суть критериев [состоит в определении того, какая доля наблюдений (реакций, выборов, испытуемых) в данной выборке характеризуется интересующим исследователя эффектом и какая доля этим эффектом не характеризуется.
Таким эффектом может быть:
a) определенное значение качественно определяемого признака – например, выражение согласия с каким-либо предложением; выбор правой дорожки из двух симметричных дорожек; отнесенность к определенному полу; присутствие фигуры отца в раннем воспоминании и др.
б) определенный уровень количественно измеряемого признака, например, получение оценки, превосходящей проходной балл; решение задачи менее чем за 20 сек; факт работы в команде, по численности превышающей 4-х человек; выбор дистанции в разговоре, превышающей 50 см, и др.
в) определенное соотношение значений или уровней исследуемого признака, например, более частый выбор альтернатив А и Б по сравнению с альтернативами В и Г; преимущественное проявление крайних значений признака, как самых высоких, так и самых низких; преобладание положительных сдвигов над отрицательными и др.
Итак, путем сведения любых данных к альтернативной шкале “Есть эффект – нет аффекта” многофункциональные критерии позволяют решать все три задачи сопоставлений – сравнения “уровней”, оценки “сдвигов” и сравнения распределений.
Критерий φ* применяется в тех случаях, когда обследованы две выборки испытуемых, биномиальный критерий m – в тех случаях, когда обследована лишь одна выборка испытуемых. Правила выбора одного из этих критериев отражены в Алгоритме 19.
5.2. Критерий φ* — угловое преобразование Фишера
Данный метод описан во многих руководствах (Плохинский Н.А., 1970; Гублер Е.В., 1978; Ивантер Э.В., Коросов А.В., 1992 и др.) Настоящее описание опирается на тот вариант метода, который был разработан и изложен Е.В. Гублером.
Назначение критерия φ*
Критерий Фишера предназначен для сопоставления двух выборок по частоте встречаемости интересующего исследователя эффекта.
Описание критерия
Критерий оценивает достоверность различий между процентными долями двух выборок, в которых зарегистрирован интересующий нас эффект.
Суть углового преобразования Фишера состоит в переводе процентных долей в величины центрального угла , который измеряется в радианах . Большей процентной доле будет соответствовать больший угол ф, а меньшей доле – меньший угол, но соотношения здесь не линейные:
![]()
где Р – процентная доля, выраженная в долях единицы (см. Рис. 5.1).

При увеличении расхождения между углами φ1 и φ2 и увеличения численности выборок значение критерия возрастает. Чем больше величина φ* , тем более вероятно, что различия достоверны.
Гипотезы
H0: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 не больше, чем в выборке 2.
H1: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 больше, чем в выборке 2.
Графическое представление критерия φ*
Метод углового преобразования несколько более абстрактен, чем остальные критерии.
Формула, которой придерживается Е. В. Гублер при подсчете значений φ, предполагает, что 100% составляют угол φ=3,142, то есть округленную величину π=3,14159… Это позволяет нам представить сопоставляемые выборки в виде двух полукругов, каждый из которых символизирует 100% численности своей выборки. Процентные доли испытуемых с “эффектом” будут представлены как секторы, образованные центральными углами φ. На Рис. 5.2 представлены два полукруга, иллюстрирующие Пример 1. В первой выборке 60% испытуемых решили задачу. Этой процентной доле соответствует угол φ=1,772. Во второй выборке 40% испытуемых решили задачу. Этой процентной доле соответствует угол φ =1,369.

Критерий φ* позволяет определить, действительно ли один из углов статистически достоверно превосходит другой при данных объемах выборок.
Ограничения критерия φ*
1. Ни одна из сопоставляемых долей не должна быть равной нулю. Формально нет препятствий для применения метода φ в случаях, когда доля наблюдений в одной из выборок равна 0. Однако в этих случаях результат может оказаться неоправданно завышенным (Гублер Е.В., 1978, с. 86).
2. Верхний предел в критерии φ отсутствует – выборки могут быть сколь угодно большими.
Нижний предел – 2 наблюдения в одной из выборок. Однако должны соблюдаться следующие соотношения в численности двух выборок:
а) если в одной выборке всего 2 наблюдения, то во второй должно быть не менее 30:
![]()
б) если в одной из выборок всего 3 наблюдения, то во второй должно быть не менее 7:
![]()
в) если в одной из выборок всего 4 наблюдения, то во второй должно быть не менее 5:
![]()
г) при n1,n2≥5 возможны любые сопоставления.
В принципе возможно и сопоставление выборок, не отвечающих этому условию, например, с соотношением n1=2, n2=15, но в этих случаях не удастся выявить достоверных различий.
Других ограничений у критерия φ* нет.
Рассмотрим несколько примеров, иллюстрирующих возможности
критерия φ*.
Пример 1: сопоставление выборок по качественно определяемому признаку.
Пример 2: сопоставление выборок по количественно измеряемому признаку.
Пример 3: сопоставление выборок и по уровню, и по распределению признака.
Пример 4: использование критерия φ* в сочетании с критерием XКолмогорова-Смирнова в целях достижения максимально точного результата.
Пример 1 – сопоставление выборок по качественно определяемому признаку
В данном варианте использования критерия мы сравниваем процент испытуемых в одной выборке, характеризующихся каким-либо качеством, с процентом испытуемых в другой выборке, характеризующихся тем же качеством.
Допустим, нас интересует, различаются ли две группы студентов по успешности решения новой экспериментальной задачи. В первой группе из 20 человек с нею справились 12 человек, а во второй выборке из 25 человек – 10. В первом случае процентная доля решивших задачу составит 12/20·100%=60%, а во второй 10/25·100%=40%. Достоверно ли различаются эти процентные доли при данных n1и n2?
Казалось бы, и “на глаз” можно определить, что 60% значительно выше 40%. Однако на самом деле эти различия при данных n1, n2 недостоверны.
Проверим это. Поскольку нас интересует факт решения задачи, будем считать “эффектом” успех в решении экспериментальной задачи, а отсутствием эффекта – неудачу в ее решении.
Сформулируем гипотезы.
H0: Доля лиц,справившихся с задачей, в первой группе не больше, чем во второй группе.
H1: Доля лиц, справившихся с задачей, в первой группе больше, чем во второй группе.
Теперь построим так называемую четырехклеточную, или четырехпольную таблицу, которая фактически представляет собой таблицу эмпирических частот по двум значениям признака: “есть эффект” – “нет эффекта”.
Таблица 5.1
Четырехклеточная таблица для расчета критерия при сопоставлении двух групп испытуемых по процентной доле решивших задачу.
| Группы | “Есть эффект”: задача решена | “Нет эффекта”: задача не решена | Суммы | ||||
| Количество испытуемых | % доля | Количество испытуемых | % доля | ||||
| 1 группа | 12 | (60%) | А | 8 | (40%) | Б | 20 |
| 2jЈynna | 10 | (40%) | В | 15 | (60%) | Г | 25 |
| Суммы | 22 | 23 | 45 | ||||
В четырехклеточной таблице, как правило, сверху размечаются столбцы “Есть эффект” и “Нет эффекта”, а слева – строки “1 группа” и “2 группа”. Участвуют в сопоставлениях, собственно, только поля (ячейки) А и В, то есть процентные доли по столбцу “Есть эффект”.
По Табл. XII Приложения 1 определяем величины φ, соответствующие процентным долям в каждой из групп.
![]()
Теперь подсчитаем эмпирическое значение φ* по формуле:
![]()
где φ1 – угол, соответствующий большей % доле;
φ2 – угол, соответствующий меньшей % доле;
n1 – количество наблюдений в выборке 1;
n2 – количество наблюдений в выборке 2.
В данном случае:
![]()
По Табл. XIII Приложения 1 определяем, какому уровню значимости соответствует φ*эмп=1,34:
р=0,09
Можно установить и критические значения φ*, соответствующие принятым в психологии уровням статистической значимости:

Построим “ось значимости”.

Полученное эмпирическое значение φ* находится в зоне незначимости.
Ответ: H0принимается. Доля лиц, справившихся с задачей, в первой группе не больше, чем во второй группе.
Можно лишь посочувствовать исследователю, который считает существенными различия в 20% и даже в 10%, не проверив их достоверность с помощью критерия φ*. В данном случае, например, достоверными были бы только различия не менее чем в 24,3%.
Похоже, что при сопоставлении двух выборок по какому-либо качественному признаку критерий φ может нас скорее огорчить, чем обрадовать. То, что казалось существенным, со статистической точки зрения может таковым не оказаться.
Гораздо больше возможностей порадовать исследователя появляется у критерия Фишера тогда, когда мы сопоставляем две выборки по количественно измеренным признакам и можем варьировать “эффект .
Пример 2 – сопоставление двух выборок по количественно измеряемому признаку
В данном варианте использования критерия мы сравниваем процент испытуемых в одной выборке, которые достигают определенного уровня значения признака, с процентом испытуемых, достигающих этого уровня в другой выборке.
В исследовании Г. А. Тлегеновой (1990) из 70 юношей – учащихся ПТУ в возрасте от 14 до 16 лет было отобрано по результатам обследования по Фрайбургскому личностному опроснику 10 испытуемых с высоким показателем по шкале Агрессивности и 11 испытуемых с низким показателем по шкале Агрессивности. Необходимо определить, различаются ли группы агрессивных и неагрессивных юношей по показателю расстояния, которое они спонтанно выбирают в разговоре с сокурсником. Данные Г. А. Тлегеновой представлены в Табл. 5.2. Можно заметить, что агрессивные юноши чаще выбирают расстояние в 50 см или даже меньше, в то время как неагрессивные юноши чаще выбирают расстояние, превышающее 50 см.
Теперь мы можем рассматривать расстояние в 50 см как критическое и считать, что если выбранное испытуемым расстояние меньше или равно 50 см, то “эффект есть”, а если выбранное расстояние больше 50 см, то “эффекта нет”. Мы видим, что в группе агрессивных юношей эффект наблюдается в 7 из 10, т. е. в 70% случаев, а в группе неагрессивных юношей – в 2 из 11, т. е. в 18,2% случаев. Эти процентные доли можно сопоставить по методу φ* , чтобы установить достоверность различий между ними.
Таблица 5.2
Показатели расстояния (в см), выбираемого агрессивными и неагрессивными юношами в разговоре с сокурсником (по данным Г.А. Тлегеновой, 1990)
| Группа 1: юноши с высокими показателями по шкале Агрессивности FPI-R1 (n1 =10) | Группа 2: юноши с низкими значениями по шкале Агрессивности FPI-R (n2 =11) | |||
| d(cм) | % доля | d(cM) | % доля | |
| “Есть эффект” d≤50 см | 30 | |||
| 40 | 40 | |||
| 45 | ||||
| 50 | 70% | 18,2% | ||
| 50 | ||||
| 50 | ||||
| 50 | ||||
| 50 | ||||
| “Нет эффекта” d>50 см | 65 | |||
| 70 | ||||
| 75 | ||||
| 75 | ||||
| 75 | ||||
| 75 | ||||
| 80 QO | 30% | . 81,8% | ||
| 100 | ||||
| 100 | ||||
| 100 | ||||
| 100 | ||||
| Суммы | 560 | 100% | 850 | 100% |
| Средние | 5б:о | 77.3 | ||
Сформулируем гипотезы.
H0: Доля лиц, которые выбирают дистанцию d≤50 см, в группе агрессивных юношей не больше, чем в группе неагрессивных юношей.
H1: Доля лиц, которые выбирают дистанцию d≤50 см, в группе агрессивных юношей больше, чем в группе неагрессивных юношей. Теперь построим так называемую четырехклеточную таблицу.
Таблица 53
Четырехклеточная таблица для расчета критерия φ* при сопоставлении групп агрессивных (nf=10) и неагрессивных юношей (п2=11)
| Группы | “Есть эффект”: d≤50 | “Нет эффекта”. d>50 | Суммы | ||||
| Количество испытуемых | (% доля) | Количество испытуемых | (% доля) | ||||
| 1 группа -агрессивные юноши | 7 | (70%) | А | 3 | (30%) | Б | 10 |
| 2 группа -неагрессивные юноши | 2 | (180%) | В | 9 | (81,8%) | Г | и |
| Сумма | 9 | 12 | 21 | ||||
По Табл. XII Приложения 1 определяем величины φ, соответствующие процентным долям “эффекта” в каждой из групп.

Полученное эмпирическое значение φ* находится в зоне значимости.
Ответ: H0 отвергается. Принимается H1. Доля лиц, которые выбирают дистанцию в беседе меньшую или равную 50 см, в .группе агрессивных юношей больше, чем в группе неагрессивных юношей
На основании полученного результата мы можем сделать заключение, что более агрессивные юноши чаще выбирают расстояние менее полуметра, в то время как неагрессивные юноши чаще выбирают большее, чем полметра, расстояние. Мы видим, что агрессивные юноши общаются фактически на границе интимной (0—46 см) и личной зоны (от 46 см). Мы помним, однако, что интимное расстояние между партнерами является прерогативой не только близких добрых отношений, но и рукопашного боя (Hall E.T., 1959).
следующая страница >>
§
Пример 3 – сопоставление выборок и по уровню, и по распределению признака.
В данном варианте использования критерия мы вначале можем проверить, различаются ли группы по уровню какого-либо признака, а затем сравнить распределения признака в двух выборках. Такая задача может быть актуальной при анализе различий в диапазонах или форме распределения оценок, получаемых испытуемыми по какой-либо новой методике.
В исследовании Р. Т. Чиркиной (1995) впервые использовался опросник, направленный на выявление тенденции к вытеснению из памяти фактов, имен, намерений и способов действия, обусловленному личными, семейными и профессиональными комплексами. Опросник был создан при участии Е. В. Сидоренко на основании материалов книги 3. Фрейда “Психопатология обыденной жизни”. Выборка из 50 студентов Педагогического института, не состоящих в браке, не имеющих детей, в возрасте от 17 до 20 лет, была обследована с помощью данного опросника, а также методики Менестера-Корзини для выявления интенсивности ощущения собственной недостаточности, или “комплекса неполноценности” (Manaster G. J., Corsini R. J., 1982).
Результаты обследования представлены в Табл. 5.4.
Можно ли утверждать, что между показателем энергии вытеснения, диагностируемым с помощью опросника, и показателями интенсивности, ощущения собственной недостаточности существуют какие-либо значимые соотношения?
Таблица 5.4
Показатели интенсивности ощущения собственной недостаточности в группах студентов с высокой (nj=18) и низкой (п2=24) энергией вытеснения
| Группа 1: энергия вытеснения от 19 до 31 балла (n1=181 | Группа 2: энергия вытеснения от 7 до 13 баллов (n2=24) | |
| 0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 | |
| Суммы Средние | 470 26,11 | 370 15,42 |
Несмотря на то, что средняя величина в группе с более энергичным вытеснением выше, в ней наблюдаются также и 5 нулевых значений. Если сравнить гистограммы распределения оценок в двух выборках, то между ними обнаруживается разительный контраст (Рис. 5.3).

Для сравнения двух распределений мы могли бы применить критерий χ2 или критерий λ, но для этого нам пришлось бы укрупнять разряды, а кроме того, в обеих выборках n<30.>
Критерий φ* позволит нам проверить наблюдаемый на графике эффект несовпадения двух распределений, если мы условимся считать, что “эффект есть”, если показатель чувства недостаточности принимает либо очень низкие (0), либо, наоборот, очень высокие значения (S30), и что “эффекта нет”, если показатель чувства недостаточности принимает средние значения, от 5 до 25.
Сформулируем гипотезы.
H0: Крайние значения показателя недостаточности (либо 0, либо 30 и более) в группе с более энергичным вытеснением встречаются не чаще, чем в группе с менее энергичным вытеснением.
H1:Крайние значения показателя недостаточности (либо 0, либо 30 и более) в группе с более энергичным вытеснением встречаются чаще, чем в группе с менее энергичным вытеснением.
Создадим четырехклеточную таблицу, удобную для дальнейшего расчета критерия φ*.
Таблица 5.5
Четырехклеточная таблица для расчета критерия φ*при сопоставлении групп с большей и меньшей энергией вытеснения по соотношению показателей недостаточности
| Группы | “Есть эффект”: показатель недостаточности равен 0 или >30 | “Нет эффекта”: показатель недостаточности от 5 до 25 | Суммы | ||
| 1 группа – с большей энергией вытеснения | 16 | (88,9%) | 2 | (11,1%) | 18 |
| 2 группа – с меньшей энергией вытеснения | 8 | (33,3%) | 16 | (66,7%) | 24 |
| Суммы | 24 | 18 | 422 | ||
По Табл. XII Приложения 1 определим величины ф, соответствующие сопоставляемым процентным долям:
![]()
Подсчитаем эмпирическое значение φ*:

Критические значения φ* при любых n1, n2, как мы помним из предыдущего примера, составляют:

Табл. XIII Приложения 1 позволяет нам и более точно определить уровень значимости полученного результата: р<0,001.
Ответ: H0отвергается. Принимается H1. Крайние значения показателя недостаточности (либо 0, либо 30 и более) в группе с большей энергией вытеснения встречаются чаще, чем в группе с меньшей энергией вытеснения.
Итак, испытуемые с большей- энергией вытеснения могут иметь как очень высокие (30 и более), так и очень низкие (нулевые) показатели ощущения собственной недостаточности. Можно предположить, что они вытесняют и свою неудовлетворенность, и потребность в жизненном успехе. Эти предположения нуждаются в дальнейшей проверке.
Полученный результат, независимо от его интерпретации, подтверждает возможности критерия φ* в оценке различий в форме распределения признака в двух выборках.
В мощных возможностях критерия φ* можно убедиться, подтвердив совершенно иную гипотезу при анализе материалов данного примера. Мы можем доказать, например, что в группе с большей энергией вытеснения показатель недостаточности все же выше, несмотря на парадоксальность его распределения в этой группе.
Сформулируем новые гипотезы.
H0Наиболее высокие значения показателя недостаточности (30 и более) в группе с большей энергией вытеснения встречаются не чаще, чем в группе с меньшей энергией вытеснения.
H1: Наиболее высокие значения показателя недостаточности (30 и более) в группе с большей энергией вытеснения встречаются чаще, чем в группе с меньшей энергией вытеснения. Построим четырехпольную таблицу, используя данные Табл. 5.4.
Таблица 5.6
Четырехклеточная таблица для расчета критерия φ* при сопоставлении групп с большей и меньшей энергией вытеснения по уровню показателя недостаточности
| Группы | “Есть эффект”* показатель недостаточности больше или равен 30 | “Нет эффекта”: показатель недостаточности меньше 30 | Суммы | ||
| 1 группа – с большей энергией вытеснения | 11 | (61,1%) | 7 | (38.9%) | 18 |
| 2 группа – с меньшей энергией вытеснения | 6 | (25.0%) | 18 | (75.0%) | 24 |
| Суммы | 17 | 25 | 42 | ||

По Табл. XIII Приложения 1 определяем, что этот результат соответствует уровню значимости р=0,008.
Ответ: Но отвергается. Принимается Hj: Наиболее высокие показатели недостаточности (30 и более баллов) в группе с большей энергией вытеснения встречаются чаще, чем в группе с меньшей энергией вытеснения (р=0,008).
Итак, нам удалось доказать и то, что в группе с более энергичным вытеснением преобладают крайние значения показателя недостаточности, и то, что больших своих значений этот показатель достигает именно в этой группе.
Теперь мы могли бы попробовать доказать, что в группе с большей энергией вытеснения чаще встречаются и более низкие значения показателя недостаточности, несмотря на то, что средняя величина в этой группе больше (26,11 против 15,42 в группе с меньшим вытеснением).
Сформулируем гипотезы.
H0: Самые низкие показатели недостаточности (нулевые) в группе с большей энергией вытеснения встречаются не чаще, чем в группе с меньшей энергией вытеснения.
H1: Самые низкие показатели недостаточности (нулевые) встречаются в группе с большей энергией вытеснения чаще, чем в группе с менее энергичным вытеснением. Сгруппируем данные в новую четырехклеточную таблицу.
Таблица 5.7
Четырехклеточная таблица для сопоставления групп с разной энергией вытеснения по частоте нулевых значений показателя недостаточности
| Группы | “Есть эффект”: показатель недостаточности равен 0 | “Нет эффекта” недостаточности | показатель не равен 0 | Суммы | |
| 1 группа – с большей энергией вытеснения | 5 | (27,8%) | 13 | (72,2%) | 18 |
| 1 группа – с меньшей энергией вытеснения | 2 | (8,3%) | 22 | (91,7%) | 24 |
| Суммы | 7 | 35 | 42 | ||
Определяем величины φ и подсчитываем значение φ*:

Ответ: H0отвергается. Самые низкие показатели недостаточности (нулевые) в группе с большей энергией вытеснения встречаются чаще, чем в группе с меньшей энергией вытеснения (р<0,05).
В сумме полученные результаты могут рассматриваться как свидетельство частичного совпадения понятий комплекса у З.Фрейда и А.Адлера.
Существенно при этом, что между показателем энергии вытеснения и показателем интенсивности ощущения собственной недостаточности в целом по выборке получена положительная линейная корреляционная связь (р= 0,491, р<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Пример 4 – использование критерия φ* в сочетании с критерием λ Колмогорова-Смирнова в целях достижения максимально точного результата
Если выборки сопоставляются по каким-либо количественно измеренным показателям, встает проблема выявления той точки распределения, которая может использоваться как критическая при разделении всех испытуемых на тех, у кого “есть эффект” и тех, у кого “нет эффекта”.
В принципе точку, по которой мы разделили бы группу на подгруппы, где есть эффект и нет эффекта, можно выбрать достаточно произвольно. Нас может интересовать любой эффект и, следовательно, мы можем разделить обе выборки на две части в любой точке, лишь бы это имело какой-то смысл.
Для того, чтобы максимально повысить мощность критерия φ*, нужно, однако, выбрать точку, в которой различия между двумя сопоставляемыми группами являются наибольшими. Точнее всего мы сможем сделать это с помощью алгоритма расчета критерия λ, позволяющего обнаружить точку максимального расхождения между двумя выборками.
Возможность сочетания критериев φ* и λописана Е.В. Гублером (1978, с. 85-88). Попробуем использовать этот способ в решении следующей задачи.
В совместном исследовании М.А. Курочкина, Е.В. Сидоренко и Ю.А. Чуракова (1992) в Великобритании проводился опрос английских общепрактикующих врачей двух категорий: а) врачи, поддержавшие медицинскую реформу и уже превратившие свои приемные в фондодержащие организации с собственным бюджетом; б) врачи, чьи приемные по-прежнему не имеют собственных фондов и целиком обеспечиваются государственным бюджетом. Опросники были разосланы выборке из 200 врачей, репрезентативной по отношению к генеральной совокупности английских врачей по представленности лиц разного пола, возраста, стажа и места работы – в крупных городах или в провинции.
Ответы на опросник прислали 78 врачей, из них 50 работающих в приемных с фондами и 28 – из приемных без фондов. Каждый из врачей должен был прогнозировать, какова будет доля приемных с фондами в следующем, 1993 году. На данный вопрос ответили только 70 врачей из 78, приславших ответы. Распределение их прогнозов представлено в Табл. 5.8 отдельно для группы врачей с фондами и группы врачей без фондов.
Различаются ли каким-то образом прогнозы врачей с фондами и врачей без фондов?
Таблица 5.8
Распределение прогнозов сбщепрактикующих врачей о том, какова будет доля приемных с фондами в 1993 году
| Прогнозируемая доля | Эмпирические частоты выбора данной категории прогноза | ||
| приемных с фондами | врачами с фондом (n1=45) | врачами без фонда (n2 =25) | Суммы |
| 1. от 0 до 20% | 4 | 5 | 9 |
| 2. от 21 до 40% | 15 | И | 26 |
| 3. от 41 до 60% | 18 | 5 | 23 |
| 4. от 61 до 80% | 7 | 4 | И |
| 5. от 81 до 100% | 1 | 0 | 1 |
| Суммы | 45 | 25 | 70 |
Определим точку максимального расхождения между двумя распределениями ответов по Алгоритму 15 из п. 4.3 (см. Табл. 5.9).
Таблица 5.9
Расчет максимальной разности накопленных частостей в распределениях прогнозов врачей двух групп
| Прогнозируемая доля приемных с фондами (%) | Эмпирические частоты выбора данной категории ответа | Эмпирические частости | Накопленные эмпирические частости | Разность (d) | |||
| врачами с фондом (n1=45) | врачами без фонда (n2=25) | f*э1 | f*a2 | ∑f*э1 | ∑f*а1 | ||
| 1. от 0 до 20% 2. от 21 до 40% 3. от 41 до 60% 4. от 61 до 80% 5. от 81 до 100% | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
Максимальная выявленная между двумя накопленными эмпирическими частостями разность составляет 0,218.
Эта разность оказывается накопленной во второй категории прогноза. Попробуем использовать верхнюю границу данной категории в качестве критерия для разделения обеих выборок на подгруппу, где “есть эффект” и подгруппу, где “нет эффекта”. Будем считать, что “эффект есть”, если данный врач прогнозирует от 41 до 100% приемных с фондами в 1993 году, и что “эффекта нет”, если данный врач прогнозирует от 0 до 40% приемных с фондами в 1993 году. Мы объединяем категории прогноза 1 и 2, с одной стороны, и категории прогноза 3, 4 и 5, с другой. Полученное распределение прогнозов представлено в Табл. 5.10.
Таблица 5.10
Распределение прогнозов у врачей с фондами и врачей без фондов
| Прогнозируемая доля приемных с фондами(%1 | Эмпирические частоты выбора данной категории прогноза | Суммы | |
| врачами с фондом (n1=45) | врачами без фонда (n2=25) | ||
| 1. от 0 до 40% | 19 | 16 | 35 |
| 2. от 41 до 100% | 26 | 9 | 35 |
| Суммы | 45 | 25 | 70 |
Полученную таблицу (Табл. 5.10) мы можем использовать, проверяя разные гипотезы путем сопоставления любых двух ее ячеек. Мы помним, что это так называемая четырехклеточная, или четырехпольная, таблица.
В данном случае нас интересует, действительно ли врачи, уже располагающие фондами, прогнозируют больший размах этого движения в будущем, чем врачи, не располагающие фондами. Поэтому мы условно считаем, что “эффект есть”, когда прогноз попадает в категорию от 41 до 100%. Для упрощения расчетов нам необходимо теперь повернуть таблицу на 90°, вращая ее по направлению часовой стрелки. Можно сделать это даже буквально, повернув книгу вместе с таблицей. Теперь мы можем перейти к рабочей таблице для расчета критерия φ* – углового преобразования Фишера.
Таблица 5.11
Четырехклеточная таблица для подсчета критерия φ* Фишера для выявления различий в прогнозах двух групп общепрактикующих врачей
| Группа | Есть эффект -прогноз от 41 до 100% | Нет эффекта -прогноз от 0 до 40% | Всего |
| I группа – врачи, взявшие фонд | 26 (57.8%) | 19 (42.2%) | 45 |
| II группа – врачи, не взявшие фонда | 9 (36.0%) | 16 (64.0%) | 25 |
| Всего | 35 | 35 | 70 |
Сформулируем гипотезы.
H0: Доля лиц, прогнозирующих распространение фондов на 41%-100% всех врачебных приемных, в группе врачей с фондами не больше, чем в группе врачей без фондов.
H1: Доля лиц, прогнозирующих распространение фондов на 41%-100% всех приемных, в группе врачей с фондами больше, чем в группе врачей без фондов.
Определяем величины φ1 и φ2 по Таблице XII приложения 1. Напомним, что φ1 – это всегда угол, соответствующий большей процентной доле.
![]()
Теперь определим эмпирическое значение критерия φ*:
![]()
По Табл. XIII Приложения 1 определяем, какому уровню значимости соответствует эта величина: р=0,039.
По той же таблице Приложения 1 можно определить критические значения критерия φ*:

Ответ: Но отвергается (р=0,039). Доля лиц, прогнозирующих распространение фондов на 41-100% всех приемных, в группе врачей, взявших фонд, превышает эту долю в группе врачей, не взявших фонда.
Иными словами, врачи, уже работающие в своих приемных на отдельном бюджете, прогнозируют более широкое распространение этой практики в текущем году, чем врачи, пока еще не согласившиеся перейти на самостоятельный бюджет. Интерпретации этого результата многозначны. Например, можно предположить, что врачи каждой из групп подсознательно считают свое поведение более типичным. Это может означать также, что врачи, уже перешедшие на самостоятельный бюджет, склонны преувеличивать размах этого движения, так как им нужно оправдать свое решение. Выявленные различия могут означать и нечто такое, что вовсе выходит за рамки поставленных в исследовании вопросов. Например, что активность врачей, работающих на самостоятельном бюджете, способствует заострению различий в позициях обеих групп. Они проявили большую активность, когда согласились взять фонды, они проявили большую активность, когда взяли на себя труд ответить на почтовый опросник; они проявляют большую активность, когда прогнозируют большую активность других врачей в получении фондов.
Так или иначе, мы можем быть уверены, что выявленный уровень статистических различий – максимально возможный для этих реальных данных. Мы установили с помощью критерия λточку максимального расхождения между двумя распределениями и именно в этой точке разделили выборки на две части.
<< предыдущая страница следующая страница >>
§
АЛГОРИТМ 17
Расчет критерия φ*
1. Определить те значения признака, которые будут критерием для разделения испытуемых на тех, у кого “есть эффект” и тех, у кого “нет эффекта”. Если признак измерен количественно, использовать критерий λ для поиска оптимальной точки разделения.
2. Начертить четырехклеточную таблицу из двух столбцов и двух строк. Первый столбец – “есть эффект”; второй столбец – “нет эффекта”; первая строка сверху – 1 группа (выборка); вторая строка – 2 группа (выборка).
3. Подсчитать количество испытуемых в первой группе, у которых “есть эффект”, и занести это число в левую верхнюю ячейку таблицы.
4. Подсчитать количество испытуемых в первой выборке, у которых “нет эффекта”, и занести это число в правую верхнюю ячейку таблицы. Подсчитать сумму по двум верхним ячейкам. Она должна совпадать с количеством испытуемых в первой группе.
5. Подсчитать количество испытуемых во второй группе, у которых “есть эффект”, и занести это число в левую нижнюю ячейку таблицы.
6. Подсчитать количество испытуемых во второй выборке, у которых “нет эффекта”, и занести это число в правую нижнюю ячейку таблицы. Подсчитать сумму по двум нижним ячейкам. Она должна совпадать с количеством испытуемых во второй группе (выборке).
7. Определить процентные доли испытуемых, у которых “есть эффект”, путем отнесения их количества к общему количеству испытуемых в данной группе (выборке). Записать полученные процентные доли соответственно в левой верхней и левой нижней ячейках таблицы в скобках, чтобы не перепутать их с абсолютными значениями.
8. Проверить, не равняется ли одна из сопоставляемых процентных долей нулю. Если это так, попробовать изменить это, сдвинув точку разделения групп в ту или иную сторону. Если это невозможно или нежелательно, отказаться от критерия φ* и использовать критерий χ2.
9. Определить по Табл. XII Приложения 1 величины углов φ для каждой из сопоставляемых процентных долей.
10. Подсчитать эмпирическое значение φ* по формуле:
![]()
где: φ1 – угол, соответствующий большей процентной доле;
φ2 – угол, соответствующий меньшей процентной доле;
n1 – количество наблюдений в выборке 1;
n2 – количество наблюдений в выборке 2.
11. Сопоставить полученное значение φ* с критическими значениями: φ* ≤1,64 (р<0,05) и φ* ≤2,31 (р<0,01).
Если φ*эмп ≤φ*кр. H0 отвергается.
При необходимости определить точный уровень значимости полученного φ*эмп по Табл. XIII Приложения 1.
5.3. Биномиальный критерий ш Назначение критерия m
Критерий предназначен для сопоставления частоты встречаемости какого-либо эффекта с теоретической или заданной частотой его встречаемости.
Он применяется в тех случаях, когда обследована лишь одна выборка объемом не более 300 наблюдений, в некоторых задачах – не больше 50 наблюдений.
Описание критерия
Биномиальный критерий m позволяет оценить, насколько эмпирическая частота интересующего нас эффекта превышает теоретическую, среднестатистическую или какую-то заданную частоту, соответствующую вероятности случайного угадывания, среднему проценту успешности в выполнении данного задания, допустимому проценту брака и т.п.
Биномиальный критерий незаменим, если налицо 2 условия:
а) обследована лишь одна выборка испытуемых, и нет возможности или смысла делить эту выборку на две части с целью дальнейшего применения критерия, φ*, так как для нас по каким-то причинам важно исследовать частоту встречаемости признака в выборке в целом;
б) в обследованной выборке менее 30 испытуемых, что не позволяет нам применить критерий χ2.
Если в нашей выборке больше 30 испытуемых, мы все же можем использовать критерий m и тем самым сэкономить время на подсчете χ2.
Эмпирическая частота наблюдений, в которых проявляется интересующий нас эффект, обозначается как т. Это и есть эмпирическое [значение критерия т. Если mэмп равен или превышает mкр, то различия достоверны.
Гипотезы
H0
: Частота встречаемости данного эффекта в обследованной выборке не превышает теоретической (заданной, ожидаемой, предполагаемой).
H1: Частота встречаемости данного эффекта в обследованной выборке превышает теоретическую (заданную, ожидаемую, предполагаемую).
Графическое представление биномиального критерия
Критерий определяет, достаточно ли эмпирическая частота встречаемости признака превышает заданную, “перевешивает” ее. Можно представить себе это как взвешивание эмпирической и теоретической частот на чашечных весах (Рис. 5.4). Весы реагируют только на такие, различия в весе, которые соответствуют по крайней мере минимальному уровню значимости р<0,05.

Ограничения биномиального критерия
1. В выборке должно быть не менее 5 наблюдений. В принципе возможно применение критерия и при 2≤n<5, но лишь в отношении определенного типа задач (см. Табл. XV Приложения 1).
2. Верхний предел численности выборки зависит от ограничений, определяемых пп.3-8 и варьирует в диапазоне от 50 до 300 наблюдений, что определяется имеющимися таблицами критических значений.
3. Биномиальный критерий m позволяет проверить лишь гипотезу о том, что частота встречаемости интересующего нас эффекта в обследованной выборке превышает заданную вероятность Р. Заданная вероятность при этом должна быть: Р ≤0,50.
4. Если мы хотим проверить гипотезу о том, что частота встречаемости интересующего нас эффекта достоверно ниже заданной вероятности, то при Р=0,50 мы можем сделать это с помощью уже известного критерия знаков G, при Р>0,50 мы должны преобразовать гипотезы в противоположные, а при Р<0,50 придется использовать критерий χ2.
По Табл. 5.12 легко определить, какой из путей для нас доступен.
Таблица 5.12
Выбор критерия для сопоставлений эмпирической частоты с теоретической при разных вероятностях исследуемого эффекта Р и разных гипотезах.
| Заданные вероятности | H1: fэмпдостоверно выше fтеор | H1: fэмп достоверно ниже fтеор | ||||
| Р<0,50 | А | m | для 2 ≤n ≤50 | Б | χ2 | для n ≥30 |
| Р=0,50 | В | m | для 5 ≤n ≤300 | Г | G | для 5 ≤n ≤300 |
| Р>0,50 | Д | χ2 | для n ≤30 | Е | m | для 2 ≤n ≤50 |
Пояснения к Табл. 5.12
A) Если заданная вероятность Р<0,50, а fэмп>fтеор (например, допустимый уровень брака – 15%, а в обследованной выборке получено значение в 25%), то биномиальный критерий применим для объема выборки 2≤n≤50.
Б) Если заданная вероятность Р<0,50, а fэмп>fтеор (например, допустимый уровень брака – 15%, а в обследованной выборке наблюдается 5% брака), то биномиальный критерий неприменим и следует применять критерий χ2(см. Пример 2).
B) Если заданная вероятность Р=0,50, а fэмп>fтеор (например, вероятность выбора каждой из равновероятных альтернатив Р=0,50, а в обследованной выборке одна из альтернатив выбирается чаще, чем в половине случаев), то биномиальный критерий применим для объема выборки 5≤n≤300.
Г) Если заданная вероятность Р=0,50, a fэмп>fтеор (например, вероятность выбора каждой из равновероятных альтернатив Р=0,50, а в обследованной выборке одна из альтернатив наблюдается реже, чем в половине случаев), то вместо биномиального критерия применяется критерий знаков G, являющийся “зеркальным отражением” биномиального критерия при Р=0,50. Допустимый объем выборки: 5≤n≤300.
Д) Если заданная вероятность Р>0,50, а fэмп>fтеор (например, среднестатистический процент решения задачи – 80%, а в обследованной выборке он составляет 95%), то биномиальный критерий неприменим и следует применять критерий χ2(см. Пример 3).
Е) Если заданная вероятность Р>0,50, а fэмп>fтеор (например, среднестатистический процент решения задачи – 80%, а в обследованной выборке он составляет 60%), то биномиальный критерий применим при условии, что в качестве “эффекта” мы будем рассматривать более редкое событие – неудачу в решении задачи, вероятность которого Q=l—Р=1—0,80=0,20 и процент встречаемости в данной выборке: 100%—75%=25%. Эти преобразования фактически сведут данную задачу к задаче, предусмотренной n. А. Допустимый объем выборки: 2≤n≤50 (см. пример 3).
Пример 1
В процессе тренинга сенситивности в группе из 14 человек выполнялось упражнение “Психологический прогноз”. Все участники должны были пристально вглядеться в одного и того же человека, который сам пожелал быть испытуемым в этом упражнении. Затем каждый из участников задавал испытуемому вопрос, предполагавший два заданных варианта ответа, например: “Что в тебе преобладает: отстраненная наблюдательность или включенная эмпатия?” “Продолжал бы ты работать или нет, если бы у тебя появилась материальная возможность не работать?” “Кто тебя больше утомляет – люди нахальные или занудные?” и т. п. Испытуемый должен был лишь молча выслушать вопрос, ничего не отвечая. Во время этой паузы участники пытались определить, как он ответит на данный вопрос, и записывали свои прогнозы. Затем ведущий предлагал испытуемому дать ответ на заданный вопрос. Теперь каждый участник мог определить, совпал ли его прогноз с ответом испытуемого или нет. После того, как было задано 14 вопросов (13 участников ведущий), каждый сообщил, сколько у него получилось точных прогнозов. В среднем было по 7-8 совпадений, но у одного из участников их было 12, и группа ему спонтанно зааплодировала. У другого участника, однако, оказалось всего 4 совпадения, и он был очень этим огорчен.
Имела ли группа статистические основания для аплодисментов?
Имел ли огорченный участник статистические основания для грусти?
Начнем с первого вопроса.
По-видимому, группа будет иметь статистические основания для аплодисментов, если частота правильных прогнозов у участника А превысит теоретическую частоту случайных угадываний. Если бы участник прогнозировал ответ испытуемого случайным образом, то, в соответствии с теорией вероятностей, шансы случайно угадать или не угадать ответ на данный вопрос у него были бы равны P=Q=0,5. Определим теоретическую частоту правильных случайных угадываний:
fтеор=n·P
где n – количество прогнозов;
Р – вероятность правильного прогноза при случайном угадывании.
fтеор=14-0,5=7
Итак, нам нужно определить, “перевешивают” ли 12 реально данных правильных прогнозов 7 правильных прогнозов, которые могли бы быть у данного участника, если бы он прогнозировал ответ испытуемого случайным образом.
Требования, предусмотренные ограничением 3, соблюдены: Р=0,50; fэмп>fтеор. Данный случай относится к варианту “В” Табл. 5.12.
Мы можем сформулировать гипотезы.
H0: Количество точных прогнозов у участника А не превышает частоты, соответствующей вероятности случайного угадывания.
H1: Количество точных прогнозов у участника А превышает частоту, соответствующую вероятности случайного угадывания.
По Табл. XIV Приложения 1 определяем критические значения критерия m при n=14, Р=0,50:
![]()
Мы помним, что за эмпирическое значение критерия m принимается эмпирическая частота:

Зона значимости простирается вправо, в область более высоких значений m (более “весомых”, если использовать аналогию с весами), а зона незначимости – в область более низких, “невесомых”, значений m.
Ответ: H0отвергается. Принимается H1. Количество точных прогнозов у участника А превышает (или по крайней мере равняется) критической частоте вероятности случайного угадывания (р≤0,01). Группа вполне обоснованно ему аплодировала!
Теперь попробуем ответить на второй вопрос задачи.
По-видимому, основания для грусти могут появиться, если количество правильных прогнозов оказывается достоверно ниже теоретической частоты случайных угадываний. Мы должны определить, 4 точных прогноза участника Б – это достоверно меньше, чем 7 теоретически возможных правильных прогнозов при случайном угадывании или нет?
В данном случае Р=0,50; fэмп>fтеор. В соответствии с ограничением 4, в данном случае мы должны применить критерий знаков, который по существу является зеркальным отражением или “второй стороной” одностороннего биномиального критерия (вариант “Г” Табл. 5.12). Вначале нам нужно определить, что является типичным событием для участника Б. Это неправильные прогнозы, их 10. Теперь мы определяем, достаточно ли мало у него нетипичных правильных прогнозов, чтобы считать перевешивание неправильных прогнозов достоверным.
Сформулируем гипотезы.
H0: Преобладание неправильных прогнозов у участника Б является случайным.
H1: Преобладание неправильных прогнозов у участника Б не является случайным.
По Табл. V Приложения 1 определяем критические значения критерия знаков G для n=14:
![]()
Построим “ось значимости”. Мы помним, что в критерии знаков зона значимости находится слева, а зона незначимости – справа, так как чем меньше нетипичных событий, тем типичные события являются более достоверно преобладающими.

Эмпирическое значение критерия G определяется как количество нетипичных событий. В данном случае:
![]()
Эмпирическое значение критерия G попадает в зону незначимости.
Ответ: H0принимается. Преобладание неправильных прогнозов у участника Б является случайным.
Участник Б не имел достаточных статистических оснований для огорчения. Дело, однако, в том, что психологическая “весомость” отклонения его оценки значительно перевешивает статистическую. Всякий практикующий психолог согласится, что повод для огорчения у участника Б все же был.
Важная особенность биномиального критерия и критерия знаков состоит в том, что они превращают уникальность, единственность и жизненную резкость произошедшего события в нечто неотличимое от безликой и всепоглощающей случайности. Учитывая это, лучше использовать биномиальный критерий для решения более отвлеченных, формализованных задач, например, для уравновешивания выборок по признаку пола, возраста, профессиональной принадлежности и т. п.
При оценке же личностно значимых событий оказывается, что статистическая сторона дела не совпадает с психологической больше, чем при использовании любого из других критериев.
Пример 2
В тренинге профессиональных наблюдателей допускается, чтобы наблюдатель ошибался в оценке возраста ребенка не более чем на 1 год в ту или иную сторону. Наблюдатель допускается к работе, если он совершает не более 15% ошибок, превышающих отклонение на 1 год. Наблюдатель Н допустил 1 ошибку в 50-ти попытках, а наблюдатель К – 15 ошибок в 50-ти попытках. Достоверно ли отличаются эти результаты от контрольной величины?
Определим частоту допустимых ошибок при п = 50:
fтеор=n·Р=50·0,15=7,5
Для наблюдателя Н fэмпfтеор. Для наблюдателя К fэмп>fтеор
Сформулируем гипотезы для наблюдателя Н.
H0: Количество ошибок у наблюдателя Н не меньше, чем это предусмотрено заданной величиной.
H1: Количество ошибок у наблюдателя Н меньше, чем это предусмотрено заданной величиной.
В данном случае Р=0,15<0,50; fэмп>fтеор.
Этот случай попадает под вариант Б Табл. 5. 12. Нам придется применить критерий у}, сопоставляя полученные эмпирические частоты ошибочных и правильных ответов с теоретическими частотами, составляющими, соответственно, 7,5 для ошибочного ответа и (50-7,5)=42,5 для правильного ответа. Подсчитаем χ2по формуле, включающей поправку на непрерывность3:

По Табл. IX Приложения 1 определяем критические значения χ2при v=l:

Ответ: H0 отвергается. Количество ошибок у наблюдателя Н меньше, чем это предусмотрено заданной величиной (р≤0,05)
Сформулируем гипотезы для наблюдателя К.
H0: Количество ошибок у наблюдателя К не больше, чем это предусмотрено заданной величиной.
H1: Количество ошибок у наблюдателя К больше, чем это предусмотрено заданной величиной.
В данном случае Р=0,15<0,5; fэмп>fтеор.Этот случай подпадает под вариант А Табл. 5.12. Мы можем применить биномиальный критерий, поскольку n=50.
По Табл. XV Приложения 1 определяем критические значения при п=50, Р=0,15, Q=0,85:

Ответ: H0 отвергается. Количество ошибок у наблюдателя Н меньше, чем это предусмотрено заданной величиной (р<0,05).
Пример 3
В примере 1 параграфа 5.2 мы сравнивали процент справившихся с экспериментальной задачей испытуемых в двух группах. Теперь мы можем сопоставить процент успешности каждой группы со среднестатистическим процентом успешности. Данные представлены в Табл. 5.13.
Таблица 5.13
Показатели успешности решения задачи в двух группах испытуемых
| Количество испытуемых, решивших задачу | Количество испытуемых, не решивших задачу | Суммы | |||
| 1 группа (n1=20) | 12 | (60%) | 8 | (40%) | 20 |
| 2 группа (п7=25) | 10 | (40%) | 15 | (60%) | 25 |
| Суммы | 22 | 23 | 45 | ||
Среднестатистический показатель успешности в решении этой задачи – 55%. Определим теоретическую частоту правильных ответов для групп 1 и 2:
![]()
Для группы 1, следовательно, Р=0,55>0,50; fэмп=12>fтеор. Этот случай соответствует варианту “Д” Табл. 5.12. Мы должны были бы применить критерий χ2, но у нас всего 20 наблюдений: n<30. Ни биномиальный критерий, ни критерий χ2неприменимы. Остается критерий φ* Фишера, который мы сможем применить, если узнаем, сколько испытуемых было в выборке, по которой определялся среднестатистический процент.
Далее, для группы 2: Р=0,55>0,50; fэмп=10>fтеор. Этот случай соответствует варианту “Е” Табл. 5.12. Мы можем применить биномиальный критерий, если будем считать “эффектом” неудачу в решении задачи. Вероятность неудачи Q=l—Р=1—0,55=0,45. Новая эмпирическая частота составит: fэмп=25-10=15.
Сформулируем гипотезы.
H0: Процент неудач в обследованной выборке не превышает заданного процента неудач.
H1 Процент неудач в обследованной выборке превышает заданный процент неудач.
По Табл. XV Приложения 1 определяем критические значения для n=25, P=0,45, Q=0.55 (мы помним, что Р и Q поменялись местами):

Ответ: H0принимается. Процент неудач в обследованной выборке не превышает заданного процента неудач.
Сформулируем общий алгоритм применения критерия m.
АЛГОРИТМ 18
Применение биномиального критерия m
1. Определить теоретическую частоту встречаемости эффекта по формуле:
Fтеор=n·Р.
где n – количество наблюдений в обследованной выборке;
Р – заданная вероятность исследуемого эффекта.
По соотношению эмпирической и теоретической частот и заданной вероятности Р определить, к какой ячейке Табл. 5.12 относится данный случай сопоставлений.
Если биномиальный критерий оказывается неприменимым, использовать тот критерий, который указан в соответствующей ячейке Табл. 5.12
2. Если критерий m применим, то определить критические значения m по Табл. XVI (при Р=0,50) или по табл. XV (при Р<0,50) для данных n и Р.
3. Считать mэмп эмпирическую частоту встречаемости эффекта в обследованной выборке: mэмп=fэмп.
4. Если mэмп превышает критические значения, это означает, что эмпирическая частота достоверно превышает частоту, соответствующую заданной вероятности.
5.4. Многофункциональные критерии как эффективные заменители традиционных критериев
Как было показано в предыдущих параграфах, многофункциональные критерии, главным образом критерий φ*, применим к решению всех трех типов задач, рассмотренных в Главах 2-4: сопоставление уровней, определение сдвигов и сравнение распределений признака. В тех случаях, когда обследованы две выборки испытуемых, критерий φ* может эффективно заменять или, по крайней мере, эффективно дополнять традиционные критерии: Q – критерий Розенбаума, U – критерий Манна-Уитни, критерий χ2Пирсона и критерий λКолмогорова-Смирнова.
В особенности полезна такая замена в следующих случаях:
Случай 1. Другие критерии неприменимы
Часто бывает так, что критерий Q неприменим вследствие совпадения диапазонов двух выборок, а критерий U неприменим вследствие того, что количество наблюдений n>60.
В качестве примера сошлемся на задачу сравнения сдвигов оценок в экспериментальной и контрольной группах после просмотра видеозаписи и чтения текста о пользе телесных наказаний (см. параграф 3.2). Сдвиги в двух группах являются показателями, полученными независимо в двух группах испытуемых. Задача сравнения таких показателей сдвига – это частный случай задачи сопоставления двух групп по уровню значений какого-либо признака. Такие задачи решаются с помощью критериев Q Розенбаума и U Манна-Уитни (см. Табл. 3.1). Сводные данные по сдвигам в двух группах представлены в Табл. 5.14.
Таблица 5.14
Эмпирические частоты сдвигов разной интенсивности и направления в экспериментальной и контрольной группах после предъявления видеозаписи или письменного текста
| Значения сдвига | Количество сдвигов в экспериментальной группе (n1=16) | Количество сдвигов в контрольной группе (n2=23) | Суммы |
| 5 2 1 | 0 3 19 | 1 5 11 | 1 8 30 |
| 0 | 38 | 65 | 103 |
| -1 -2 | 4 0 | 8 2 | 12 2 |
| Суммы | 64 | 92 | 156 |
В экспериментальной группе значения сдвигов варьируют от —2 до 2, а в контрольной группе от —2 до 5. Критерий Q неприменим. Критерий U неприменим, поскольку количество наблюдений (сдвигов) в каждой группе больше 60.
Применяем критерий φ*. Построим вначале четырехклеточную таблицу для положительных сдвигов, а затем – для нулевых.
Таблица 5.15
Четырехклеточная таблица для подсчета критерия φ* при сопоставлении долей положительных сдвигов в экспериментальной и контрольной группах
| Группы | Есть эффект : сдвиг положительный | “Нет эффекта”.’ сдвиг отрицательный или нулевок | Суммы |
| Группа 1 экспериментальная | 22 (34,4%) | 42 (656%) | 64 |
| Группа 2 контрольная | 17 (18,5%) | 75 (81,5%) | 92 |
| Суммы | 39 | 117 | 156 |
Сформулируем гипотезы.
H0: Доляположительных сдвигов в экспериментальной группе не больше, чем в контрольной.
H1: Доля положительных сдвигов в экспериментальной группе больше, чем в контрольной.
Далее действуем по Алгоритму 17.

Мы можем и точно определить уровень статистической значимости полученного результата по Табл. XIII Приложения 1:
при φ*эмп=2,242 р=0,013.
Ответ: H0отклоняется. Принимается H1. Доля положительных сдвигов в экспериментальной группе больше, чем в контрольной (р<0,013).
Теперь перейдем к вопросу о меньшей доле нулевых сдвигов в экспериментальной группе.
Таблица 5.16
Четырехклеточная таблица для подсчета критерия φ* при сопоставлении долей нулевых сдвигов в экспериментальной и контрольной группах
| Группы | “Есть эффект”: сдвиг равен 0 | “Нет сдвиг а”: эффект не равен 0 | Суммы | ||
| Группа 1 экспериментальная | 38 | (59,4%) | 26 | (40,6%) | 64 |
| Группа 2 контрольная | 65 | (70,7%) | 27 | (29,3%) | 92 |
| Суммы | 103 | 53 | 156 | ||
Сформулируем гипотезы.
H0: Доля нулевых сдвигов в контрольной группе не больше, чем в экспериментальной.
H1: Доля нулевых сдвигов в контрольной группе больше, чем в экспериментальной. Далее действуем по Алгоритму 17.

Ответ: H0принимается. Доля нулевых сдвигов в контрольной группе не больше, чем в экспериментальной.
Итак, доля положительных сдвигов в экспериментальной группе больше, но доля нулевых сдвигов – примерно такая же, как и в контрольной группе. Отметим, что в критерии знаков G все нулевые сдвиги были исключены из рассмотрения, поэтому полученный результат дает дополнительную информацию, которую не мог дать критерий знаков.
Случай 2. Другие критерии неэффективны или слишком громоздки
В качестве примера можно указать на задачу с сопоставлением показателей недостаточности в группах с большей и меньшей энергией вытеснения (см. Табл. 5.4).
Критерий Q дает незначимый результат:

Критерий U в данном случае применим и даже дает значимый результат (Uэмп=154,5; р<0,05), однако ранжирование показателей, многие из которых имеют одно и то же значение (например, значение 30 баллов встречается 13 раз), представляет определенные трудности.
Как мы помним, с помощью критерия φ* удалось доказать, что наиболее высокие показатели недостаточности (30 и более баллов) встречаются в группе с большей энергией вытеснения чаще, чем в группе с меньшей энергией вытеснения (р=0,008) и что, с другой стороны, самые низкие (нулевые) показатели встречаются чаще также в этой группе (р ≤0,05).
Другим примером может служить задача сопоставления распределения выборов желтого цвета в отечественной выборке и в выборке Х.Клара (см. параграф 4.3).
Критерий λне выявил достоверных различий между двумя распределениями, однако позволил нам установить точку максимального накопленного расхождения между ними. Из Табл. 4.19 следует, что такой точкой является вторая позиция желтого цвета. Построим четы-рехклеточную таблицу, где “эффектом” будет считаться попадание желтого цвета на одну из первых двух позиций.
Таблица 5.17
Четырехклеточная таблица для расчета φ* при сопоставлении отечественной выборки (n1=102) и выборки Х.Клара (n2=800) по положению желтого цвета в ряду предпочтений
| Выборки | “Есть эффект”: желтый цвет на первых двух позициях | “Нет эффекта”: желтый цвет на позициях 3-8 | Суммы |
| Выборка 1 -отечественная | 39 (38.2%) | 63 (61,8%) | 102 |
| Выборка 2 -Х.Клара | 211 (26,4%) | 589 (73,6%) | 800 |
| Суммы | 250 | 652 | 902 |
Сформулируем гипотезы:
H0: Доля лиц, помещающих желтый цвет на одну из первых двух позиций, в отечественной выборке не больше, чем в выборке Х.Клара.
H1: Доля лиц, поместивших желтый цвет на одну из первых двух позиций, в отечественной выборке больше, чем в выборке X. Клара.
Далее действуем по Алгоритму 17.

Ответ: H0 отклоняется. Принимается H1: Доля лиц, поместивших желтый цвет на одну из первых двух позиций, в отечественной выборке больше, чем в выборке Х.Клара (р<0,01).
Мы еще раз столкнулись с тем случаем, когда критерий А, сам по себе не выявляет достоверных различий, но помогает максимально использовать возможности критерия φ*.
Случай 3. Другие критерии слишком трудоемки
Этот случай чаще всего относится к критерию χ2. Заменить его критерием φ* можно при условии, если сравниваются распределения признака в двух выборках, а сам признак принимает всего два значения4.
В качестве примера можно привести задачу с соотношением мужских и женских имен в записных книжках двух психологов (см. п. 4.2, Табл. 4.11).
Преобразуем Табл. 4.11 в четырехклеточную таблицу, где “эффектом” будем считать мужские имена.
Таблица 5.18
Четырехклеточная таблица для подсчета φ* при сопоставлении записных книжек двух психологов по соотношению мужских и женских имен
| Группы | “Есть аффект”: мужские имена | “Нет аффекта»: женские имена | Суммы | ||
| Группа 1 – выборка имен в книжке X. | 22 | (32,8%) | 45 | (67,2%) | 67 |
| Группа 2 – выборка имен в книжке С. | 59 | (35,1%) | 109 | (64,9%) | 168 |
| Суммы | 81 | 154 | 235 | ||
Сформулируем гипотезы.
H0: Доля мужских имен в записной книжке С. не больше, чем в записной книжке X.
H1: Доля мужских имен в записной книжке С. больше, чем в записной книжке X.
Далее действуем по алгоритму.

По Табл. XIII Приложения 1 определяем, какому уровню достоверности соответствует это значение. Мы видим, что такого значения вообще нет в таблице. Построим “ось значимости”.

Полученное эмпирическое значение – далеко в “зоне незначимости”.
f*эмп>f*теор
Ответ: H0 принимается. Доля мужских имен в записной книжке психолога С. не больше, чем в запиской книжке психолога X.
Исследователь сам может решить для себя, какой метод ему в данном случае удобнее применить – χ2или φ*. Похоже, что во втором случае меньше расчетов, хотя чуда не произошло: различия по-прежнему недостоверны.
Итак, мы убедились, что критерий φ* Фишера может эффективно заменять традиционные критерии в тех случаях, когда их применение невозможно, неэффективно или неудобно по каким-то причинам.
Биномиальный критерий m может служить заменой критерия χ2в случае альтернативных распределений или в случае, когда признак может принимать одно из нескольких значений и вероятность того, что он примет определенное значение, известна.
В качестве примера можно привести исследование, посвященное распределению предпочтений по 4-м типам мужественности (см. Задачу 3 к Главе 4). Если бы для испытуемых все 4 типа мужественности были одинаково привлекательными, то на первом месте примерно одинаковое количество раз оказывался бы каждый из типов. Иными словами, вероятность оказаться на первом месте для каждого типа составляла бы 1/4 т.е. Р=0.25.
В действительности же Национальный тип оказался на 1-м месте 19 раз, Современный – 7 раз, Религиозный – 3 раза и Мифологический – 2 раза. Можно попытаться определить, достоверно ли Национальный тип чаще оказывается на 1-м месте, чем это предписывается вероятностью Р=0,25?
Сформулируем гипотезы.
H0; Частота попадания Национального типа мужественности на 1-е место в ряду предпочтений не превышает частоты, соответствующей вероятности Р=0,25.
H1: Частота попадания Национального типа мужественности на 1-е место в ряду предпочтений превышает частоту, соответствующую вероятности Р=0,25.
Определим теоретическую частоту попадания того или иного типа мужественности на 1-е место при равновероятном выборе:
fтеор=n·Р=31-0,25=7,75
В данном случае соблюдаются требования, предусмотренные ограничением 3: Р=0,25<0,50; fэмп>fтеор. Мы можем использовать биномиальный критерий при n<50. В данном случае n=31. По Табл. XV Приложения 1 определяем критические значения m при n=31, Р=0,25; Q=0,75:
![]()
![]()
Ответ: H0отвергается. Частота попадания Национального типа мужественности на 1-е место в ряду предпочтений превышает частоту, соответствующую вероятности Р=0,25 (р<0,01).
Итак, Национальный тип мужественности действительно чаще оказывается на 1-м месте, чем это происходило бы в том случае, если бы он выбирался на 1-е место равновероятно с другими типами.
Отметим, что мы проверяли гипотезу не об отличии данного типа мужественности от других типов, а об отличии частоты его встречаемости от теоретически возможной величины при равновероятном выборе. Все остальные типы и остальные позиции выбора остаются “за кадром” нашего рассмотрения.
Аналогичным образом можно сопоставить с теоретической частотой эмпирическую частоту попадания любого другого типа на любую другую позицию.
5.5. Задачи для самостоятельной работы
ВНИМАНИЕ!
При выборе метода решения задачи рекомендуется использовать АЛГОРИТМ 19
Задача 9
В выборке студентов факультета психологии Санкт-Петербургского университета с помощью известного “карандашного” теста определялось преобладание правого или левого глаза в прицельной, способности глаз. Совпадают ли эти данные с результатами обследования 100 студентов медицинских специальностей, представленными Т.А. Доброхотовой и Н.Н. Брагиной (1994)?
Таблица 5.19
Показатели преобладания правого и левого глаза в выборке студентов-психологов (n1=14) и студентов-медиков (n2=100)
| Количество испытуемых с преобладанием левого глаза | Количество испытуемых с преобладанием правого глаз; | Суммы | |
| 1. Студенты-психологи | е | 8 | 14 |
| 2. Студенты-медики | 19 | 81 | 100 |
| Суммы | 25 | 89 | 114 |
Задача 10
В исследовании А. А. Кузнецова (1991) изучались различия в реагировании на вербальную агрессию между милиционерами патрульно-постовой службы и обычными гражданами. Экспериментатор в дневное время поджидал на достаточно многолюдной остановке вблизи от милицейского общежития появления мужчины в возрасте 25-35 лет и, установив с ним контакт глаз, обращался к нему с агрессивной формулой: “Ну, чего уставился?! Чего надо?!” Реакция испытуемого наблюдалась и запоминалась экспериментатором. После этого испытуемому приносились извинения и предъявлялась справка о том, что ее предъявитель является исполнителем научного эксперимента по исследованию стилей реагирования на агрессию на факультете психологии Санкт-Петербургского университета. Кроме того, экспериментатор выяснял, является ли испытуемый милиционером патрульно-постовой службы или обычным гражданином. Таким образом была собрана выборка из 25 милиционеров, которые в данный момент были не в форме и не на посту, то есть были такими же участниками гражданской жизни, как и другие граждане, и выборка из 25 граждан, не являвшихся милиционерами. Из 25 милиционеров 10 не продолжили разговора с агрессором, а 15 продолжили его, обратившись к нему с ответной фразой. Из этих 15 реакций 10 были неагрессивными и примирительными, например, “Так просто… Закурить не найдется?” или “Сколько времени, не скажешь?” или дружески: “Ух ты какой!” или мягко: “А чего ты тут стоишь?” 5 реакций были агрессивными, например, “Что?! А ну, повтори!” или “Ты что-то вякнул или мне послышалось?” или “Я тебе сейчас уставлюсь. Ну-ка, иди сюда!”
Из 25 гражданских лиц 18 предпочли не вступать в разговор, 3 человека продолжили контакт, обратившись к экспериментатору с неагрессивной, примирительной фразой вроде: “Ничего, просто смотрю” или “А может быть, вы мне понравились”. Оставшиеся 4 человека продолжили контакт, дав агрессивный ответ, например, “А ты что, резкий, что ли?” и т.п.
Вопросы:
1. Можно ли утверждать, что милиционеры патрульно-постовой службы в большей степени склонны продолжать разговор с агрессором, чем другие граждане?
2. Можно ли утверждать, что милиционеры склонны отвечать агрессору более примирительно, чем гражданские лица?
Задача 11
В анкетном опросе английских общепрактикующих врачей (Курочкин М. А., Сидоренко Е. В., Чураков Ю. А., 1992) было установлено, что врачи, уже перешедшие на самостоятельный бюджет, как правило, работают в приемных с большим количеством партнеров, чем врачи, не перешедшие на самостоятельный бюджет. Возможно, врачам легче решиться взять фонды, когда их “команда” больше, но может быть, “команда” становится больше уже после того, как врачи данной приемной согласились взять фонды. Причину и следствие установить трудно. Пока необходимо установить другое: действительно ли в приемных с фондами работают большие по составу команды врачей, чем в приемных без фондов? Может ли некая фармацевтическая фирма ориентироваться на эту тенденцию при построении стратегии продвижения своего товара?
Таблица 5.20
Показатели количества партнеров у врачей с фондами и врачей без фондов (по данным М.А. Курочкина, Е.В. Сидоренко, Ю.А. Чуракова, 1992)
| Количество партнеров | Эмпирические частоты | Всего | ||
| в выборке врачей с фондам» (n1=49) | в выборке врачей без фондов (n2=28) | |||
| 1 2 3 4 | 2 и менее 3-4 партнера 5-6 партнеров 7 и более | 2 6 27 14 | 15 5 8 0 | 17 11 35 14 |
| Суммы | 49 | 28 | 77 | |
Задача 12
Наблюдателем установлено, что 51 человек из 70-ти выбрал правую дорожку при переходе из точки А в точку Б, а 19 человек – левую (см. параграф 4.2).
Можно ли утверждать, что правая дорожка предпочиталась достоверно чаще?
5.6. Алгоритм выбора многофункциональных критериев

5.7. Математическое сопровождение к описанию критерия φ* Фишера
Угловое преобразование позволяет перевести процентные доли, которые сами по себе имеют распределение, далекое от нормального, в величину φ, распределение которой близко к нормальному (Гублер Е.В., 1978, с. 84). Это дает определенные преимущества в том случае, если мы хотим использовать параметрические критерии, требующие нормальности распределений.
Как видно из графика на Рис. 5.1, φ нарастает в общем пропорционально процентной доле, но при этом на крайних значениях φ кривая характеризуется большей крутизной.
Благодаря этому для малых долей (меньше 20%) и больших долей (больше 80%) определение достоверности разности долей по соответствующим углам φ дает более правильные результаты, а для долей в пределах от 20 до 80% замена их углами φ дает такие же результаты, какие получаются и без этой замены, но техника вычислений при этом упрощается (Плохинский Н.А., 1970, с. 143).
Углы φ измеряются в радианах. Радиан – это угол, являющийся центральным для дуги, длина которой равна радиусу окружности (Рис. 5.5).

1 радиан равен 57°17’44”.
Величина φ определяется по формуле:
![]()
где Р – доля, выраженная в долях единицы;
arcsin – обратная синусу тригонометрическая функция.
Иными словами, синус угла φ/2 равен корню квадратному из Р. Напомним, что sinφ=а/с (см. Рис. 5.6), a arcsin а/с= φ

Величину φ можно вычислить в радианах или определить по специальной таблице (Табл. XII Приложения 1).
Н.А. Плохинский использует иную формулу определения ф:
![]()
где φ1 – значение угла для первой доли;
φ2– значение угла для второй доли;
n1 – количество наблюдений в первой выборке;
n2 – количество наблюдений во второй выборке.
Эмпирические значения Fdсопоставляются с критическими значениями критерия F Фишера, которые определяются по таблице для степеней свободы v1 и v2, определяемых как:
По нашему опыту, этот вариант критерия с использованием углового преобразования дает менее точные результаты, чем вариант Е.В. Гублера (1978).
![]()
<< предыдущая страница следующая страница >>
§
ГЛАВА 6 МЕТОД РАНГОВОЙ КОРРЕЛЯЦИИ
6.1. Обоснование задачи исследования согласованных действий
Первоначальное значение термина “корреляции” – взаимная связь (Oxford Advanced Learner’s Dictionary of Current English, 1982). Когда говорят о корреляции, используют термины “корреляционная связь” и “корреляционная зависимость”.
Корреляционная связь – это согласованные изменения двух признаков или большего количества признаков (множественная корреляционная связь). Корреляционная связь отражает тот факт, что изменчивость одного признака находится в некотором соответствии с изменчивостью другого (Плохинский Н.А., 1970, с. 40). “Стохастическая5связь имеется тогда, когда каждому из значений одной случайной величины соответствует специфическое (условное) распределение вероятностей значений другой величины, и наоборот, каждому из значений этой другой величины соответствует специфическое (условное) распределение вероятностей значений первой случайной величины” (Суходольский Г.В., 1972, с. 178).
Корреляционная зависимость – это изменения, которые вносят значения одного признака в вероятность появления разных значений другого признака.
Оба термина – корреляционная связь и корреляционная зависимость – часто используются как синонимы (Плохинский Н.А.,1970; Суходольский Г.В.,1972; Артемьева Е.Ю., Мартынов Е.М.,1975 и др.). Между тем, согласованные изменения признаков и отражающая это корреляционная связь между ними может свидетельствовать не о зависимости этих признаков между собой, а зависимости обоих этих признаков от какого-то третьего признака или сочетания признаков, не рассматриваемых в исследовании.
Зависимость подразумевает влияние, связь – любые согласованные изменения, которые могут объясняться сотнями причин. Корреляционные связи не могут рассматриваться как свидетельство причинно-следственной связи, они свидетельствуют лишь о том, что изменениям одного признака, как правило, сопутствуют определенные изменения другого, но находится ли причина изменений в одном из признаков или она оказывается за пределами исследуемой пары признаков, нам неизвестно.
Говорить в строгом смысле о зависимости мы можем только в тех случаях, когда сами оказываем какое-то контролируемое воздействие на испытуемых или так организуем исследование, что оказывается возможным точно определить интенсивность не зависящих от нас воздействий. Воздействия, которые мы можем качественно определить или даже измерить, могут рассматриваться как независимые переменные. Признаки, которые мы измеряем и которые, по нашему предположению, могут изменяться под влиянием независимых переменных, считаются зависимыми переменными. Согласованные изменения независимой и зависимой переменной действительно могут рассматриваться как зависимость.
Однако, учитывая, что число градаций, или уровней, зависимой переменной обычно невелико, целесообразнее применять в такого рода исследованиях не корреляционный метод, а методы выявления тенденций изменения признака при изменении условий, например, критерии тенденций Н Крускала-Уоллиса и L Пейджа (см. Главы 2 и 3) или метод дисперсионного анализа (см. Главы 7 и 8).
Если в исследование включены независимые переменные, которые мы можем по крайней мере учитывать, например, возраст, то можно считать выявляемые между возрастом и психологическими признаками корреляционные связи корреляционными зависимостями. В большинстве же случаев нам трудно определить, что в рассматриваемой паре признаков является независимой, а что – зависимой переменной.
Учитывая, что термин “зависимость” явно или неявно подразумевает влияние, лучше пользоваться более нейтральным термином “корреляционная связь”.
Корреляционные связи различаются по форме, направлению и степени (силе).
По форме корреляционная связь может быть прямолинейной или криволинейной. Прямолинейной может быть, например, связь между количеством тренировок на тренажере и количеством правильно решаемых задач в контрольной сессии. Криволинейной может быть, например, связь между уровнем мотивации и эффективностью выполнения задачи (см. Рис. 6.1). При повышении мотивации эффективность выполнения задачи сначала возрастает, затем достигается оптимальный уровень мотивации, которому соответствует максимальная эффективность выполнения задачи; дальнейшему повышению мотивации сопутствует уже снижение эффективности.

По направлению корреляционная связь может быть положительной (“прямой”) и отрицательной (“обратной”). При положительной прямолинейной корреляции более высоким значениям одного признака соответствуют более высокие значения другого, а более низким значениям одного признака – низкие значения другого (см. Рис. 6.2). При отрицательной корреляции соотношения обратные.

При положительной корреляции коэффициент корреляции имеет положительный знак, например r= 0,207, при отрицательной корреляции – отрицательный знак, например r=—0,207.
Степень, сила или теснота корреляционной связи определяется по величине коэффициента корреляции.
Сила связи не зависит от ее направленности и определяется по абсолютному значению коэффициента корреляции. Максимальное возможное абсолютное значение коэффициента корреляции r=1,00; минимальное r=0.
Используется две системы классификации корреляционных связей по их силе: общая и частная. Общая классификация корреляционных связей (по Ивантер Э.В., Коросову А.В., 1992):
1) сильная, или тесная при коэффициенте корреляции r>0,70;
2) средняя при 0,50<0,69;>
3) умеренная при 0,30<0,49;>
4) слабая при 0,20<0,29;>
5) очень слабая при r<0,19.
Частная классификация корреляционных связей:
1) высокая значимая корреляция при г, соответствующем уровню статистической значимости р<0,01;
2) значимая корреляция при г, соответствующем уровню статистической значимости р<0,05;
3) тенденция достоверной связи при г, соответствующем уровню статистической значимости р<0,10;
4) незначимая корреляция при г, не достигающем уровня статистической значимости .
Две эти классификации не совпадают. Первая ориентирована только на величину коэффициента корреляции, а вторая определяет, какого уровня значимости достигает данная величина коэффициента корреляции при данном объеме выборки. Чем больше объем выборки, Тем меньшей величины коэффициента корреляции оказьюается достаточно, чтобы корреляция была признана дортоверной. В результате при Малом объеме выборки может оказаться так, что сильная корреляция окажется недостоверной. В то же время при больших объемах выборки Даже слабая корреляция может оказаться достоверной.
Обычно принято ориентироваться на вторую классификацию, поскольку она учитывает объем выборки. Вместе с тем, необходимо помнить, что сильная, или высокая, корреляция – это корреляция с коэффициентом r>0,70, а не просто корреляция высокого уровня значимости.
В качестве мер корреляции используются:
1) эмпирические меры тесноты связи, многие из которых были получены еще до открытия метода корреляции, а именно:
а) коэффициент ассоциации, или тетрахорический показатель связи;
б) коэффициенты взаимной сопряженности Пирсона и Чупрова;
в) коэффициент Фехнера;
г) коэффициент корреляции рангов;
2) линейный коэффициент корреляции r,
3) корреляционное отношение η;
4) множественные коэффициенты корреляции и др.
Подробное описание этих мер можно найти в руководствах Ве-нецкого И.Г., Кнльдишева Г.С.(1968), Плохинского Н.А.(1970), Су-ходольского Г.В.(1972), Ивантер Э.В., Коросова А.В.(1992) и др.
В психологических исследованиях чаще всего применяется коэффициент линейной корреляции r Пирсона. Однако этот метод является параметрическим и поэтому не лишен недостатков, свойственных параметрическим методам (см. параграф 1.8). Параметрическими являются, также методы определения корреляционного отношения и подсчета множественных коэффициентов корреляции. Кроме того, эти методы, как правило, требуют машинной обработки данных. По этим причинам они остаются за пределами нашего рассмотрения.
Все эмпирические меры тесноты связи, кроме коэффициента ранговой корреляции, могут быть заменены методами сопоставления и сравнения, изложенными в Главах 2-5.
Ведь что, в сущности, мы доказываем, когда обосновываем различия в долях двух выборок, характеризующихся исследуемым эффектом? Мы показываем, что если испытуемый относится к одной из выборок, то скорее всего он будет характеризоваться какими-то определенными значениями исследуемого признака, а если он относится к другой из двух выборок, то он будет характеризоваться (с большой степенью вероятности) другими значениями исследуемого признака. Фактически мы исследуем сопряженные изменения двух признаков: отнесенность к той или иной выборке и определенные значения исследуемого признака.
Что мы доказываем, с другой стороны, когда два распределения признака оказываются сходными или, наоборот, статистически достоверно различающимися между собой? Мы доказываем, что в обеих выборках частоты встречаемости разных значений признака распределяются согласованно или, наоборот, несогласованно.
Мы, правда, скорее определяем меру рассогласованности, чем согласованкости, но все же часто метод χ2относится к числу методов, выявляющих степень согласованности или даже связи.
Методы выявления тенденций уже напрямую заменяют меры эмлирической сопряженности, позволяя нам проследить возрастание значений признака при изменении условий. Фактически мы отвечаем на вопрос о том, согласованно ли изменяются условия и значения исследуемого признака.
Быть может, современному психологу не очень просто отказаться от метода подсчета корреляций. Это очень привычно – подсчитывать корреляции. Исторически сложилось так, что этот метод является одним из основных методов статистической обработки. Главное преимущество корреляционного анализа состоит в том, что можно сразу провести множественное сопоставление признаков. Например, “нам необходимо определить, с чем связана успешность в какой-либо деятельности. Исследователь может предполагать, что она связана с уровнем интеллектуального развития, с некоторыми из личностных факторов 16-факторного опросника Кеттелла, а может быть, с уровнем эмпатии, тревожности или фрустрационной толерантности, с возрастом самого испытуемого или возрастом матери в момент его рождения и т.д. и т.п. В итоге он получает связи, отражающие среднегрупповые тенденции сопряженного изменения признаков. Но дело как раз в том, что у каждого отдельного испытуемого успешность в данном виде деятельности может определяться разными психологическими характеристиками или разными их сочетаниями. Метод корреляций отдает предпочтение группе, а не отдельному индивиду.
Против этого можно возразить, что и все остальные статистические методы отдают предпочтение среднегрупповым, а не индивидуальным тенденциям. Однако это не совсем так. Например, метод тенденций L Пейджа определяет степень согласованности индивидуальных тенденций, критерий χ2, Фридмана — степень совпадения или несовпадения индивидуальных соотношений рангов, биномиальный критерий m -степень отклонения индивидуальных значений от заданных или среднестатистических и т.п.
Прежде чем переходить к корреляциям, исследователю необходимо проанализировать полученные данные с помощью критериев сравнения и сопоставления еще и по другой причине. Возможно, размах вариативности признака в обследованной выборке окажется слишком узким, чтобы можно было распространять полученную корреляцию на весь возможный диапазон его значений. Например, может оказаться так, что в обследованной группе по какому-либо из факторов 16-факторного личностного опросника Кеттелла получены лишь низкие и средние значения, и в то же время выявлена значимая положительная связь этого личностного фактора с успешностью профессиональной деятельности. Не учитывая истинного размаха значений в данной выборке, можно экстраполировать полученную связь и на высокие значения фактора, что может оказаться ошибкой. Во->первых, связь данного фактора с успешностью деятельности может на самом деле быть криволинейной, как в рассмотренном выше случае связи уровня мотивации с эффективностью выполнения задания (см. Рис. 6.1). Во-вторых, не исключено, что самым важным результатом исследования является как раз факт низких и средних значений данного личностного фактора в обследованной выборке, а исследователь не обратил на него внимания, привычно отдав предпочтение корреляционной матрице, а не таблице первичных данных.
Математическая обработка должна начинаться с использования “самых простых приемов с совершенно понятной для исследователя сутью производимых преобразований” (Дворяшина М.Д., Пехлецкий И.Д., 1976, с. 45). Учитывая большие возможности методов первичной обработки данных, изложенных в Главах 2-5, не исключено, что этими приемами математическая обработка может и заканчиваться. Эти методы дают и основание для достоверных выводов, и материал для выдвижения новых гипотез, и стимул к новым размышлениям.
И все же, если исследователь хочет применить метод корреляций, в настоящем пособии предлагается использовать коэффициент ранговой корреляции Спирмена. Основанием для выбора этого коэффициента служат:
а) его универсальность;
б) простота;
в) широкие возможности в решении задач сравнения индивидуальных или групповых иерархий признаков.
Универсальность коэффициента ранговой корреляции проявляется в том, что он применим к любым количественно измеренным или ранжированным данным. Простота метода позволяет подсчитывать корреляцию “вручную”. Уникальность метода ранговой корреляции состоит в том, что он позволяет сопоставлять не индивидуальные показатели, а индивидуальные иерархии, или профили, что недоступно ни одному из других статистических методов, включая метод линейной корреляции (Плохинский НА., 1970, с. 167).
Коэффициент ранговой корреляции рекомендуется применять в тех случаях, когда нам необходимо проверить, согласованно ли изменяются разные признаки у одного и того же испытуемого и насколько совпадают индивидуальные ранговые показатели у двух отдельных испытуемых или у испытуемого и группы.
6.2. Коэффициент ранговой корреляции rs Спирмена
Назначение рангового коэффициента корреляции
Метод ранговой корреляции Спирмена позволяет определить тесноту (силу) и направление корреляционной связи между двумя признаками или двумя профилями {иерархиями) признаков.
Описание метода
Для подсчета ранговой корреляции необходимо располагать двумя рядами значений, которые могут быть проранжированы. Такими рядами значений могут быть:
1) два признака, измеренные в одной и той же группе испытуемых;
2) две индивидуальные иерархии признаков, выявленные у двух испытуемых по одному и тому же набору признаков (например, личностные профили по 16-факторному опроснику Р. Б. Кеттелла, иерархии ценностей по методике Р. Рокича, последовательности предпочтений в выборе из нескольких альтернатив и др.);
3) две групповые иерархии признаков;
4) индивидуальная и групповая иерархии признаков.
Вначале показатели ранжируются отдельно по каждому из признаков. Как правило, меньшему значению признака начисляется меньший ранг.
Рассмотрим случай 1 (два признака). Здесь ранжируются индивидуальные значения по первому признаку, полученные разными испытуемыми, а затем индивидуальные значения по второму признаку.
Если два признака связаны положительно, то испытуемые, имеющие низкие ранги по одному из них, будут иметь низкие ранги и по другому, а испытуемые, имеющие высокие ранги по одному из признаков, будут иметь по другому признаку также высокие ранги. Для подсчета rsнеобходимо определить разности (d) между рангами, полученными данным испытуемым по обоим признакам. Затем эти показатели d определенным образом преобразуются и вычитаются из 1. Чем меньше разности между рангами, тем больше будет rs, тем ближе он будет к 1.
Если корреляция отсутствует, то все ранги будут перемешаны и между ними не будет никакого соответствия. Формула составлена так, что в этом случае rs, окажется близким к 0.
В случае отрицательной корреляции низким рангам испытуемых по одному признаку будут соответствовать высокие ранги по другому признаку, и наоборот.
Чем больше несовпадение между рангами испытуемых по двумя переменным, тем ближе rs к -1.
Рассмотрим случай 2 (два индивидуальных профиля). Здесь ранжируются индивидуальные значения, полученные каждым из 2-х испытуемым по определенному (одинаковому для них обоих) набору признаков. Первый ранг получит признак с самым низким значением; второй ранг – признак с более высоким значением и т.д. Очевидно, что все признаки должны быть измерены в одних и тех же единицах, иначе ранжирование невозможно. Например, невозможно проранжировать показатели по личностному опроснику Кеттелла (16PF), если они выражены в “сырых” баллах, поскольку по разным факторам диапазоны значений различны: от 0 до 13, от 0 до 20 и от 0 до 26. Мы не можем сказать, какой из факторов будет занимать первое место по выраженности, пока не приведем все значения к единой шкале (чаще всего это шкала стенов).
Если индивидуальные иерархии двух испытуемых связаны положительно, то признаки, имеющие низкие ранги у одного из них, будут иметь низкие ранги и у другого, и наоборот. Например, если у одного испытуемого фактор Е (доминантность) имеет самый низкий ранг, то и у другого испытуемого он должен иметь низкий ранг, если у одного испытуемого фактор С (эмоциональная устойчивость) имеет высший ранг, то и другой испытуемый должен иметь по этому фактору высокий ранг и т.д.
Рассмотрим случай 3 (два групповых профиля). Здесь ранжируются среднегрупповые значения, полученные в 2-х группах испытуемых по определенному, одинаковому для двух групп, набору признаков. В дальнейшем линия рассуждений такая же, как и в предыдущих двух случаях.
Рассмотрим случай 4 (индивидуальный и групповой профили). Здесь ранжируются отдельно индивидуальные значения испытуемого и среднегрупповые значения по тому же набору признаков, которые получены, как правило, при исключении этого отдельного испытуемого – он не участвует в среднегрупповом профиле, с которым будет сопоставляться его индивидуальный профиль. Ранговая корреляция позволит проверить, насколько согласованы индивидуальный и групповой профили.
Во всех четырех случаях значимость полученного коэффициента корреляции определяется по количеству ранжированных значений N. В первом случае это количество будет совпадать с объемом выборки п. Во втором случае количеством наблюдений будет количество признаков, составляющих иерархию. В третьем и четвертом случае N – это также количество сопоставляемых признаков, а не количество испытуемых в группах. Подробные пояснения даны в примерах.
Если абсолютная величина rs достигает критического значения или превышает его, корреляция достоверна.
Гипотезы
Возможны два варианта гипотез. Первый относится к случаю 1, второй – к трем остальным случаям.
Первый вариант гипотез
H0: Корреляция между переменными А и Б не отличается от нуля.
H1: Корреляция между переменными А и Б достоверно отличается от нуля.
Второй вариант гипотез
H0: Корреляция между иерархиями А и Б не отличается от нуля.
H1:Корреляция между иерархиями А и Б достоверно отличается от нуля.
Графическое представление метода ранговой корреляции
Чаще всего корреляционную связь представляют графически в виде облака точек или в виде линий, отражающих общую тенденцию размещения точек в пространстве двух осей: оси признака А и признака Б (см. Рис. 6.2).
Попробуем изобразить ранговую корреляцию в виде двух рядов ранжированных значений, которые попарно соединены линиями (Рис. 6.3). Если ранги по признаку А и по признаку Б совпадают, то между ними оказывается горизонтальная линия, если ранги не совпадают, то линия становится наклонной. Чем больше несовпадение рангов, тем более наклонной становится линия. Слева на Рис. 6.3 отображена максимально высокая положительная корреляция (rв= 1,0) – практически это “лестница”. В центре отображена нулевая корреляция – плетенка с неправильными переплетениями. Все ранги здесь перепутаны. Справа отображена максимально высокая отрицательная корреляция (rs=-1,0) -паутина с правильным переплетением линий.
Рис. 6.3. Графическое представление ранговой корреляции:
а) высокая положительная корреляция;
б) нулевая корреляция;
в) высокая отрицательная корреляция

Ограничения коэффициента ранговой корреляции
1. По каждой переменной должно быть представлено не менее 5 наблюдений. Верхняя граница выборки определяется имеющимися таблицами критических значений (Табл.XVI Приложения 1), а именно N≤40.
2. Коэффициент ранговой корреляции Спирмена rs при большом количестве одинаковых рангов по одной или обеим сопоставляемым переменным дает огрубленные значения. В идеале оба коррелируемых ряда должны представлять собой две последовательности несовпадающих значений. В случае, если это условие не соблюдается, необходимо вносить поправку на одинаковые ранги. Соответствующая формула дана в примере 4.
Пример 1 – корреляция между двумя признаками
В исследовании, моделирующем деятельность авиадиспетчера (Одерышев Б.С., Шамова Е.П., Сидоренко Е.В., Ларченко Н.Н., 1978), группа испытуемых, студентов физического факультета ЛГУ проходила подготовку перед началом работы на тренажере. Испытуемые должны были решать задачи по выбору оптимального типа взлетно-посадочной полосы для заданного типа самолета. Связано ли количество ошибок, допущенных испытуемыми в тренировочной сессии, с показателями вербального и невербального интеллекта, измеренными по методике Д. Векслера?
Таблица 6.1
Показатели количества ошибок в тренировочной сессии и показатели уровня вербального и невербального интеллекта у студентов-физиков (N=10)
| Испытуемый | Количество ошибок | Показатель вербального интеллекта | Показатель невербального интеллекта | |
| 1 | Т.А. | 29 | 131 | 106 |
| 2 | П.А. | 54 | 132 | 90 |
| 3 | Ч.И. | 13 | 121 | 95 |
| 4 | Ц.А. | 8 | 127 | 116 |
| 5 | См.А. | 14 | 136 | . 127 |
| 6 | К.Е. | 26 | 124 | 107 |
| 7 | К.А. | 9 | 134 | 104 |
| 8 | Б.Л. | 20 | 136 | 102 |
| 9 | И.А. | 2 | 132 | 111 |
| 10 | Ф.В. | 17 | 136 | 99 |
| Суммы | 192 | 1309 | 1057 | |
| Средние | 19,2 | 130,9 | 105,7 | |
Сначала попробуем ответить на вопрос, связаны ли между собой показатели количества ошибок и вербального интеллекта.
Сформулируем гипотезы.
H0: Корреляция между показателем количества ошибок в тренировочной сессии и уровнем вербального интеллекта не отличается от нуля.
H1: Корреляция между показателем количества ошибок в тренировочной сессии и уровнем вербального интеллекта статистически значимо отличается от нуля.
Далее нам необходимо проранжировать оба показателя, Приписывая меньшему значению меньший ранг, затем подсчитать разности между рангами, которые получил каждый испытуемый по двум переменным (признакам), и возвести эти разности в квадрат. Произведем все необходимые расчеты в таблице.
В Табл. 6.2 в первой колонке слева представлены значения по показателю количества ошибок; в следующей колонке – их ранги. В третьей колонке слева представлены значения по показателю вербального интеллекта; в следующем столбце – их ранги. В пятом слева представлены разности dмежду рангом по переменной А (количество ошибок) и переменной Б (вербальный интеллект). В последнем столбце представлены квадраты разностей – d2.
Таблица 6.2
Расчет d2для рангового коэффициента корреляции Спирмена rs при сопоставлении показателей количества ошибок и вербального интеллекта у студентов-физиков (N=10)
| Испытуемый | Переменная А количество ошибок | Переменная Б вербальный интеллект. | d(ранг А – – ранг Б) | J2 | ||||
| Индивидуальные значения | Ранг | Индивидуальные значения | Ранг | |||||
| 1 | ТА. | 29 | 9 | 131 | 4 | 5 | 25 | |
| 2 | ПА. | 54 | 10 | 132 | 5.5 | 4,5 | 20.25 | |
| 3 | Ч.И. | 13 | 4 | 121 | 1 | 3 | 9 | |
| 4 | Ц.А. | 8 | 2 | 127 | 3 | -1 | 1 | |
| 5 | См.А. | 14 | 5 | 136 | 9 | -4 | 16 | |
| 6 | К.Е. | 26 | 8 | 124 | 2 | 6 | 36 | |
| 7 | К.А. | 9 | 3 | 134 | 7 | -4 | 16 | |
| 8 | Б.Л. | 20 | 7 | 136 | 9 | -2 | 4 | |
| 9 | И.А. | 2 | 1 | 132 | 5,5 | -4,5 | 20,25 | |
| 10 | Ф.В. | 17 | 6 | 136 | 9 | 9 | ||
| Суммы | 55 | 55 | 0 | 156,5 | ||||
Коэффициент ранговой корреляции Спирмена подсчитывается по формуле:

где d – разность между рангами по двум переменным для каждого испытуемого;
N – количество ранжируемых значений, в. данном случае количество испытуемых.
Рассчитаем эмпирическое значение rs:
![]()
Полученное эмпирическое значение гs близко к 0. И все же определим критические значения rs при N=10 по Табл. XVI Приложения 1:

Ответ: H0принимается. Корреляция между показателем количества ошибок в тренировочной сессии и уровнем вербального интеллекта не отличается от нуля.
Теперь попробуем ответить на вопрос, связаны ли между собой показатели количества ошибок и невербального интеллекта.
Сформулируем гипотезы.
H0: Корреляция между показателем количества ошибок в тренировочной сессии и уровнем невербального интеллекта не отличается от 0.
H1: Корреляция между показателем количества ошибок в тренировочной сессии и уровнем невербального интеллекта статистически значимо отличается от 0.
Результаты ранжирования и сопоставления рангов представлены в Табл. 6.3.
Таблица 6.3
Расчет d2для рангового коэффициента корреляции Спирмена rs при сопоставлении показателей количества ошибок и невербального интеллекта у студентов-физиков (N=10)
| Испытуемый | Переменная А количество ошибок | Переменная Е ; невербальный интеллект | d(ранг А — — ранг Б) | d2 | |||
| Индивидуальные | Ранг | Индивидуальные | Ранг | ||||
| значения | значения | ||||||
| 1 | Т.А. | 29 | 9 | 106 | 6 | 3 | 9 |
| 2 | П:А. | 54 | 10 | 90 | 1 | 9 | 81 |
| 3 | Ч.И. | 13 | 4 | 95 | 2 | 2 | 4 |
| 4 | Ц-А. „ | 8 | 2 | 116 | 9 | -7 | 49 |
| 5 | См.А. | 14 | 5 | 127 | 10 | -5 | 25 |
| 6 | К.Е. | 26 | 8 | 107 | 7 | 1 | 1 |
| 7 | К.А. | 9 | 3 | 104 | 5 | -2 | 4 |
| 8 | Б.Л. | 20 | 7 | 102 | 4 | 3 | 9 |
| 9 | И.А. | 2 | 1 | 111 | 8 | -7 | 49 |
| 10 | Ф.В. | 17 | 6 | 99 | 3 | 3 | 9 |
| Суммы | 55 | 55 | 0 | 240 | |||

Мы помним, что для определения значимости rs неважно, является ли он положительным или отрицательным, важна лишь его абсолютная величина. В данном случае:
rs эмпs ко.
Ответ: H0 принимается. Корреляция между показателем количества ошибок в тренировочной сессии и уровнем невербального интеллекта случайна, rs не отличается от 0.
Вместе с тем, мы можем обратить внимание на определенную тенденцию отрицательной связи между этими двумя переменными. Возможно, мы смогли бы ее подтвердить на статистически значимом уровне, если бы увеличили объем выборки.
<< предыдущая страница следующая страница >>
§
Пример 2 – корреляция между индивидуальными профилями
В исследовании, посвященном проблемам ценностной реориента-ции, выявлялись иерархии терминальных ценностей по методике М. Рокича у родителей и их взрослых детей (Сидоренко Е.В., 1996). Ранги терминальных ценностей, полученные при обследовании пары мать-дочь (матери – 66 лет, дочери – 42 года) представлены в Табл. 6.4. Попытаемся определить, как эти ценностные иерархии коррелируют друг с другом.
Таблица 6.4
Ранги терминальных ценностей по списку М.Рокича в индивидуальных иерархиях матери и дочери
| Ряд1: | Ряд 2: | |||
| Терминальные ценности | Ранг ценностей в | Ранг ценностей в | d | d2 |
| иерархии матери | иерархии дочери | |||
| 1 Активная деятельная жизнь | 15 | 15 | 0 | 0 |
| 2 Жизненная мудрость | 1 | 3 | -2 | 4 |
| 3 Здоровье | 7 | 14 | -7 | 49 |
| 4 Интересная работа | 8 | 12 | -4 | 16 |
| 5 Красота природы и искусство | 16 | 17 | -1 | 1 |
| 6 Любовь | 11 | 10 | 1 | 1 |
| 7 Материально обеспеченная жизнь | 12 | 13 | -1 | 1 |
| 8 Наличие хороших и верных друзей | 9 | 11 | -2 | 4 |
| 9 Общественное признание | 17 | 5 | 12 | 144 |
| 10 Познание | 5 | 1 | 4 | 16 |
| 11 Продуктивная жнзнь | 2 | 2 | 0 | 0 |
| 12 Развитие | 6 | 8 | -2 | 4 |
| 13 Развлечения | 18 | 18 | 0 | 0 |
| 14 Свобода | 4 | 6 | -2 | 4 |
| 15 Счастливая семейная жизнь | 13 | 4 | 9 | 81 |
| 16 Счастье других | 14 | 16 | -2 | 4 |
| 17 Творчество | 10 | 9 | 1 | 1 |
| 18 Уверенность в себе | 3 | 7 | -4 | 16 |
| Суммы | 171 | 171 | 0 | 346 |
Сформулируем гипотезы.
H0: Корреляция между иерархиями терминальных ценностей матери и дочери не отличается от нуля.
H1: Корреляция между иерархиями терминальных ценностей матери и дочери статистически значимо отличается от нуля.
Поскольку ранжирование ценностей предполагается самой процедурой исследования, нам остается лишь подсчитать разности между рангами 18 ценностей в двух иерархиях . В 3-м и 4-м столбцах Табл. 6.4 представлены разности dи квадраты этих разностей d6.
Определяем эмпирическое значение rs по формуле:
![]()
где d– разности между рангами по каждой из переменных, в данном случае по каждой из терминальных ценностей;
N – количество переменных, образующих иерархию, в данном случае количество ценностей.
Для данного примера:
![]()
По Табл. XVI Приложения 1 определяем критические значения:

Ответ: H0отвергается. Принимается H1. Корреляция между иерархиями терминальных ценностей матери и дочери статистически значима (р<0,01) и является положительной.
По данным Табл. 6.4 мы можем определить, что основные расхождения приходятся на ценности “Счастливая семейная жизнь”, “Общественное признание” и “Здоровье”, ранги остальных ценностей достаточно близки.
Пример 3 – корреляция между двумя групповыми иерархиями
Джозеф Вольпе в книге, написанной совместно с сыном (Wolpe J., Wolpe D., 1981) приводит упорядоченный перечень из наиболее часто встречающихся у современного человека “бесполезных”, по его обозначению, страхов, которые не несут сигнального значения и лишь мешают полноценно жить и действовать. В отечественном исследовании, проведенном М.Э. Раховой (1994) 32 испытуемых должны были по 10-балльной шкале оценить, насколько актуальным для них является тот или иной вид страха из перечня Вольпе7. Обследованная выборка состояла из студентов Гидрометеорологического и Педагогического институтов Санкт-Петербурга: 15 юношей и 17 девушек в возрасте от 17 до 28 лет, средний возраст 23 года.
Данные, полученные по 10-балльной шкале, были усреднены по 32 испытуемым, и средние проранжированы. В Табл. 6.5 представлены ранговые показатели, полученные Дж. Вольпе и М. Э. Раховой. Совпадают ли ранговые последовательности 20 видов страха?
Сформулируем гипотезы.
H0: Корреляция между упорядоченными перечнями видов страха в американской и отечественных выборках не отличается от нуля.
H1: Корреляция между упорядоченными перечнями видов страха в американской и отечественной выборках статистически значимо отличается от нуля.
Все расчеты, связанные с вычислением и возведением в квадрат разностей между рангами разных видов страха в двух выборках, представлены в Табл. 6.5.
Таблица 6.5
Расчет dдля рангового коэффициента корреляции Спирмена при сопоставлении упорядоченных перечней видов страха в американской и отечественной выборках
| Виды страха | Ранг в американской выборке | Ранг в российской выборке | d | d2 | |
| 1 | Страх публичного выступления | 1 | 7 | -6 | 36 |
| 2 | Страх полета | 2 | 12 | -10 | 100 |
| 3 | Страх совершить ошибку | 3 | 10 | -7 | 49 |
| 4 | Страх неудачи | 4 | 6 | -2 | 4 |
| 5 | Страх неодобрения | 5 | 9 | -4 | 16 |
| 6 | Страх отвержения | 6 | 2 | 4 | 16 |
| 7 | Страх злых люден | 7 | 5 | 2 | 4 |
| 8 | Страх одиночества | 8 | 1 | 7 | 49 |
| 9 | Страх крови | 9 | 16 | -7 | 49 |
| 10 | Страх открытых ран | 10 | 13 | -3 | 9 |
| И | Страх дантиста | 11 | 3 | 8 | 64 |
| 12 | Страх уколов | 12 | 19 | -7 | 49 |
| 13 | Страх прохождения тестов | 13 | 20 | -7 | 49 |
| 14 | Страх полиции ^милиции) | 14 | 17 | -3 | 9 |
| 15 | Страх высоты | 15 | 4 | 11 | 121 |
| 16 | Страх собак | 16 | 11 | 5 | 25 |
| 17 | Страх пауков | 17 | 18 | -1 | 1 |
| 18 | Страх искалеченных людей | 18 | 8 | 10 | 100 |
| 19 | Страх больниц | 19 | 15 | 4 | 16 |
| 20 | Страх темноты | 20 | 14 | 6 | 36 |
| Суммы | 210 | 210 | 0 | 802 | |
Определяем эмпирическое значение r
s
:
![]()
По Табл. XVI Приложения 1 определяем критические значения гs при N=20:

Ответ: H0 принимается. Корреляция между упорядоченными перечнями видов страха в американской и отечественной выборках не достигает уровня статистической значимости, т. е. значимо не отличается от нуля.
Пример 4 – корреляция между индивидуальным и среднегрупповым профилями
Выборке петербуржцев в возрасте от 20 до 78 лет (31 мужчина, 46 женщин), уравновешенной по возрасту таким образом, что лица в возрасте старше 55 лет составляли в ней 50%8, предлагалось ответить на вопрос: “Какой уровень развития каждого из перечисленных ниже качеств необходим для депутата Городского собрания Санкт-Петербурга?” (Сидоренко Е.В., Дерманова И.Б., Анисимова О.М., Витенберг Е.В., Шульга А.П., 1994). Оценка производилась по 10-балльной шкале. Параллельно с этим обследовалась выборка из депутатов и кандидатов в депутаты в Городское собрание Санкт-Петербурга (n=14). Индивидуальная диагностика политических деятелей и претендентов производилась с помощью Оксфордской системы экспресс-видеодиагностики по тому же набору личностных качеств, который предъявлялся выборке избирателей.
В Табл. 6.6 представлены средние значения, полученные для каждого из качеств в выборке избирателей (“эталонный ряд”) и индивидуальные значения одного из депутатов Городского собрания.
Попытаемся определить, насколько индивидуальный профиль депутата К-ва коррелирует с эталонным профилем.
Таблица 6.6
Усредненные эталонные оценки избирателей (п=77) и индивидуальные показатели депутата К-ва по 18 личностным качествам экспресс-видеодиагностики
| Наименование качества | Усредненные эталонные оценки избирателей | Индивидуальные показатели депутата К-ва |
| 1. Общий уровень культуры | 8,64 | 15 |
| 2. Обучаемость | 7,89 | 7 |
| 3. Логика | 8,38 | 12 |
| 4. Способность к творчеству нового | 6,97 | 5 |
| 5.. Самокритичность | 8,28 | 14 |
| 6. Ответственность | 9,56 | 18 |
| 7. Самостоятельность | 8,12 | 13 |
| 8. Энергия, активность | 8,41 | 17 |
| 9. Целеустремленность | 8,00 | 19 |
| 10. Выдержка, самообладание | 8,71 | 9 |
| И. Стойкость | 7,74 | 16 |
| 12. Личностная зрелость | 8,10 | 11 |
| 13. Порядочность | 9,02 | 12 |
| 14. Гуманизм | 7.89 | 10 |
| 15. Умение общаться с людьми | 8,74 | 8 |
| 16. Терпимость к чужому мнению | 7.84 | 6 |
| 17. Гибкость поведения | 7,67 | 4 |
| 18. Способность производить благоприятное впечатление | 7,23 | 8 |
Таблица 6.7
Расчет d2для рангового коэффициента корреляции Спирмена между эталонным и индивидуальным профилями личностных качеств депутата
| Наименование качества | Ряд 1: ранг качества в эталонном профиле | Ряд 2: ранг качества в индивидуальном профиле | d | d2 |
| 1 Ответственность | 1 | 2 | -1 | 1 |
| 2 Порядочность | 2 | 8,5 | -6,5 | 42,25 |
| 3 Умение общаться с людьми | 3 | 13,5 | -10,5 | 110,25 |
| 4 Выдержка, самообладание | 4 | 12 | -8 | 64 |
| 5 Общий уровень культуры | 5 | 5 | 0 | 0 |
| 6 Энергия, активность | 6 | 3 | 3 | 9 |
| 7 Логика | 7 | 8,5 | -1,5 | 2,25 |
| 8 Самокритичность | 8 | 6 | 2 | 4 |
| 9 Самостоятельность | 9 | 7 | 2 | 4 |
| 10 Личностная зрелость | 10 | 10 | 0 | 0 |
| И Целеустремленность | И | 1 | 10 | 100 |
| 12 Обучаемость | 12,5 | 15 | -2,5 | 6,25 |
| 13 Гуманизм | 12,5 | И | 1,5 | 2,25 |
| 14 Терпимость к чужому мнению | 14 | 16 | -2 | 4 |
| 15 Стойкость | 15 | 4 | 11 | 121 |
| 16 Гибкость поведения | 16 | 18 | -2 | 4 |
| 17 Способность производить благоприятное впечатление | 17 | 13,5 | 3,5 | 12,25 |
| 18 Способность к творчеству нового | 18. | 17 | 1 | 1 |
| Суммы | 171 | 171 | 0 | 487,5 |
Как видно из Табл. 6.6, оценки избирателей и индивидуальные показатели депутата варьируют в разных диапазонах. Действительно оценки избирателей были получены по 10-балльной шкале, а индивидуальные показатели по экспресс-видеодиагностике измеряются по 20-ти балльной шкале. Ранжирование позволяет нам перевести обе шкалы измерения в единую шкалу, где единицей измерения будет 1 ранг, а максимальное значение составит 18 рангов.
Ранжирование, как мы помним, необходимо произвести отдельно по каждому ряду значений. В данном случае целесообразно начислять большему значению меньший ранг, чтобы сразу можно было увидеть, на каком месте по значимости (для избирателей) или по выраженности (у депутата) находится то или иное качество.
Результаты ранжирования представлены в Табл. 6.7. Качества перечислены в последовательности, отражающей эталонный профиль.
Сформулируем гипотезы.
H0: Корреляция между индивидуальным профилем депутата К-ва и эталонным профилем, построенным по оценкам избирателей, не отличается от нуля.
H1: Корреляция между индивидуальным профилем депутата К-ва и эталонным профилем, построенным по оценкам избирателей, статистически значимо отличается от нуля. Поскольку в обоих сопоставляемых ранговых рядах присутствуют
группы одинаковых рангов, перед подсчетом коэффициента ранговой
корреляции необходимо внести поправки на одинаковые ранги Та и Тb:
![]()
где а – объем каждой группы одинаковых рангов в ранговом ряду А,
b – объем каждой группы одинаковых рангов в ранговом ряду В.
В данном случае, в ряду А (эталонный профиль) присутствует одна группа одинаковых рангов – качества “обучаемость” и “гуманизм” имеют один и тот же ранг 12,5; следовательно, а=2.
Tа=(23-2)/12=0,50.
В ряду В (индивидуальный профиль) присутствует две группы одинаковых рангов, при этом b1=2 и b2=2.
Ta=[(23-2) (23-2)]/12=1,00
Для подсчета эмпирического значения rs используем формулу
![]()
В данном случае:
![]()
Заметим, что если бы поправка на одинаковые ранги нами не вносилась, то величина rs была бы лишь на (на 0,0002) выше:
![]()
При больших количествах одинаковых рангов изменения г5 могут оказаться гораздо более существенными. Наличие одинаковых рангов означает меньшую степень дифференцированное™ упорядоченных переменных и, следовательно, меньшую возможность оценить степень связи между ними (Суходольский Г.В., 1972, с.76).
По Табл. XVI Приложения 1 определяем критические значения г, при N=18:

Ответ: Hqотвергается. Корреляция между индивидуальным профилем депутата К-ва и эталонным профилем, отвечающим требованиям избирателей, статистически значима (р<0,05) и является положительной.
Из Табл. 6.7 видно, что депутат К-в имеет более низкий ранг по шкалам Умения общаться с людьми и более высокие ранги по шкалам Целеустремленности и Стойкости, чем это предписывается избирательским эталоном. Этими расхождениями, главным образом, и объясняется некоторое снижение полученного rs.
Сформулируем общий алгоритм подсчета rs.
АЛГОРИТМ 20
Расчет коэффициента ранговой корреляции Спирмена rs.
1. Определить, какие два признака или две иерархии признаков будут участвовать в сопоставлении как переменные А и В.
2. Проранжировать значения переменной А, начисляя ранг 1 наименьшему значению, в соответствии с правилами ранжирования (см. п.2.3). Занести ранги в первый столбец таблицы по порядку номеров испытуемых или признаков.
3. Проранжировать значения переменной В, в соответствии с теми же правилами. Занести ранги во второй столбец таблицы по порядку номеров испытуемых или признаков.
4. Подсчитать разности dмежду рангами А и В по каждой строке таблицы и занести в третий столбец таблицы.
5. Возвести каждую разность в квадрат: d2 . Эти значения занести в четвертый столбец таблицы.
6. Подсчитать сумму квадратов ∑d2.
7. При наличии одинаковых рангов рассчитать поправки:
![]()
где а – объем каждой группы одинаковых рангов в ранговом ряду А;
b– объем каждой группы одинаковых рангов в ранговом ряду В.
8. Рассчитать коэффициент ранговой корреляции г5 по формуле:
а) при отсутствии одинаковых рангов
![]()
б) при наличии одинаковых рангов
![]()
где ∑d2 – сумма квадратов разностей между рангами*
Таи Tb, – поправки на одинаковые ранги;
N – количество испытуемых или признаков, участвовавших в ранжировании.
9. Определить по Табл. XVI Приложения 1 критические значения гsдля данного N. Если rs превышает критическое значение или по крайней мере равен ему, корреляция достоверно отличается от 0.
<< предыдущая страница
Тема 7. многофункциональные статистические критерии
Цель: Научиться применять критерии математической статистики для психологических задач предыдущих трех типов (типа сопоставить или сравнить две выборки по какому-либо качественно измеренному признаку; типа исследования изменений в значениях признака у одной и той же выборки испытуемых при замерах в двух определенных условиях, типа сравнения распределений признака) с помощью многофункциональных критериев j* – углового преобразования Фишера и биномиального – m.
Задачи:
1. Познакомиться с критериями j* и m.
2. Решение задач с использованием этих критериев.
3. Показать способы интерпретации результатов, где в обработке применяются данные критерия.
Теория.
Многофункциональные статистические критерии могут обрабатывать данные, измеренные в любой шкале. Сравниваемые выборки могут быть как «связные», так и независимые. Многофункциональные критерии позволяют решать задачи сопоставления уровней исследуемого признака, сдвигов в значениях исследуемого признака и сравнения распределений.
Данные критерии построены на сопоставлении долей, выраженных в долях единицы или в процентах. Суть критериев состоит в определении того, какая доля наблюдений в данной выборке характеризуется интересующим исследователя эффектом.
Таким эффектом может быть:
а) определенное значение качественно определяемого признака – например, решил задачу; выразил согласие с каким-либо предложением; наличие страха;
б) определенный уровень количественно измеряемого признака – например, решил задачу по I типу; выполнил задание менее, чем за 40 сек.;
в) определенное соотношение значений или уровней исследуемого признака – например, более частый выбор альтернатив А и Б по сравнению с альтернативами В и Г;
Критерий j*– углового преобразования Фишера.
Критерий предназначен для сопоставления двух выборок по частоте встречаемости интересующего исследователя эффекта. Оценивает достоверность различий между процентными долями двух выборок, в которых зарегистрирован интересующий нас эффект. Суть критерия состоит в переводе процентных долей в величины центрального угла, который измеряется в радианах, по формуле:
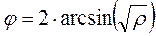
Ограничения: 1)если n1=2, то n2³30; 2) если n1=3, то n2³7; 3) если n1=4, то n2³5; 4) при n1, n2³5 возможны любые сопоставления.
Вычисление:
1) определить, что будет в данной задаче эффектом. Если данные, измеренные количественно, использовать критерий l для поиска оптимальной точки разделения.
4) перевести по таблице 8 приложения 2 процентные доли в величины им соответствующих углов.
6) Сопоставить эмпирические значения с критическими, где j*0,01=2,31, а j*0,05=1,64.
Различия между выборками считаются достоверными, если j*эмп³j*0,01; не значимыми, если j*эмп< j*0,05; достоверными на 5% уровне, если
j*0,05£ j*эмп <j*0,01.
Пример.С учащимися младшего школьного возраста 18 человек из полных семей и 18 из неполных проводилось исследование на определение степени допустимости лжи по тесту Р. Экмана. В таблице 51 представлены результаты мотива «избегание наказания». Можно ли утверждать, что у младших школьников из полных семей данный мотив более выражен.
Таблица 51
Количество детей с выраженностью мотива «избегание наказания»
| Тип семьи | Мотив выражен | Мотив не выражен |
| полная | ||
| неполная |
Решение: проверим ограничения: n1=18, n2=18>5, следовательно, применим критерий j*. Будем считать, что «есть эффект» – выраженность мотива «избегание наказания». k1=5; k2=2. p1=27,8%; p2=11,1%.
Сформулируем экспериментальную гипотезу: у младших школьников из полных семей мотив «избегание наказания» более выражен, чем у детей из неполных семей.
j*эмп< j*0,05 следовательно экспериментальная гипотеза отвергается.
Ответ: у младших школьников из полных и неполных семей выраженность мотива «избегание наказания» не различается.
Биноминальный критерий – m
Критерий предназначен для сопоставления частоты встречаемости какого-либо эффекта с теоретической или заданной частотой его встречаемости. Он применяется в тех случаях, когда обследована лишь одна выборка.
Вычисление:
1) определим, что будет в данном случае эффектом и какова его вероятность r при теоретическом рассмотрении (см. 3 занятие);
2) вычислить теоретическую вероятность по формуле fтеор=n×r;
3) определить эмпирическую частоту встречаемости эффекта – fэмп.
4) определить по таблице, в зависимости от r, соотношения fэмп и fтеор, а также учитывая ограничения на объем выборки n, какой критерий применим в данном случае для обработки данных.
Таблица 52
Выбор критерия для сопоставления эмпирической частоты с теоретической при разных вероятностях исследуемого эффекта r
| Заданная вероятность | fэмп > fтеор | fэмп < fтеор |
| r < 0,5 | m для 2£n£50 | c2 для n³30 |
| r = 0,5 | m для 5£n£300 | G для 5£n£300 |
| r > 0,5 | c2 для n³30 | m для 2£n£50 |
5) если применим критерий m,то mэмп=fэмп. Далее находим критические значения по таблице 9 или 10 приложения 2 для данного n и r. Эмпирическая частота считается достоверно выше теоретической, если mэмп³m0,01; не превосходит, если mэмп< m0,05; достоверно выше на 5% уровне, если m0,05£ mэмп <m0,01. (Примечание: когда r>0,5 и fэмп < fтеор, рекомендуется поменять эффект на противоположный, и тогда получится случай r<0,5 и fэмп > fтеор).
Если применим критерий G, то Gэмп=fэмп. Далее находим критические значения по таблице 3 приложения 2 для данного n. Эмпирическая частота считается достоверно ниже теоретической, если Gэмп£G0,01; не ниже, если Gэмп>G0,05; достоверно ниже на 5% уровне, если G0,01< Gэмп £G0,05.
Если применим критерий c2, то
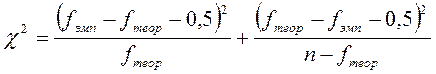 .
.
В данном случае n=1, поэтому c20,01=6,635, а c20,05=3,841 Если c2>c20,01, то эмпирическая частота считается достоверно выше (ниже) теоретической, если c2£c20,05, то не превышает (не ниже), если c20,05<c2£c20,01, то значимо выше (ниже) на 5% уровне.
Пример. В исследовании внутреннего плана действия (ВПД) Я.А. Пономарева в 1 классе в конце учебного года было следующее распределение на уровни (таблица 53). Отличается ли обследованный 1 класс «А» (30 человек) по количеству детей, находящихся на I уровне (4 учащихся) и V уровне (1 учащийся) от выборки Я.А. Пономарева?
Таблица 53
Процент детей, относящихся к разным уровням развития ВПД (по Я.А. Пономареву)
Решение: n=30. Для начала определим «есть эффект» – учащиеся, находящиеся на I уровне.
Тогда, fэмп=4, 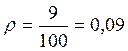 .
.
fт=0,09×30=2,7. fэмп>fт, r<0,5, n=30 следовательно применим критерий m.
Сформулируем экспериментальную гипотезу: количество учащихся, находящихся на 1 уровне, в 1 классе «А» выше, чем в выборке Я.А. Пономарева.
mэмп=fэмп=4. Для r=0,09, n=30 определим по таблице 10 приложения 2 m0,01=8, m0,05=6. mэмп <m0,05 следовательно экспериментальная гипотеза отвергается. Далее определим «есть эффект» – учащиеся, находящиеся на V уровне.
Тогда, fэмп=1, 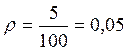 . fт=0,05×30=1,5
. fт=0,05×30=1,5
fэмп<fт, r<0,5, n=30, следовательно, применим критерий c2.
Сформулируем экспериментальную гипотезу: количество учащихся, находящихся на V уровне, в 1 классе «А» ниже, чем в выборке Я.А.Пономарева.
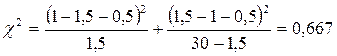
c2<c20,05, следовательно, экспериментальная гипотеза отвергается.
Ответ: учащиеся 1 класса «А» по уровню развития ВПД не отличаются от выборки Я.А. Пономарева, если судить только по 1 и 5 уровням развития.
Пример. С подростками 11 лет проводился опросник «Я-концепция» Пирс-Хариса. На вопрос «Когда я вырасту, я стану важным лицом» из 17 девочек ответили «да» 8, а из 13 мальчиков – 9. Можно ли утверждать, что на данный вопрос в этом возрасте девочки достоверно чаще отвечают «нет», а мальчики достоверно чаще «да».
Решение: определим «есть эффект» – ответ на вопрос «да». Теоретически на данный вопрос ответы «да» и «нет» равнозначны. следовательно
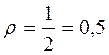 .
.
Решим задачу для девочек: n=17, fэмп=8. fт=17×0,5=8,5
fэмп<fт, r=0,5, n=17, следовательно, применим критерий G.
Сформулируем экспериментальную гипотезу: у девочек 11 лет реже встречаются ответы «да», чем «нет».
Gэмп=8 Для n=17 по таблице 3 приложения 2. G0,01=3 G0,05=4.
Gэмп>G0,05, следовательно, экспериментальная гипотеза отвергается.
Решим задачу для мальчиков: n=13, fэмп=9.
fт=13×0,5=6,5. fэмп>fт, r=0,5, n=17 следовательно применим критерий m.
Сформулируем экспериментальную гипотезу: у мальчиков 11 лет чаще встречаются ответы «да», чем «нет».
mэмп=9 Для r=0,5, n=13 по таблице 10 приложения 2 m0,01=12 m0,05=10.
mэмп<m0,05, следовательно, экспериментальная гипотеза отвергается.
Ответ: В данной выборке подростков на вопрос «Когда я вырасту, я стану важным лицом» как девочки, так и мальчики одинаково часто отвечают «да» и «нет».
Пример. В пособии «Диагностика психолого-социальной дезадаптации детей и подростков. Психологический практикум. Методические рекомендации» под ред. Т.А. Шиловой приводятся результаты исследования словесно-логического мышления детей 7-8 лет по тесту Р. Амтхауера в модификации Л.И. Переслени. Так, в данном возрасте в среднем справляются с 73% заданий, предложенных в тесте. В 1 классе «А», где много внимания уделяют формированию мыслительных действий, из 40 заданий в среднем справились с 36,6, а в 1 классе «В» (класс коррекции) – с 20,8. Можно ли утверждать, что класс «А» достоверно превосходит среднестатистическую норму, а класс «В» достоверно ниже этой нормы.
Решение: определим «есть эффект» – справились с заданиями. n=40, 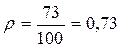 , fт=29,2.
, fт=29,2.
Решим задачу для 1 «А» класса. fэмп=36,6
fэмп >fт, r>0,5, n=40, следовательно, применим критерий c2.
Сформулируем экспериментальную гипотезу:
1 «А» класс по уровню решения словесно-логических задач превосходит среднестатистическую норму.
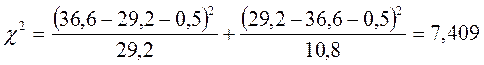
c2>c20,01 следовательно экспериментальная гипотеза подтверждается.
Решим задачу для 1 «В» класса. fэмп=20,8
fэмп <fт, r>0,5, n=40 следовательно применим критерий m. В этом случае поменяем «есть эффект» на «не справился с заданиями», тогда r=1-0,73=0,27,
fт=40-29,2=10,8, fэмп=40-20,8=19,2.
Сформулируем экспериментальную гипотезу: 1 «В» класс по несформированности уровня решения словесно-логических задач превосходит среднестатистическую норму.
mэмп=19,2. Для n=40, r=0,27 по таблице 11 приложения 2 определим m0,01=19 m0,05=17.
mэмп >m0,01, следовательно, экспериментальная гипотеза подтверждается.
Ответ: класс «А» достоверно превосходит среднестатистическую норму, а класс «В» достоверно ниже этой нормы.
Задачи:
7.1. С детьми 4-х возрастных групп проводилось исследование осознания временных отношений. Результаты представлены в таблице 54. Определите, от какого к какому возрасту происходят значительные изменения данного показателя.
Таблица 54
Результаты исследования осознания временных отношений детьми 3-7 лет
| Возраст | Количество обследованных детей | Количество детей, справившихся с заданием |
| 3-4 года | ||
| 4-5 лет | ||
| 5-6 лет | ||
| 6-7 лет |
7.2. В группе детей 5-6 лет проводилась беседа на выявление страхов (Методика А.И.Захарова) у 28 девочек и 24 мальчиков. В таблице 55 приведены результаты лишь 5 страхов. Выявляются ли половые различия выраженности страхов у детей?
Таблица 55
Выраженность страхов у детей 5-6 лет
| Девочки | Мальчики | ||||||||||
| Назв. стра- ха Имя | Остаться одному | Заболеть | Умереть | Перед каки-ми-то детьми | Наказания | Назв. стра- ха Имя | Остаться одному | Заболеть | Умереть | Перед каки-ми-то детьми | Наказания |
| Елена | Саша | ||||||||||
| Ирина | Игорь | ||||||||||
| Женя | Марат | ||||||||||
| Рита | Кирилл | ||||||||||
| Кристина | Костя | ||||||||||
| Лилия | Ильнур | ||||||||||
| Регина | Арикназ | ||||||||||
| Айгуль | Сергей | ||||||||||
| Ксюша | Игорь | ||||||||||
| Эльза | Борис | ||||||||||
| Наташа | Глеб | ||||||||||
| Регина | Юра | ||||||||||
| Полина | Коля | ||||||||||
| Юля | Олег | ||||||||||
| Нурия. | Ирик | ||||||||||
| Лиля | Эдик | ||||||||||
| Гульнур | Денис | ||||||||||
| Света | Максим | ||||||||||
| Наташа | Глеб | ||||||||||
| Эльвира | Артур | ||||||||||
| Гуля | Артур | ||||||||||
| Нурия | Артем | ||||||||||
| Света | Кирилл | ||||||||||
| Алия. | Альберт | ||||||||||
| Эльмира | Примечание: 1 – наличие страха 0 – отсутствие страха | ||||||||||
| Алена | |||||||||||
| Даша | |||||||||||
| Ирина |
7.3. Различаются ли дети средней и подготовительной группы по типу отношений, если в средней группе тип сотрудничества в совместной работе выбирают 10 человек из 17, а в подготовительной группе из 20 – 18 человек.
7.4. У студентов первокурсников изучалась мотивация к учебному процессу. Были выявлены три уровня: высокий, средний и низкий. Далее у всех тех групп исследовались трудности, оказывающие влияние на процесс адаптации к вузу. Результаты даны в таблице 56. Выявляются ли значимые различия между студентами с разным уровнем мотивации по выраженности трудностей?
Таблица 56
Показатели успешности адаптации у студентов первокурсников с низкой, средней и высокой мотивации к учебному процессу
| Трудности | Высокая | Средняя | Низкая |
| Дидактические | |||
| Социально-психологические | |||
| Профессиональные |
7.5. В тренинге профессиональных наблюдателей допускается, чтобы наблюдатель ошибался в оценке возраста не более чем на 1 год в ту или иную сторону. Наблюдатель допускается к работе, если он совершает не более 15% ошибок, превышающих отклонение на 1 год. Наблюдатель Н допустил одну ошибку в 50-ти попытках, а наблюдатель К – 15 ошибок в 50-ти попытках. Достоверно ли отличаются эти результаты от контрольной величины?
Таблица 57
Количество студентов, относящихся к полезависимому и поленезависимму стилю
| Стиль | ПЗ | ПНЗ |
| Физико-математ | ||
| Филологический |
7.6. У студентов физико-математического и филологического факультета выявлялся когнитивный стиль полезависимость-поленезависимость по тесту Гольтшельта. Результаты представлены в таблице 57. Можно ли утверждать, что на физико-математическом факультете достоверно больше поленезависимых студентов, а на филологическом – полезависимых.
7.7. Детям 6-7 лет предлагалось решить задачу на классификацию с изменяющимся признаком, где классификацию можно выполнить на основании признака формы, признака количества и признака величины. При решении задачи оказалось, что дети вначале чаще выбирают признак формы. Так, из 24 обследованных детей для 1 классификации признак формы выбрали 14. Можно ли утверждать, что признак формы достоверно чаще используется детьми для классификации?





