

Динамические оперативные запоминающие устройства
Динамической памяти в вычислительной машине значительно больше, чем статической, поскольку именно DRAM используется в качестве основной памяти ВМ. Как и SRAM, динамическая память состоит из ядра (массива ЗЭ) и интерфейсной логики (буферных регистров, усилителей чтения данных, схемы регенерации и др.). Хотя количество видов DRAM уже превысило два десятка, ядро у них организовано практически одинаково. Главные различия связаны с интерфейсной логикой, причем различия эти обусловлены также и областью применения микросхем – помимо основной памяти ВМ, ИМС динамической памяти входят, например, в состав видеоадаптеров. Классификация микросхем динамической памяти показана на рис. 72.
Чтобы оценить различия между видами DRAM, предварительно остановимся на алгоритме работы с динамической памятью. Для этого воспользуемся рис. 68.
В отличие от SRAM адрес ячейки DRAM передается в микросхему за два шага — вначале адрес столбца, а затем строки, что позволяет сократить количество выводов шины адреса примерно вдвое, уменьшить размеры корпуса и разместить на материнской плате большее количество микросхем. Это, разумеется, приводит к снижению быстродействия, так как для передачи адреса нужно вдвое больше времени. Для указания, какая именно часть адреса передается в определенный момент, служат два вспомогательных сигнала RAS и CAS. При обращении к ячейке памяти на шину адреса выставляется адрес строки. После стабилизации процессов на шине подается сигнал RAS и адрес записывается во внутренний регистр микросхемы памяти. Затем на шину адреса выставляется адрес столбца и выдается сигнал CAS. В зависимости от состояния линии WE производится чтение данных из ячейки или их запись в ячейку (перед записью данные должны быть помещены на шину данных). Интервал между установкой адреса и выдачей сигнала RAS (или CAS) оговаривается техническими характеристиками микросхемы, но обычно адрес выставляется в одном такте системной шины, а управляющий сигнал — в следующем. Таким образом, для чтения или записи одной ячейки динамического ОЗУ требуется пять тактов, в которых происходит соответственно: выдача адреса строки, выдача сигнала RAS, выдача адреса столбца, выдача сигнала CAS, выполнение операции чтения/записи (в статической памяти процедура занимает лишь от двух до трех тактов).
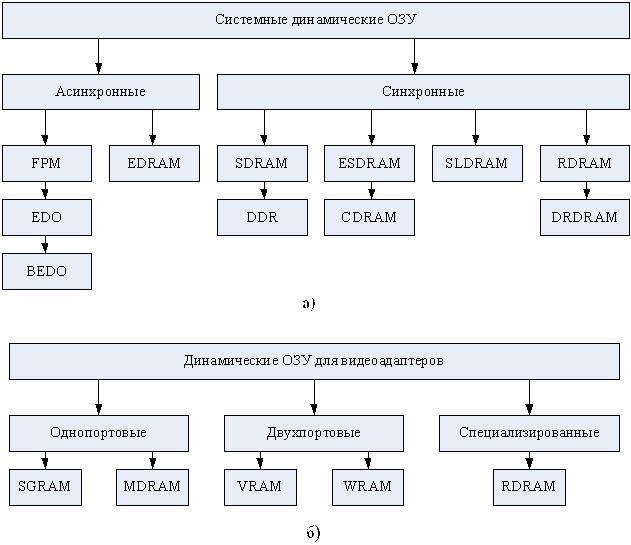
Рис. 72. Классификация динамических ОЗУ: а) – микросхемы для основной памяти; б) – микросхемы для видеоадаптеров.
Следует также помнить о необходимости регенерации данных. Но наряду с естественным разрядом конденсатора ЗЭ со временем к потере заряда приводит также считывание данных из DRAM, поэтому после каждой операции чтения данные должны быть восстановлены. Это достигается за счет повторной записи тех же данных сразу после чтения. При считывании информации из одной ячейки фактически выдаются данные сразу всей выбранной строки, но используются только те, которые находятся в интересующем столбце, а все остальные игнорируются. Таким образом, операция чтения из одной ячейки приводит к разрушению данных всей строки, и их нужно восстанавливать. Регенерация данных после чтения выполняется автоматически интерфейсной логикой микросхемы, и происходит это сразу же после считывания строки.
Теперь рассмотрим различные типы микросхем динамической памяти, начнем с системных DRAM, то есть микросхем, предназначенных для использования в качестве основной памяти. На начальном этапе это были микросхемы асинхронной памяти, работа которых не привязана жестко к тактовым импульсам системной шины.
Асинхронные динамические ОЗУ. Микросхемы асинхронных динамических ОЗУ управляются сигналами RAS и CAS, и их работа в принципе не связана непосредственно тактовыми импульсами шины. Асинхронной памяти свойственны дополнительные затраты времени на взаимодействие микросхем памяти и контроллера. Так, в асинхронной схеме сигнал RAS будет сформирован только после поступления в контроллер тактирующего импульса и будет воспринят микросхемой памяти через некоторое время. После этого память выдаст данные, но контроллер сможет их считать только по приходу следующего тактирующего импульса, так как он должен работать синхронно с остальными устройствами ВМ. Таким образом, на протяжении цикла чтения/записи происходят небольшие задержки из-за ожидания памятью контроллера и контроллером памяти.
Микросхемы DRAM. В первых микросхемах динамической памяти применялся наиболее простой способ обмена данными, часто называемый традиционным (conventional). Он позволял считывать и записывать строку памяти только на каждый пятый такт. Этапы такой процедуры были описаны ранее. Традиционной DRAM соответствует формула 5-5-5-5. Микросхемы данного типа могли работать на частотах до 40 МГц и из-за своей медлительности (время доступа составляло около 120 нс) просуществовали недолго.
Микросхемы FPMDRAM. Микросхемы динамического ОЗУ, реализующие режим FPM, также относятся к ранним типам DRAM. Сущность режима была показана ранее. Схема чтения для FPM DRAM описывается формулой 5-3-3-3 (всего 14 тактов). Применение схемы быстрого страничного доступа позволило сократить время доступа до 60 нс, что, с учетом возможности работать на более высоких частотах шины, привело к увеличению производительности памяти по сравнению с традиционной DRAM приблизительно на 70%. Данный тип микросхем применялся в персональных компьютерах примерно до 1994 года.
Микросхемы EDO DRAM. Следующим этапом в развитии динамических ОЗУ стали ИМС с гиперстраничным режимом доступа (НРМ, Hyper Page Mode), более известные как EDO (Extended Data Output — расширенное время удержания данных на выходе). Главная особенность технологии — увеличенное по сравнению с FPM DRAM время доступности данных на выходе микросхемы. В микросхемах FPM DRAM выходные данные остаются действительными только при активном сигнале CAS, из-за чего во втором и последующих доступах к строке нужно три такта: такт переключения CAS в активное состояние, такт считывания данных и такт переключения CAS в неактивное состояние. В EDO DRAM по активному (спадающему) фронту сигнала CAS данные запоминаются во внутреннем регистре, где хранятся еще некоторое время после того, как поступит следующий активный фронт сигнала. Это позволяет использовать хранимые данные, когда CAS уже переведен в неактивное состояние. Иными словами, временные параметры улучшаются за счет исключения циклов ожидания момента стабилизации данных на выходе микросхемы.
Схема чтения у EDO DRAM уже 5-2-2-2, что на 20% быстрее, чем у FPM. Время доступа составляет порядка 30-40 нс. Следует отметить, что максимальная частота системной шины для микросхем EDO DRAM не должна была превышать 66 МГц.
Микросхемы BEDO DRAM. Технология EDO была усовершенствована компанией VIA Technologies. Новая модификация EDO известна как BEDO (Burst EDO — пакетная EDO). Новизна метода в том, что при первом обращении считывается вся строка микросхемы, в которую входят последовательные слова пакета. За последовательной пересылкой слов (переключением столбцов) автоматически следит внутренний счетчик микросхемы. Это исключает необходимость выдавать адреса для всех ячеек пакета, но требует поддержки со стороны внешней логики. Способ позволяет сократить время считывания второго и последующих слов еще на один такт, благодаря чему формула приобретает вид 5-1-1-1.
Микросхемы EDRAM. Более быстрая версия DRAM была разработана подразделением фирмы Ramtron — компанией Enhanced Memory Systems. Технология реализована в вариантах FPM, EDO и BEDO. У микросхемы более быстрое ядро и внутренняя кэш-память. Наличие последней — главная особенность технологии. В роли кэш-памяти выступает статическая память (SRAM) емкостью 2048 бит. Ядро EDRAM имеет 2048 столбцов, каждый из которых соединен с внутренней кэш-памятью. При обращении к какой-либо ячейке одновременно считывается целая строка (2048 бит). Считанная строка заносится в SRAM, причем перенос информации в кэш-память практически не сказывается на быстродействии, поскольку происходит за один такт. При дальнейших обращениях к ячейкам, относящимся к той же строке, данные берутся из более быстрой кэш-памяти. Следующее обращение к ядру происходит при доступе к ячейке, не расположенной в строке, хранимой в кэш-памяти микросхемы.
Технология наиболее эффективна при последовательном чтении, то есть когда среднее время доступа для микросхемы приближается к значениям, характерным для статической памяти (порядка 10 нс). Главная сложность состоит в несовместимости с контроллерами, используемыми при работе с другими видами DRAM.
Синхронные динамические ОЗУ. В синхронных DRAM обмен информацией синхронизируется внешними тактовыми сигналами и происходит в строго определенные моменты времени, что позволяет взять все от пропускной способности шины «процессор-память» и избежать циклов ожидания. Адресная и управляющая информация фиксируются в ИМС памяти. После чего ответная реакция микросхемы произойдет через четко определенное число тактовых импульсов, и это время процессор может использовать для других действий, не связанных с обращением к памяти. В случае синхронной динамической памяти вместо продолжительности цикла доступа говорят о минимально допустимом периоде тактовой частоты, и речь уже идет о времени порядка 8-10 нс.
Микросхемы SDRAM. Аббревиатура SDRAM (Synchronous DRAM — синхронная DRAM) используется для обозначения микросхем «обычных» синхронных динамических ОЗУ. Кардинальные отличия SDRAM от рассмотренных выше асинхронных динамических ОЗУ можно свести к четырем положениям:
· синхронный метод передачи данных на шину;
· конвейерный механизм пересылки пакета;
· применение нескольких (двух или четырех) внутренних банков памяти;
· передача части функций контроллера памяти логике самой микросхемы.
Синхронность памяти позволяет контроллеру памяти «знать» моменты готовности данных, за счет чего снижаются издержки циклов ожидания и поиска данных. Так как данные появляются на выходе ИМС одновременно с тактовыми импульсами, упрощается взаимодействие памяти с другими устройствами ВМ.
В отличие от BEDO конвейер позволяет передавать данные пакета по тактам, благодаря чему ОЗУ может работать бесперебойно на более высоких частотах, чем асинхронные ОЗУ. Преимущества конвейера особенно возрастают при передаче длинных пакетов, но не превышающих длину строки микросхемы.
Значительный эффект дает разбиение всей совокупности ячеек на независимые внутренние массивы (банки). Это позволяет совмещать доступ к ячейке одного банка с подготовкой к следующей операции в остальных банках (перезарядкой управляющих цепей и восстановлением информации). Возможность держать открытыми одновременно несколько строк памяти (из разных банков) также способствует повышению быстродействия памяти. При поочередном доступе к банкам частота обращения к каждому из них в отдельности уменьшается пропорционально числу банков и SDRAM может работать на более высоких частотах. Благодаря встроенному счетчику адресов SDRAM, как и BEDO DRAM, позволяет производить чтение и запись в пакетном режиме, причем в SDRAM длина пакета варьируется и в пакетном режиме есть возможность чтения целой строки памяти. ИМС может быть охарактеризована формулой 5-1-1-1. Несмотря на то, что формула для этого типа динамической памяти такая же, что и у BEDO, способность работать на более высоких частотах приводит к тому, что SDRAM с двумя банками при тактовой частоте шины 100 МГц по производительности может почти вдвое превосходить память типа BEDO.
Микросхемы DDR SDRAM. Важным этапом в дальнейшем развитии технологии SDRAM стала DDR SDRAM (Double Data Rate SDRAM – SDRAM с удвоенной скоростью передачи данных). В отличие от SDRAM новая модификация выдает данные в пакетном режиме по обоим фронтам импульса синхронизации, за счет чего пропускная способность возрастает вдвое. Существует несколько спецификаций DDR SDRAM, в зависимости от тактовой частоты системной шины: DDR266, DDR333, DDR400, DDR533. Так, пиковая пропускная способность микросхемы памяти спецификации DDR333 составляет 2,7 Гбайт/с, а для DDR400 — 3,2 Гбайт/с. DDR SDRAM в настоящее время является наиболее распространенным типом динамической памяти персональных ВМ.
Микросхемы RDRAM, DRDRAM. Наиболее очевидные способы повышения эффективности работы процессора с памятью — увеличение тактовой частоты шины либо ширины выборки (количества одновременно пересылаемых разрядов). К сожалению, попытки совмещения обоих вариантов наталкиваются на существенные технические трудности (с повышением частоты усугубляются проблемы электромагнитной совместимости, труднее становится обеспечить одновременность поступления потребителю всех параллельно пересылаемых битов информации). В большинстве синхронных DRAM (SDRAM, DDR) применяется широкая выборка (64 бита) при ограниченной частоте шины.
Принципиально отличный подход к построению DRAM был предложен компанией Rambus в 1997 году. В нем упор сделан на повышение тактовой частоты до 400 МГц при одновременном уменьшении ширины выборки до 16 бит. Новая память известна как RDRAM (Rambus Direct RAM). Существует несколько разновидностей этой технологии: Base, Concurrent и Direct. Во всех тактирование ведется по обоим фронтам синхросигналов (как в DDR), благодаря чему результирующая частота составляет соответственно 500-600, 600-700 и 800 МГц. Два первых варианта практически идентичны, а вот изменения в технологии Direct Rambus (DRDRAM) весьма значительны.
Сначала остановимся на принципиальных моментах технологии RDRAM, ориентируясь в основном на более современный вариант — DRDRAM. Главным отличием от других типов DRAM является оригинальная система обмена данными между ядром и контроллером памяти, в основе которой лежит так называемый «канал Rambus», применяющий асинхронный блочно-ориентированный протокол. На логическом уровне информация между контроллером и памятью передается пакетами.
Различают три вида пакетов: пакеты данных, пакеты строк и пакеты столбцов. Пакеты строк и столбцов служат для передачи от контроллера памяти команд управления соответственно линиями строк и столбцов массива запоминающих элементов. Эти команды заменяют обычную систему управления микросхемой с помощью сигналов RAS, CAS, WE и CS.
Массив ЗЭ разбит на банки. Их число в кристалле емкостью 64 Мбит составляет 8 независимых или 16 сдвоенных банков. В сдвоенных банка^ пара банков использует общие усилители чтения/записи. Внутреннее ядро микросхемы имеет 128-разрядную шину данных, что позволяет по каждому адресу столбца передавать 16 байт. При записи можно использовать маску, в которой каждый бит соответствует одному байту пакета. С помощью маски можно указать, сколько байтов пакета и какие именно должны быть записаны в память.
Линии данных, строк и столбцов в канале полностью независимы, поэтому команды строк, команды столбцов и данные могут передаваться одновременно, причем для разных банков микросхемы. Пакеты столбцов включают в себя по два поля и передаются по пяти линиям. Первое поле задает основную операцию записи или чтения. Во втором поле находится либо указание на использование маски записи (собственно маска передается по линиям данных), либо расширенный код операции, определяющий вариант для основной операции. Пакеты строк подразделяются на пакеты активации, отмены, регенерации и команды переключения режимов энергопотребления. Для передачи пакетов строк выделены три линии.
Операция записи может следовать сразу за чтением — нужна лишь задержка на время прохождения сигнала по каналу (от 2,5 до 30 нс в зависимости от длины канала). Чтобы выровнять задержки в передаче отдельных битов передаваемого кода, проводники на плате должны располагаться строго параллельно, иметь одинаковую длину (длина линий не должна превышать 12 см) и отвечать строгим требованиям, определенным разработчиком.
Каждая запись в канале может быть конвейеризирована, причем время задержки первого пакета данных составляет 50 нс, а остальные операции чтения/записи осуществляются непрерывно (задержка вносится только при смене операции с записи на чтение, и наоборот).
В имеющихся публикациях упоминается работа Intel и Rambus над новой версией RDRAM, названной nDRAM, которая будет поддерживать передачу данных с частотами до 1600 МГц.
Микросхемы SLDRAM. Потенциальным конкурентом RDRAM на роль стандарта архитектуры памяти для будущих персональных ВМ выступает новый вид динамического ОЗУ, разработанный консорциумом производителей ВМ SyncLink Consortium и известный под аббревиатурой SLDRAM. В отличие от RDRAM, технология которой является собственностью компаний Rambus и Intel, данный стандарт — открытый. На системном уровне технологии очень похожи. Данные и команды от контроллера к памяти и обратно в SLDRAM передаются пакетами по 4 или 8 посылок. Команды, адрес и управляющие сигналы посылаются по однонаправленной 10-разрядной командной шине. Считываемые и записываемые данные передаются по двунаправленной 18-разрядной шине данных. Обе шины работают на одинаковой частоте. Пока что еще эта частота равна 200 МГц, что, благодаря технике DDR, эквивалентно 400 МГц. Следующие поколения SLDRAM должны работать на частотах 400 МГц и выше, то есть обеспечивать эффективную частоту более 800 МГц.
К одному контроллеру можно подключить до 8 микросхем памяти. Чтобы избежать запаздывания сигналов от микросхем, более удаленных от контроллера, временные характеристики для каждой микросхемы определяются и заносятся в ее управляющий регистр при включении питания.
Микросхемы ESDRAM. Это синхронная версия EDRAM, в которой используются те же приемы сокращения времени доступа. Операция записи в отличие от чтения происходит в обход кэш-памяти, что увеличивает производительность ESDRAM при возобновлении чтения из строки, уже находящейся в кэш-памяти. Благодаря наличию в микросхеме двух банков простои из-за подготовки к операциям чтения/записи сводятся к минимуму. Недостатки у рассматриваемой микросхемы те же, что и у EDRAM — усложнение контроллера, так как он должен .читывать возможность подготовки к чтению в кэш-память новой строки ядра. Кроме того, при произвольной последовательности адресов кэш-память задействуется неэффективно.
Микросхемы CDRAM. Данный тип ОЗУ разработан в корпорации Mitsubishi, и его можно рассматривать как пересмотренный вариант ESDRAM, свободный от некоторых ее несовершенств. Изменены емкость кэш-памяти и принцип размещения в ней данных. Емкость одного блока, помещаемого в кэш-память, уменьшена до 128 бит, таким образом, в 16-килобитовом кэше можно одновременно хранить копии из 128 участков памяти, что позволяет эффективнее использовать кэш-память. Замена первого помещенного в кэш участка памяти начинается только после заполнения последнего (128-го) блока. Изменению подверглись и средства доступа. Так, в микросхеме используются раздельные адресные шины для статического кэша и динамического ядра. Перенос данных из динамического ядра в кэш-память совмещен с выдачей данных на шину, поэтому частые, но короткие пересылки не снижают производительности ИМС при считывании из памяти больших объемов информации и уравнивают CDRAM с ESDRAM, а при чтении по выборочным адресам CDRAM явно выигрывает. Необходимо, однако, отметить, что вышеперечисленные изменения привели к еще большему усложнению контроллера памяти.
§
В ЗУ с фиксированными головками приходится по одной головке считывания/ записи на каждую дорожку. Головки смонтированы на жестком рычаге, пересекающем все дорожки диска. В дисковом ЗУ с подвижными головками имеется только одна головка, также установленная на рычаге, однако рычаг способен перемещаться в радиальном направлении над поверхностью диска, обеспечивая возможность позиционирования головки на любую дорожку.
Диски с магнитным носителем устанавливаются в дисковод, состоящий из рычага, шпинделя, вращающего диск, и электронных схем, требуемых для ввода и вывода двоичных данных. Несъемный диск зафиксирован на дисководе. Съемный диск может быть вынут из дисковода и заменен на другой аналогичный диск. Преимущество системы со съемными дисками — возможность хранения неограниченного объема данных при ограниченном числе дисковых устройств. Кроме того, такой диск может быть перенесен с одной ВМ на другую.
Большинство дисков имеет магнитное покрытие с обеих сторон. В этом случае говорят о двусторонних (double-sided) дисках. Односторонние (single-sided) диски в наше время встречаются достаточно редко.
На оси может располагаться один или несколько дисков. В последнем случае используют термин дисковый пакет.
В зависимости от применяемой головки считывания/записи можно выделить три типа дисковых ЗУ. В первом варианте головка устанавливается на фиксированной дистанции от поверхности так, чтобы между ними оставался воздушный промежуток. Второй вариант — это когда в процессе чтения и записи головка и диск находятся в физическом контакте. Такой способ используется, например, в накопителях на гибких магнитных дисках (дискетах).
Для правильной записи и считывания головка должна генерировать и воспринимать магнитное поле определенной интенсивности, поэтому чем уже головка, тем ближе должна она размещаться к поверхности диска (более узкая головка означает и более узкие дорожки, а значит, и большую емкость диска). Однако приближение головки к диску означает и больший риск ошибки за счет загрязнения и дефектов. В процессе решения этой проблемы был создан диск типа «винчестер».
В винчестерах используются круглые диски, называемые пластинами, они покрыты с обеих сторон специальным материалом, разработанным для хранения информации в виде намагниченных цепочек. Пластины крепятся на шпиндель. Они вращаются на большой скорости, приводимые от специального шпиндельного мотора. Специальные электромагнитные читающие/пишущие устройства, называемые головками, используются для записи и чтения информации с поверхности пластин (рис. 74).

Рис. 74. Внутреннее строение накопителя типа «винчестер».
Весь винчестер должен быть произведен с особой точностью в силу очень большой миниатюрности компонентов. Пластины, головки, шпиндель, соленоидный привод закрыты в специальном объеме, называемом гермозоной, или «банкой». Это сделано для того, чтобы гермозона была защищена от пыли, которая может разрушить головки или стать причиной царапин на пластинах. Внутри гермозоны находится воздух, а не вакуум, как думают многие. Она связана с внешним миром системой выравнивания давления, в которой имеется воздушный фильтр. Таким образом, давление воздуха внутри гермозоны всегда выровнено с окружающим воздухом, этим же образом решена проблема с выпадением конденсата — когда вы приносите винчестер с улицы, достаточно 2-3 часов, чтобы он нагрелся и испарился конденсат с поверхности пластин.
Приведем пример работы винчестера. Это схематичный пример, в котором мы не будем касаться таких вещей, как кэширование диска, коррекции ошибок и многих других специальных приемов, которые используются в современных жестких дисках и позволяют улучшить скорость и надежность работы.
1. Первый шаг в доступе к диску — это знание того, где искать информацию. Между запросом к данным и вычислением точного места поиска, происходит несколько преобразований:
a. преобразование адреса данных в файле в адрес на логическом диске;
b. преобразование адреса на логическом диске в адрес сектора на диске (это производится в компьютере, далее вступает работа самого винчестера).
2. Управляющая программа жесткого диска сначала проверяет наличие запрашиваемой информации у себя в кэше. Если она есть, контроллер сразу же выдает информацию, без доступа к поверхности диска.
3. В большинстве случаев, жесткий диск уже крутится, если это не так (в случае активизации процесса сохранения энергии), производится раскрутка пластин.
4. Контроллер переводит полученный адрес сектора в физический адрес на диске: номер головки, номер цилиндра, номер сектора. Это производится с помощью специальной подпрограммы контроллера жестких дисков, называемой транслятором.
5. Котроллер выдает команду соленоидной системе на перемещение головок к нужному треку.
6. Когда головки находятся над нужным треком, выбирается интересующая нас головка и производится ожидание момента, когда перед головкой должен пролететь нужный нам сектор. Затем происходит считывание сектора.
7. Контроллер считывает сектор в свой буфер, после чего он выдает эту информацию компьютеру с помощью интерфейса.
Подложечный материал, из которого изготовлена пластина, образует основу, на которой будут храниться данные. Слоем, хранящим данные, является очень тонкое покрытие магнитным материалом поверхности пластины. Толщина этого слоя — несколько миллионных дюйма.
В качестве магнитного материала в старых винчестерах использовался оксидный материал, а именно — оксид железа. Если посмотреть на пластины старых винчестеров, они будут иметь характерный светло-коричневый цвет. Тип магнитного материала, используемого в старых винчестерах, схож с материалом, используемом в аудиокассетах: они тоже используют оксид железа в качестве хранителя и переносчика звуковой информации, именно поэтому пленка в аудиокассетах тоже светло-коричневая.
Современные накопитеи используют тонкопленочное покрытие. Как видно из названия, очень тонкий слой магнитного материала прикреплен к подложке пластины. При производстве таких пластин используются специальные производственные технологии. Одна из технологий — это гальванопокрытие. Другая технология — распыление. Пластины, произведенные по технологии распыления, имеют лучшую однородность, чем пластины, произведенные с помощью гальванопокрытия. В силу возросших требований к качеству пластин в современных жестких дисках, используются пластины, произведенные по технологии напыления магнитного материала.
По сравнению с оксидным материалом, тонкопленочный материал более однороден и гладок. Он также имеет намного лучшие магнитные свойства, позволяющие хранить намного больше данных на единицу поверхности. Кроме того, этот материал намного устойчивее к физическим воздействиям. Пластины после нанесения магнитного материала покрываются тонким защитным слоем, состоящим из карбона.
Поверхностная плотность записи, иногда называемая битовой плотностью, показывает, какое количество информации может храниться на единицу поверхности пластины. Она обычно считается в битах на квадратный дюйм — BPSI — bits per square inch.
Поверхностная плотность записи — двухмерная величина, она вычисляется как продукт двух одномерных величин:
1. Трековая плотность: Она показывает, как много треков может поместиться на каждый дюйм радиуса диска. Пусть, например мы имеем пластины диаметром 3,74 дюйма, или радиусом в 1,87 дюйма. Естественно, в силу того, что пластина надевается на шпиндель, реально рабочий участок будет, например, равен 1,2 дюйма. Пусть мы имеем 22000 треков на пластину, тогда трековая плотность будет примерно равна 18333 треков на дюйм — TPI — tracks per inch.
2. Линейная плотность или плотность записи: Эта величина показывает, сколько бит информации может поместиться на одном треке. Если на треке может поместиться 300000 бит, то мы можем говорить, что линейная плотность записи составляет 300000 бит на трек — BPI — bits per inch.
Беря продукт умножения этих двух величин можно получить поверхностную плотность записи. В приведенном выше примере она будет составлять величину порядка 5,5 Гигабит на квадратный дюйм. Современные жесткие диски имеют плотности порядка сотен гигабит на квадратный дюйм, в то же время первые жесткие диски для ПК имели плотности, порядка 0,004 Гигабит на квадратный дюйм.
Линейная плотность записи диска не постоянна для всей поверхности пластины. Причиной, по которой эта величина не постоянна, служит увеличение длины трека от центра к краям пластины. Таким образом, внешние треки хранят большее количество информации, чем внутренние. С изобретением зонной записи, винчестеры начали хранить больше информации на внешних треках, чем на внутренних, но, тем не менее, линейная плотность записи у внутренних треков больше, чем у внешних.
Существует два пути для увеличения поверхностной плотности записи:
· увеличение линейной плотности записи, увеличивая при этом количество информации хранимой на треке;
· увеличение трековой плотности, увеличивая при этом количество треков на пластину.
Обычно, в более новом поколении винчестеров улучшаются обе эти величины. Как следствие их улучшения, повышаются и такие параметры винчестера, как скорость линейного чтения/записи, а также и скорость позиционирования.
§
Одной из целей концепции RAID была возможность обнаружения и коррекции ошибок, возникающих при отказах дисков или в результате сбоев. Достигается это за счет избыточного дискового пространства, которое задействуется для хранения дополнительной информации, позволяющей восстановить искаженные или утерянные данные. В RAID предусмотрены три вида такой информации:
· дублирование
· код Хэмминга;
· биты паритета.
Первый из вариантов заключается в дублировании всех данных, при условии, что экземпляры одних и тех же данных расположены на разных дисках массива. Это позволяет при отказе одного из дисков воспользоваться соответствующей информацией, хранящейся на исправных МД. В принципе распределение информации по дискам массива может быть произвольным, но для сокращения издержек, связанных с поиском копии, обычно применяется разбиение массива на пары МД, где в каждой паре дисков информация идентична и одинаково расположена. При таком дублировании для управления парой дисков может использоваться общий или раздельные контроллеры. Избыточность дискового массива здесь составляет 100%.
Второй способ формирования корректирующей информации основан на вычислении кода Хэмминга для каждой группы полос, одинаково расположенных на всех дисках массива (пояса). Корректирующие биты хранятся на специально выделенных для этой цели дополнительных дисках (по одному диску на каждый бит). Так, для массива из десяти МД требуются четыре таких дополнительных диска, и избыточность в данном случае близка к 30%.
В третьем случае вместо кода Хэмминга для каждого набора полос, расположенных в идентичной позиции на всех дисках массива, вычисляется контрольная полоса, состоящая из битов паритета. В ней значение отдельного бита формируется как сумма по модулю два для одноименных битов во всех контролируемых полосах. Для хранения полос паритета требуется только один дополнительный диск. В случае отказа какого-либо из дисков массива производится обращение к диску паритета, и данные восстанавливаются по битам паритета и данным от остальных дисков массива. Реконструкция данных достаточно проста. Рассмотрим массив из пяти дисковых ЗУ, где диски Х0–Х3 содержат данные, а Х4 – это диск паритета. Паритет для i-го бита вычисляется как
 .
.
Предположим, что дисковод Х1 отказал. Если мы добавим  , к обеим частям предыдущего выражения, то получим:
, к обеим частям предыдущего выражения, то получим:
 .
.
Таким образом, содержимое каждой полосы данных на любом диске массива может быть восстановлено по содержимому соответствующих полос на остальных дисках массива. Избыточность при таком способе в среднем близка к 20%.
RAID уровня 0
RAID уровня 0, строго говоря, не является полноценным членом семейства RAID, поскольку данная схема не содержит избыточности и нацелена только на повышение производительности в ущерб надежности.
В основе RAID 0 лежит расслоение данных. Полосы распределены по всем дискам массива дисковых ЗУ по циклической схеме (рис. 75). Преимущество такого распределения в том, что если требуется записать или прочитать логически последовательные полосы, то несколько таких полос (вплоть до n) могут обрабатываться параллельно, за счет чего существенно снижается общее время ввода/вывода. Ширина полос в RAID 0 варьируется в зависимости от применения, но в любом случае она не менее размера физического сектора МД.

Рис. 75. RAID уровня 0.
RAID 0 обеспечивает наиболее эффективное использование дискового пространства и максимальную производительность дисковой подсистемы при минимальных затратах и простоте реализации. Недостатком является незащищенность данных — отказ одного из дисков ведет к разрушению целостности данных во всем массиве. Тем не менее, существует ряд приложений, где производительность и емкость дисковой системы намного важнее возможного снижения надежности. К таким можно отнести задачи, оперирующие большими файлами данных, в основном в режиме считывания информации (библиотеки изображений, большие таблицы и т. п.), и где загрузка информации в основную память должна производиться как можно быстрее. Учитывая отсутствие в RAID 0 средств по защите данных, желательно хранить дубликаты файлов на другом, более надежном носителе информации, например на магнитной ленте.
RAID уровня 1
В RAID 1 избыточность достигается с помощью дублирования данных. В принципе исходные данные и их копии могут размещаться по дисковому массиву произвольно, главное чтобы они находились на разных дисках. В плане быстродействия и простоты реализации выгоднее, когда данные и копии располагаются идентично на одинаковых дисках. Рисунок 76 показывает, что, как и в RAID 0, здесь имеет место разбиение данных на полосы. Однако в этом случае каждая логическая полоса отображается на два отдельных физических диска, так что каждый диск в массиве имеет так называемый «зеркальный» диск, содержащий идентичные данные. Для управления каждой парой дисков может быть использован общий контроллер, тогда данные сначала записываются на основной диск, а затем — на «зеркальный» («зеркалирование»). Более эффективно применение самостоятельных контроллеров для каждого диска, что позволяет производить одновременную запись на оба диска.

Рис. 76. RAID уровня 1.
Запрос на чтение может быть обслужен тем из двух дисков, которому в данный момент требуется меньшее время поиска и меньшая задержка вращения. Запрос на запись требует, чтобы были обновлены обе соответствующие полосы, но это выполнимо и параллельно, причем задержка определяется тем диском, которому нужны большие время поиска и задержка вращения. В то же время у RAID 1 нет дополнительных затрат времени на вычисление вспомогательной корректирующей информации. Когда одно дисковое ЗУ отказывает, данные могут быть просто взяты со второго.
Принципиальный изъян RAID 1 — высокая стоимость: требуется вдвое больше физического дискового пространства. По этой причине использование RAID 1 обычно ограничивают хранением загрузочных разделов, системного программного обеспечения и данных, а также других особенно критичных файлов: RAID 1 обеспечивает резервное копирование всех данных, так что в случае отказа диска критическая информация доступна практически немедленно.
RAID уровня 2
В системах RAID 2 используется техника параллельного доступа, где в выполнении каждого запроса на В/ВЫВ одновременно участвуют все диски. Обычно шпиндели всех дисков синхронизированы так, что головки каждого ЗУ в каждый момент времени находятся в одинаковых позициях. Данные разбиваются на полосы длиной в 1 бит и распределены по дискам массива таким образом, что полное машинное слово представляется поясом, то есть число дисков равно длине машинного слова в битах. Для каждого слова вычисляется корректирующий код (обычно это код Хэмминга, способный корректировать одиночные и обнаруживать двойные ошибки), который, также побитово, хранится на дополнительных дисках (рис. 77). Например, для массива, ориентированного на 32-разрядные слова (32 основных диска) требуется семь дополнительных дисковых ЗУ (корректирующий код состоит из 7 разрядов).
При записи вычисляется корректирующий код, который заносится на отведенные для него диски. При каждом чтении производится доступ ко всем дискам массива, включая дополнительные. Считанные данные вместе с корректирующим кодом подаются на контроллер дискового массива, где происходит повторное вычисление корректирующего кода и его сравнение с хранившимся на избыточных дисках. Если присутствует одиночная ошибка, контроллер способен ее мгновенно распознать и исправить, так что время считывания не увеличивается.
RAID 2 позволяет достичь высокой скорости В/ВЫВ при работе с большими последовательными записями, но становится неэффективным при обслуживании записей небольшой длины. Основное преимущество RAID 2 состоит в высокой степени защиты информации, однако предлагаемый в этой схеме метод коррекции уже встроен в каждое из современных дисковых ЗУ.
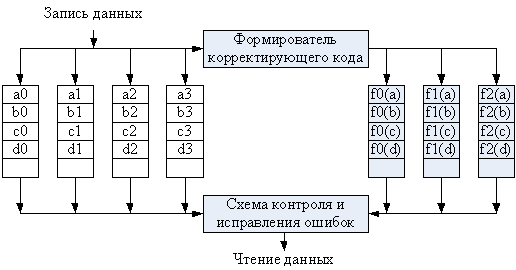
Рис. 77. RAID уровня 2.
Корректирующие разряды вычисляются для каждого сектора диска и хранятся в соответствующем поле этих секторов. В таких условиях использование нескольких избыточных дисков представляется неэффективным, и массивы уровня RAID 2 в настоящее время не выпускаются.
RAID уровня 3
RAID 3 организован сходно с RAID2. Отличие в том, что RAID 3 требует только одного дополнительного диска — диска паритета, вне зависимости от того, насколько велик массив дисков (рис. 78). В RAID 3 используется параллельный доступ к данным, разбитым на полосы длиной в бит или байт. Все диски массива синхронизированы. Вместо кода Хэмминга для набора полос идентичной позиции на всех дисках массива (пояса) вычисляется полоса, состоящая из битов паритета. В случае отказа дискового ЗУ производится обращение к диску паритета, и данные восстанавливаются по битам паритета и данным от остальных дисков массива.

Рис. 78. RAID уровня 3.
Так как данные разбиты на очень маленькие полосы, RAID 3 позволяет достигать очень высоких скоростей передачи данных. Каждый запрос на ввод/вывод приводит к параллельной передаче данных со всех дисков. Для приложений, связанных с большими пересылками данных, это обстоятельство очень существенно. С другой стороны, параллельное обслуживание одиночных запросов невозможно, и производительность дисковой подсистемы в этом случае падает.
Ввиду того что для хранения избыточной информации нужен всего один диск, причем независимо от их числа в массиве, именно уровню RAID 3 отдается предпочтение перед RAID 2.
RAID уровня 4
По своей идее и технике формирования избыточной информации RAID 4 идентичен RAID 3, только размер полос в RAID 4 значительно больше (обычно один-два физических блока на диске). Главное отличие состоит в том, что в RAID 4 используется техника независимого доступа, когда каждое ЗУ массива в состоянии функционировать независимо, так, что отдельные запросы на ввод/вывод могут удовлетворяться параллельно (рис. 79).
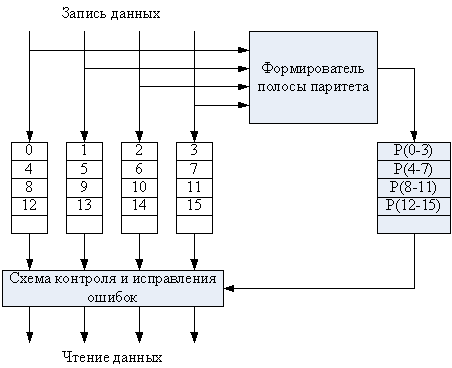
Рис. 79. RAID уровня 4.
Для RAID 4 характерны издержки, обусловленные независимостью дисков. Если в RAID 3 запись производилась одновременно для всех полос одного пояса, в RAID 4 осуществляется запись полос в разные пояса. Это различие ощущается особенно при записи данных малого размера.
Каждый раз для выполнения записи программное обеспечение дискового массива должно обновить не только данные пользователя, но и соответствующие биты паритета. Рассмотрим массив из пяти дисковых ЗУ, где ЗУ X0 … ХЗ содержат данные, а Х4 — диск паритета. Положим, что производится запись, охватывающая только полосу на диске Х1. Первоначально для каждого бита iмы имеем следующее соотношение:
 .
.
После обновления для потенциально измененных битов, обозначаемых с помощью апострофа, получаем:
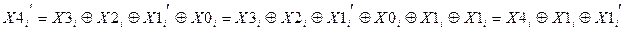 .
.
Для вычисления новой полосы паритета программное обеспечение управления массивом должно прочитать старую полосу пользователя и старую полосу паритета. Затем оно может заменить эти две полосы новой полосой данных и новой вычисленной полосой паритета. Таким образом, запись каждой полосы связана с двумя операциями чтения и двумя операциями записи.
В случае записи большого объема информации, охватывающего полосы на всех дисках, паритет вычисляется достаточно легко путем расчета, в котором участвуют только новые биты данных, то есть содержимое диска Паритета может быть обновлено параллельно с дисками данных и не требует дополнительных операций чтения и записи.
Массивы RAID 4 наиболее подходят для приложений, требующих поддержки высокого темпа поступления запросов ввода/вывода, и уступает RAID 3 там, где приоритетен большой объем пересылок данных.
RAID уровня 5
RAID 5 имеет структуру, напоминающую RAID 4. Различие заключается в том, что RAID 5 не содержит отдельного диска для хранения полос паритета, а разносит их по всем дискам. Типичное распределение осуществляется по циклической схеме, как это показано на рис. 80. В n-дисковом массиве полоса паритета вычисляется для полос п-1 дисков, расположенных в одном поясе, и хранится в том же поясе, но на диске, который не учитывался при вычислении паритета. При переходе от одного пояса к другому эта схема циклически повторяется.

Рис. 80. RAID уровня 5.
Распределение полос паритета по всем дискам предотвращает возникновение проблемы, упоминавшейся для RAID 4.
RAID уровня 6
RAID 6 очень похож на RAID 5. Данные также разбиваются на полосы размером в блок и распределяются по всем дискам массива. Аналогично, полосы паритета распределены по разным дискам. Доступ к полосам независимый и асинхронный. Различие состоит в том, что на каждом диске хранится не одна, а две полосы паритета. Первая из них, как и в RAID 5, содержит контрольную информацию для полос, расположенных на горизонтальном срезе массива (за исключением диска, где эта полоса паритета хранится). В дополнение формируется и записывается вторая полоса паритета, контролирующая все полосы какого-то одного диска массива (вертикальный срез массива), но только не того, где хранится полоса паритета. Сказанное иллюстрируется рис. 81.
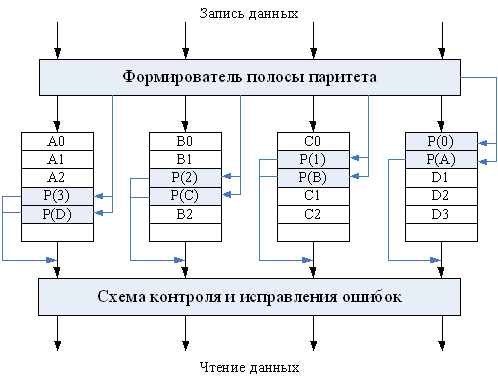
Рис. 81. RAID уровня 6.
Такая схема массива позволяет восстановить информацию при отказе сразу двух дисков. С другой стороны, увеличивается время на вычисление и запись паритетной информации и требуется дополнительное дисковое пространство. Кроме того, реализация данной схемы связана с усложнением контроллера дискового массива. В силу этих причин, схема среди выпускаемых RAID-систем встречается крайне редко.
RAID уровня 7
Схема RAID 7, запатентованная Storage Computer Corporation, объединяет массив асинхронно работающих дисков и кэш-память, управляемые встроенной в кон троллер массива операционной системой реального времени (рис. 82). Данные разбиты на полосы размером в блок и распределены по дискам массива. Полосы паритета хранятся на специально выделенных для этой цели одном или нескольких дисках.
Схема некритична к виду решаемых задач и при работе с большими файлами не уступает по производительности RAID 3. Вместе с тем RAID 7 может так же эффективно, как и RAID 5, производить одновременно несколько операций чтения и записи для небольших объемов данных. Все это обеспечивается использованием кэш-памяти и собственной операционной системой.

Рис. 82. RAID уровня 7.
RAID уровня 10
Данная схема совпадает с RAID 0, но в отличие от нее роль отдельных дисков выполняют дисковые массивы, построенные по схеме RAID 1 (рис. 83).
Таким образом, в RAID 10 сочетаются расслоение и дублирование. Это позволяет добиться высокой производительности, характерной для RAID 0 при уровне отказоустойчивости RAID 1. Основной недостаток схемы — высокая стоимость ее реализации. Кроме того, необходимость синхронизации всех дисков приводит к усложнению контроллера.

Рис. 83. RAID уровня 10.
RAID уровня 53
В этом уровне сочетаются технологии RAID 0 и RAID 3, поэтому его правильнее было бы назвать RAID 30. В целом данная схема соответствует RAID 0, где роль отдельных дисков выполняют дисковые массивы, организованные по схеме RAID 3. Естественно, что в RAID 53 сочетаются все достоинства RAID 0 и RAID 3. Недостатки схемы такие же, что и у RAID 10.
§
Массивы RAID могут быть реализованы программно, аппаратно или как комбинация программных и аппаратных средств.
При программной реализации используются обычные дисковые контроллеры и стандартные команды ввода/вывода. Работа дисковых ЗУ в соответствии с алгоритмами различных уровней RAID обеспечивается программами операционной системы ВМ. Программный режим RAID предусмотрен, например, в операционных системах на основе ядра Windows NT. Это дает возможность программного изменения уровня RAID, в зависимости от особенностей решаемой задачи. Хотя программный способ является наиболее дешевым, он не позволяет добиться высокого уровня производительности, характерного для аппаратурной реализации RAID.
Аппаратурная реализация RAID предполагает возложение всех или большей части функций по управлению массивом дисковых ЗУ на соответствующее оборудование, при этом возможны два подхода. Первый из них заключается в замене стандартных контроллеров дисковых ЗУ на специализированные, устанавливаемые на место стандартных. Базовая ВМ общается с контроллерами на уровне обычных команд ввода/вывода, а режим RAID обеспечивают контроллеры. Как и обычные, специализированные контроллеры/адаптеры ориентированы на определенный вид шины. Поскольку наиболее распространенной шиной для подключения дисковых ЗУ в настоящее время является шина SCSI, большинство производителей RAID-систем ориентируют свои изделия на протокол SCSI, определяемый стандартами ANSI Х3.131 и ISO/IEC. При втором способе аппаратной реализации RAID-система выполняется как автономное устройство, объединяющее в одном корпусе массив дисков и контроллер. Контроллер содержит микропроцессор и работает под управлением собственной операционной системы, полностью реализующей различные RAID-режимы. Такая подсистема подключается к шине базовой ВМ или к ее каналу ввода/вывода как обычное дисковое ЗУ.
При аппаратной реализации RAID-систем обычно предусматривается возможность замены неисправных дисков без потери информации и без остановки работы. Кроме того, многие из таких систем позволяют разбивать отдельные диски на разделы, причем разные разделы дисков могут объединяться в соответствии с различными уровнями RAID.
Оптическая память
В 1983 году была представлена первая цифровая аудиосистема на базе компакт-дисков (CD — compact disk). Компакт-диск — это односторонний диск, способный хранить более чем 60-минутную аудиоинформацию. Громадный коммерческий успех CD способствовал развитию технологии дешевых оптических запоминающих устройств для ВМ. За последующие годы были созданы различные системы памяти на оптических дисках, три из которых в прогрессирующей степени приживаются в вычислительных машинах: CD-ROM, WARM и стираемые оптические диски.
Для аудио компакт-дисков и CD-ROM используется идентичная технология. Основное отличие состоит в том, что проигрыватели CD-ROM более прочные и содержат устройства для исправления ошибок, обеспечивающие корректность передачи данных с диска в ВМ. Диск изготавливается из пластмассы, например поликарбоната, и покрыт окрашенным слоем с высокой отражающей способностью, обычно алюминием. Цифровая информация заносится в виде микроскопических углублений в отражающей поверхности. Запись информации производится с помощью сильно сфокусированного луча лазера высокой интенсивности. Так создается так называемый, мастер-диск, с которого затем печатаются копии. Углубления на копии защищаются от пыли и повреждений путем покрытия поверхности диска прозрачным лаком.
Информация с диска считывается маломощным лазером, расположенным в проигрывателе. Лазер освещает поверхность вращающегося диска сквозь прозрачное покрытие. Интенсивность отраженного луча лазера меняется, когда он попадает в углубление на диске. Эти изменения фиксируются фотодетектором и преобразуются в цифровой сигнал.
Углубления, расположенные ближе к центру диска, перемещаются относительно луча лазера медленнее, чем более удаленные. Из-за этого необходимы меры для компенсации различий в скорости так, чтобы лазер мог считывать информацию с постоянной скоростью.
Одно из возможных решений аналогично применяемому в магнитных дисках — увеличение расстояния между битами информации, в зависимости от ее расположения на диске. В этом случае диск может вращаться с неизменной скоростью и, соответственно, такие дисковые ЗУ известны как устройства с постоянной угловой скоростью (CAV, Constant Angular Velocity). Ввиду нерационального использования внешней части диска метод постоянной угловой скорости в CD-ROM не поддерживается. Вместо этого информация по диску размещается в секторах одинакового размера, которые сканируются с постоянной скоростью за счет того, что диск вращается с переменной скоростью. В результате углубления считываются лазером с постоянной линейной скоростью (CLV, Constant Linear Velocity). При доступе к информации у внешнего края диска скорость вращения меньше и возрастает при приближении к оси. Емкость дорожки и задержки вращения возрастают по мере смещения от центра к внешнему краю диска.
Выпускаются CD различной емкости. В типовом варианте расстояние между дорожками составляет 1,6 мк, что, с учетом промежутков между дорожками, позволяет обеспечить 20 344 дорожки. Фактически же, вместо множества концентрических дорожек, имеется одна дорожка в виде спирали, длина которой равна 5,27 км. Постоянная линейная скорость CD-ROM — 1,2 м/с, то есть для «прохождения» спирали требуется 4391 с или 73,2 мин. Именно эта величина составляет стандартное максимальное время проигрывания аудиодиска. Так как данные считываются с диска со скоростью 176,4 Кбайт/с, емкость CD равна 774,57 Мбайт.
Данные на CD-ROM организованы как последовательность блоков. Типичный формат блока показан на рис. 84. Блок включает в себя следующие поля:
· Синхронизация.Это поле идентифицирует начало блока и состоит из нулевого байта, десяти байтов, содержащих только единичные разряды, и вновь байта из всех нулей.
· Идентификатор.Заголовок, содержащий адрес блока и байт режима. Режим 0 определяет пустое поле данных; режим 1 отвечает за использование кода, корректирующего ошибки, и наличие 2048 байт данных; режим 2 определяет наличие 2336 байт данных и отсутствие корректирующего кода.
· Данные.Данные пользователя.
· Корректирующий код (КК).Поле предназначено для хранения дополнительных данных пользователя в режиме 2, а в режиме 1 содержит 288 байт кода с исправлением ошибок.
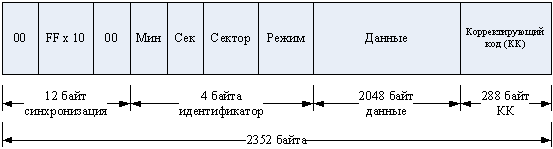
Рис. 84. Формат блока CD-ROM.
Рисунок 85 иллюстрирует организацию информации на CD-ROM. Как уже отмечалось, данные расположены последовательно по спиралевидной дорожке. Для варианта с постоянной линейной скоростью произвольный доступ к информации становится более сложным.
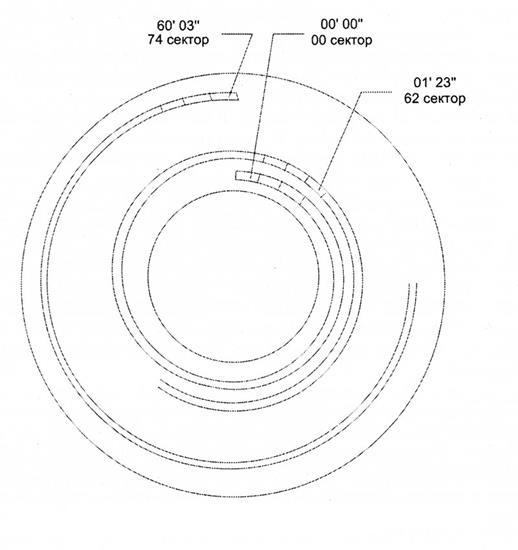
Рис. 85. Организация диска с постоянной линейной скоростью.
В последнее время наметился переход к новому типу оптических дисков, так называемым DVD-дискам (Digital Video Data). DVD-диски состоят из двух слоев толщиной 0,6 мм, то есть имеют две рабочих поверхности, и обеспечивают хранение по 4,7 Гбайт на каждой. В DVD-технологии используется лазер с меньшей длиной волны (650 нм против 780 нм для стандартных CD-ROM), а также более изощренная схема коррекции. Все это позволяет увеличить число дорожек и повысить плотность записи. Кроме того, при записи применяется метод сжатия информации, известный как MPEG2.
Контрольные вопросы
1. Перечислите основные компоненты HDD.
2. Какие две цели достигаются с помощью организации HDD в RAID?
3. Оцените утилизацию дискового пространства для RAID 1 и 5.
4. Какие преимущества имеются у составных RAID-массивов?
5. За счёт чего достигается повышенная отказоустойчивость RAID?
6. От чего зависит количество секторов на дорожке?
7. Каким способом можно увеличить плотность записи на пластину HDD?
8. На чём основан принцип считывания информации с CD?
9. Почему в CD используется только метод считывания с постоянной линейной скоростью?
10. За счёт чего увеличена ёмкость DVD по сравнению с CD?
§
В основе архитектуры большинства современных ВМ лежит представление алгоритма решения задачи в виде программы последовательных вычислений. Базовые архитектурные идеи ВМ, ориентированной на последовательное исполнение команд программы, были сформулированы Джоном фон Нейманом. В условиях постоянно возрастающих требований к производительности вычислительной техники все очевидней становятся ограничения классической фон-неймановской архитектуры, обусловленные исчерпанием всех основных идей ускорения последовательного счета. Дальнейшее развитие вычислительной техники связано с переходом к параллельным вычислениям как в рамках одной ВМ, так и путем создания многопроцессорных систем и сетей, объединяющих большое количество отдельных процессоров или отдельных вычислительных машин. Для такого подхода вместо термина «вычислительная машина» более подходит термин «вычислительная система» (ВС). Отличительной особенностью вычислительных систем является наличие в них средств, реализующих параллельную обработку, за счет построения параллельных ветвей в вычислениях, что не предусматривалось классической структурой ВМ. Идея параллелизма как средства увеличения быстродействия ЭВМ возникла очень давно — еще в XIX веке.
Уровни параллелизма
Методы и средства реализации параллелизма зависят от того, на каком уровне он должен обеспечиваться. Обычно различают следующие уровни параллелизма:
· Уровень заданий. Несколько независимых заданий одновременно выполняются на разных процессорах, практически не взаимодействуя друг с другом. Этот уровень реализуется на ВС с множеством процессоров в многозадачном режиме.
· Уровень программ. Части одной задачи выполняются на множестве процессоров. Данный уровень достигается на параллельных ВС.
· Уровень команд. Выполнение команды разделяется на фазы, а фазы нескольких последовательных команд могут быть перекрыты за счет конвейеризации. Уровень достижим на ВС с одним процессором.
· Уровень битов (арифметический уровень). Биты слова обрабатываются один за другим, это называется бит-последовательной операцией. Если биты слова обрабатываются одновременно, говорят о бит-параллельной операции. Данный уровень реализуется в обычных и суперскалярных процессорах.
К понятию уровня параллелизма тесно примыкает понятие гранулярности. Это мера отношения объема вычислений, выполненных в параллельной задаче, к объему коммуникаций (для обмена сообщениями). Степень гранулярности варьируется от мелкозернистой до крупнозернистой. Определим понятия крупнозернистого (coarse grained), среднезернистого (medium grained) и мелкозернистого (fine grained) параллелизма.
Крупнозернистый параллелизм:, каждое параллельное вычисление достаточно независимо от остальных, причем требуется относительно редкий обмен информацией между отдельными вычислениями. Единицами распараллеливания являются большие и независимые программы, включающие тысячи команд. Этот уровень параллелизма обеспечивается операционной системой.
Среднезернистый параллелизм: единицами распараллеливания являются вызываемые процедуры, включающие в себя сотни команд. Обычно организуется как программистом, так и компилятором.
Мелкозернистый параллелизм: каждое параллельное вычисление достаточно мало и элементарно, составляется из десятков команд. Обычно распараллеливаемыми единицами являются элементы выражения или отдельные итерации цикла, имеющие небольшие зависимости по данным. Сам термин «мелкозернистый параллелизм» говорит о простоте и быстроте любого вычислительного действия. Характерная особенность мелкозернистого параллелизма заключается в приблизительном равенстве интенсивности вычислений и обмена данными. Этот уровень параллелизма часто используется распараллеливающим (векторизирующим) компилятором.
Эффективное параллельное исполнение требует искусного баланса между степенью гранулярности программ и величиной коммуникационной задержки, возникающей между разными гранулами. В частности, если коммуникационная задержка минимальна, то наилучшую производительность обещает мелкоструктурное разбиение программы. Это тот случай, когда действует параллелизм данных. Если коммуникационная задержка велика (как в слабосвязанных системах), предпочтительней крупнозернистое разбиение программ.
9.1.1. Параллелизм уровня задания
Параллелизм уровня задания возможен между независимыми заданиями или их фазами. Основным средством реализации параллелизма на уровне заданий служат многопроцессорные и многомашинные вычислительные системы, в которых задания распределяются по отдельным процессорам или машинам. Однако, если трактовать каждое задание как совокупность независимых задач, реализация данного уровня возможна и в рамках однопроцессорной В С. В этом случае несколько заданий могут одновременно находиться в основной памяти ВС, при условии, что в каждый момент выполняется только одно из них. Когда выполняемое задание требует ввода/вывода, такая операция запускается, а до ее завершения остальные ресурсы ВС передаются другому заданию. По завершении ввода/вывода ресурсы ВС возвращаются заданию, инициировавшему эту операцию. Здесь параллелизм обеспечивается за счет того, что центральный процессор и система ввода/вывода работают одновременно, обслуживая разные задания.
В качестве примера рассмотрим вычислительную систему с четырьмя процессорами. ВС обрабатывает задания, классифицируемые как малое (S), среднее (М) и большое (L). Для выполнения малых заданий требуется один, средних — два, а больших заданий — четыре процессора. Обработка каждого задания занимает одну условную единицу времени. Первоначально существует такая очередь заданий: S M L S S M L L S M M(таблица 6).
| Таблица 6 | ||
| Время | Выполняемые задания | % использования ВС |
| S, M | ||
| L | ||
| S, S, М | ||
| L | ||
| L | ||
| S, М | ||
| М |
При этом средний уровень использования ресурсов вычислительной системы равен 83,3%; на выполнение всех заданий требуется 7 единиц времени.
Для получения большей степени утилизации ресурсов ВС разрешим заданиям «выплывать» в начало очереди. Тогда можно получить следующую последовательность выполнения заданий: S M S L S M S L L M M(таблица 7).
| Таблица 7 | ||
| Время | Выполняемые задания | % использования ВС |
| S, M, S | ||
| L | ||
| S, М, S | ||
| L | ||
| L | ||
| М, М |
При этом средний процент использования ресурсов ВС составляет 100%; на выполнение всех заданий требуется 6 единиц времени.
Параллелизм возникает также, когда у независимых заданий, выполняемых в ВС, имеются несколько фаз, например вычисление, запись в графический буфер, В/ВЫВ на диск или ленту, системные вызовы.
Пусть выполняется задание и оно для своего продолжения нуждается в выполнении ввода/вывода. По сравнению с вычислениями он обычно более длителен, поэтому текущее задание приостанавливается и запускается другое задание. Исходное задание активизируется после завершения ввода/вывода. Все это требует специального оборудования: каналов В/ВЫВ или специальных процессоров В/ ВЫВ. За то, как различные задания упорядочиваются и расходуют общие ресурсы, отвечает операционная система.
Параллелизм уровня программ
О параллелизме на уровне программы имеет смысл говорить в двух случаях. Во-первых, когда в программе могут быть выделены независимые участки, которые допустимо выполнять параллельно. Примером такого вида параллелизма может служить программа робота. Пусть имеется робот, запрограммированный на обнаружение электрических розеток, когда уровень напряжения в его аккумуляторах падает. Когда робот находит одну из розеток, он включается в нее на подзарядку. В процесс вовлечены три подсистемы робота: зрение, манипуляция и движение. Каждая подсистема управляется своим процессором, то есть подсистемы при выполнении разных действий способны работать параллельно (таблица 8).
| Таблица 8 | |||
| Задача | Зрение | Манипуляция | Движение |
| Поиск розетки | X | X | |
| Движение к розетке | X | X | |
| Подключение к розетке | X | X |
Подсистемы достаточно независимы при ведущей роли системы зрения. Возможен также и центральный процессор — «мозг». Это пример параллелизма программ, в котором разные задачи выполняются единовременно для достижения общей цели.
Второй тип параллелизма программ возможен в пределах отдельного программного цикла, если в нем отдельные итерации не зависят друг от друга. Программный параллелизм может быть реализован за счет большого количества процессоров или множества функциональных блоков. В качестве примера рассмотрим следующий фрагмент кода:
For I:=l to N do A(I):=B(I) C(I)
Все суммы независимы, то есть вычисление Вi Сi не зависит от Bj Cj для любого j < i. Это означает, что вычисления могут производиться в любой последовательности и в вычислительной системе с N процессорами все суммы могут быть вычислены одновременно.
Общая форма параллелизма на уровне программ проистекает из разбиения программируемых данных на подмножества. Это разделение называют декомпозицией области (domain decomposition), а параллелизм, возникающий при этом, носит название параллелизма данных. Подмножества данных назначаются разным вычислительным процессам, и называется этот процесс распределением данных (data distribution). Процессоры выделяются определенным процессам либо по инициативе программы, либо в процессе работы операционной системой. На каждом процессоре может выполняться более чем один процесс.
Параллелизм уровня команд
Параллелизм на уровне команд имеет место, когда обработка нескольких команд или выполнение различных этапов одной и той же команды может перекрываться во времени. Разработчики вычислительной техники издавна прибегали к методам, известным под общим названием «совмещения операций», при котором аппаратура ВМ в любой момент времени выполняет одновременно более одной операции. Этот общий принцип включает в себя два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, термины эти отражают два принципиально различных подхода.
В первом варианте совмещение операций достигается за счет того, что в составе вычислительной системы отдельные устройства присутствуют в нескольких копиях. Так, в состав процессора может входить несколько АЛУ, и высокая производительность обеспечивается за счет одновременной работы всех этих АЛУ. Второй подход был описан ранее.
§
Рассмотрим параллельное выполнение программы со следующими характеристиками:
· О(п) — общее число операций (команд), выполненных на п-процессорной системе;
· Т(п) — время выполнения O(п) операций на «-процессорной системе в виде числа квантов времени.
В общем случае Т(п) < O(п), если в единицу времени п процессорами выполняется более чем одна команда, где п > 2. Примем, что в однопроцессорной системе T(1) = O(1).
Ускорение (speedup), или точнее, среднее ускорение за счет параллельного выполнения программы — это отношение времени, требуемого для выполнения наилучшего из последовательных алгоритмов на одном процессоре, и времени параллельного вычисления на п процессорах. Без учета коммуникационных издержек ускорение S(n) определяется как
 .
.
Как правило, ускорение удовлетворяет условию S(n) < п.
Эффективность (efficiency) n-процессорной системы — это ускорение на один процессор, определяемое выражением
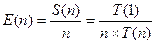 .
.
Эффективность обычно отвечает условию 1/п ≤ Е(п) ≤ п. Для более реалистичного описания производительности параллельных вычислений необходимо промоделировать ситуацию, когда параллельный алгоритм может потребовать больше операций, чем его последовательный аналог.
Довольно часто организация вычислений на п процессорах связана с существенными издержками. Поэтому имеет смысл ввести понятие избыточности (redundancy) в виде
 .
.
Это отношение отражает степень соответствия между программным и аппаратным параллелизмом. Очевидно, что 1 < R(n) < п.
Определим еще одно понятие, коэффициент полезного использования или утилизации (utilization), как
 .
.
Тогда можно утверждать, что
 и
и 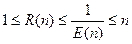 .
.
Рассмотрим пример. Пусть наилучший из известных последовательных алгоритмов занимает 8с, а параллельный алгоритм занимает на пяти процессорах 2с. Тогда:
· S(n) = 8/2 = 4;
· E(n) = 4/5 = 0,8;
· R(n) = 1/0,8 – 1 = 0,25.
Собственное ускорение определяется путем реализации параллельного алгоритма на одном процессоре.
Если ускорение, достигнутое на п процессорах, равно п, то говорят, что алгоритм показывает линейное ускорение.
В исключительных ситуациях ускорение S(n) может быть больше, чем п. В этих случаях иногда применяют термин суперлинейное ускорение. Данное явление имеет шансы на возникновение в двух следующих случаях:
Последовательная программа может выполняться в очень маленькой памяти, вызывая свопинги (подкачки), или, что менее очевидно, может приводить к большему числу кэш-промахов, чем параллельная версия, где обычно каждая параллельная часть кода выполняется с использованием много меньшего набора данных.
Другая причина повышенного ускорения иллюстрируется примером. Пусть нам нужно выполнить логическую операцию А1 v А2, где как А1, так и А2имеют значение «Истина» с вероятностью 50%, причем среднее время вычисления Аi, обозначенное как T(Аi), существенно различается в зависимости от того, является ли результат истинным или ложным.
Пусть T(Аi)= 1c для Аi = 1; T(Аi)= 100c для Аi = 0. Теперь получаем четыре равновероятных случая (Т — «истина», F — «ложь», таблица 9).
| Таблица 9 | |||
| А1 | А2 | Последовательный | Параллельный |
| Т Т F F | Т F Т F | 1с 0 1с 0 100 с 1с 100 с 100 с | 1 с 1с 1с 100с |
| ∑ | 303/4с ≈ 76с | 103/4с ≈ 26с |
Таким образом, параллельные вычисления на двух процессорах ведут к среднему ускорению:
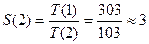 .
.
Отметим, что суперлинейное ускорение вызвано жесткостью последовательной обработки, так как после вычисления еще нужно проверить A2. К факторам, ограничивающим ускорение, следует отнести:
· Программные издержки. Даже если последовательные и параллельные алгоритмы выполняют одни и те же вычисления, параллельным алгоритмам присущи добавочные программные издержки — дополнительные индексные вычисления, неизбежно возникающие из-за декомпозиции данных и распределения их по процессорам; различные виды учетных операций, требуемые в параллельных алгоритмах, но отсутствующие в алгоритмах последовательных.
· Издержки из-за дисбаланса загрузки процессоров. Между точками синхронизации каждый из процессоров должен быть загружен одинаковым объемом работы, иначе часть процессоров будет ожидать, пока остальные завершат свои операции. Эта ситуация известна как дисбаланс загрузки. Таким образом, ускорение ограничивается наиболее медленным из процессоров.
· Коммуникационные издержки. Если принять, что обмен информацией и вычисления могут перекрываться, то любые коммуникации между процессорами снижают ускорение. В плане коммуникационных затрат важен уровень гранулярности, определяющий объем вычислительной работы, выполняемой между коммуникационными фазами алгоритма. Для уменьшения коммуникационных издержек выгоднее, чтобы вычислительные гранулы были достаточно крупными и доля коммуникаций была меньше.
Еще одним показателем параллельных вычислений служит качество параллельного выполнения программ — характеристика, объединяющая ускорение, эффективность и избыточность. Качество определяется следующим образом:
 .
.
Поскольку как эффективность, так и величина, обратная избыточности, представляют собой дроби, то Q(n) < S(n). Поскольку Е(п) — это всегда дробь, a R(n) — число между 1 и п, качество Q(n) при любых условиях ограничено сверху величиной ускорения S(n).
Закон Амдала
Приобретая для решения своей задачи параллельную вычислительную систему, пользователь рассчитывает на значительное повышение скорости вычислений за счет распределения вычислительной нагрузки по множеству параллельно работающих процессоров. В идеальном случае система из п процессоров могла бы ускорить вычисления в п раз. В реальности достичь такого показателя по ряду причин не удается. Главная из этих причин заключается в невозможности полного распараллеливания ни одной из задач. Как правило, в каждой программе имеется фрагмент кода, который принципиально должен выполняться последовательно и только одним из процессоров. Это может быть часть программы, отвечающая за запуск задачи и распределение распараллеленного кода по процессорам, либо фрагмент программы, обеспечивающий операции ввода/вывода. Можно привести и другие примеры, но главное состоит в том, что о полном распараллеливании задачи говорить не приходится. Известные проблемы возникают и с той частью задачи, которая поддается распараллеливанию. Здесь идеальным был бы вариант, когда параллельные ветви программы постоянно загружали бы все процессоры системы, причем так, чтобы нагрузка на каждый процессор была одинакова. К сожалению, оба этих условия на практике трудно реализуемы. Таким образом, ориентируясь на параллельную ВС, необходимо четко сознавать, что добиться прямо пропорционального числу процессоров увеличения производительности не удастся, и, естественно, встает вопрос о том, на какое реальное ускорение можно рассчитывать. Ответ на этот вопрос в какой-то мере дает закон Амдала.
Джин Амдал (Gene Amdahl) — один из разработчиков всемирно известной системы IBM 360, в своей работе, опубликованной в 1967 году, предложил формулу, отражающую зависимость ускорения вычислений, достигаемого на многопроцессорной ВС, от числа процессоров и соотношения между последовательной и параллельной частями программы. Показателем сокращения времени вычислений служит такая метрика, как «ускорение».
Напомним, что ускорение S — это отношение времени Ts, затрачиваемого на проведение вычислений на однопроцессорной ВС (в варианте наилучшего последовательного алгоритма), ко времени Тр решения той же задачи на параллельной системе (при использовании наилучшего параллельного алгоритма):
 .
.
Оговорки относительно алгоритмов решения задачи сделаны, чтобы подчеркнуть тот факт, что для последовательного и параллельного решения лучшими могут оказаться разные реализации, а при оценке ускорения необходимо исходить именно из наилучших алгоритмов.
Проблема рассматривалась Амдалом в следующей постановке (рис. 87). Прежде всего, объем решаемой задачи с изменением числа процессоров, участвующих в ее решении, остается неизменным. Программный код решаемой задачи состоит из двух частей: последовательной и распараллеливаемой. Обозначим долю операций, которые должны выполняться последовательно одним из процессоров, через f, где 0 ≤ f ≤ 1 (здесь доля понимается не по числу строк кода, а по числу реально выполняемых операций). Отсюда доля, приходящаяся на распараллеливаемую часть программы, составит 1 – f. Крайние случаи в значениях/соответствуют полностью параллельным (f= 0) и полностью последовательным (f = 1) программам. Распараллеливаемая часть программы равномерно распределяется по всем процессорам.

Рис. 87. К постановке задачи в законе Амдала.
С учетом приведенной формулировки имеем:
 .
.
В результате получаем формулу Амдала, выражающую ускорение, которое может быть достигнуто на системе из n процессоров:
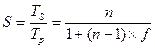 .
.
Формула выражает простую и обладающую большой общностью зависимость. Если устремить число процессоров к бесконечности, то в пределе получаем:
 .
.
Это означает, что если в программе 10% последовательных операций (то есть f=0,1), то, сколько бы процессоров ни использовалось, убыстрения работы программы более чем в десять раз никак ни получить, да и то, 10 — это теоретическая верхняя оценка самого лучшего случая, когда никаких других отрицательных факторов нет. Следует отметить, что распараллеливание ведет к определенным издержкам, которых нет при последовательном выполнении программы. В качестве примера таких издержек можно упомянуть дополнительные операции, связанные с распределением программ по процессорам, обмен информацией между процессорами и т. д.
Закон Густафсона
Известную долю оптимизма в оценку, даваемую законом Амдала, вносят исследования, проведенные уже упоминавшимся Джоном Густафсоном из NASA Ames Research. Решая на вычислительной системе из 1024 процессоров три больших задачи, для которых доля последовательного кода лежала в пределах от 0,4 до 0,8%, он получил значения ускорения по сравнению с однопроцессорным вариантом, равные соответственно 1021,1020 и 1016. Согласно закону Амдала для данного числа процессоров и диапазона f, ускорение не должно было превысить вели чины порядка 201. Пытаясь объяснить это явление, Густафсон пришел к выводу, что причина кроется в исходной предпосылке, лежащей в основе закона Амдала: увеличение числа процессоров не сопровождается увеличением объема решаемой задачи. Реальное же поведение пользователей существенно отличается от такого представления. Обычно, получая в свое распоряжение более мощную систему, пользователь не стремится сократить время вычислений, а, сохраняя его практически неизменным, старается пропорционально мощности ВС увеличить объем решаемой задачи. И тут оказывается, что наращивание общего объема программы касается главным образом распараллеливаемой части программы. Это ведет к сокращению значения f. Примером может служить решение дифференциального уравнения в частных производных. Если доля последовательного кода составляет 10% для 1000 узловых точек, то для 100 000 точек доля последовательного кода снизится до 0,1%. Сказанное иллюстрирует рис. 88, который отражает тот факт, что, оставаясь практически неизменной, последовательная часть в общем объеме увеличенной программы имеет уже меньший удельный вес.

Рис. 88. К постановке задачи в законе Густафсона.
Было отмечено, что в первом приближении объем работы, которая может быть произведена параллельно, возрастает линейно с ростом числа процессоров в системе. Для того чтобы оценить возможность ускорения вычислений, когда объем последних увеличивается с ростом количества процессоров в системе (при постоянстве общего времени вычислений), Густафсон рекомендует использовать выражение, предложенное Е. Барсисом (Е. Barsis):
 .
.
Данное выражение известно как закон масштабируемого ускорения или закон Густафсона (иногда его называют также законом Густафсона-Барсиса). В заключение отметим, что закон Густафсона не противоречит закону Амдала. Различие состоит лишь в форме утилизации дополнительной мощности ВС, возникающей при увеличении числа процессоров.
§
Даже краткое перечисление типов современных параллельных вычислительных систем (ВС) дает понять, что для ориентирования в этом многообразии необходима четкая система классификации. От ответа на главный вопрос — что заложить в основу классификации — зависит, насколько конкретная система классификации помогает разобраться с тем, что представляет собой архитектура ВС и насколько успешно данная архитектура позволяет решать определенный круг задач. Попытки систематизировать все множество архитектур параллельных вычислительных систем предпринимались достаточно давно и длятся по сей день, но к однозначным выводам пока не привели.
Среди всех рассматриваемых систем классификации ВС наибольшее признание получила классификация, предложенная в 1966 году М. Флинном [99, 100]. В ее основу положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. В зависимости от количества потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD, MIMD.
SISD
SISD(Single Instruction Stream/Single Data Stream) — одиночный поток команд и одиночный поток данных (рис. 89, а). Представителями этого класса являются, прежде всего, классические фон-неймановские ВМ, где имеется только один поток команд, команды обрабатываются последовательно и каждая команда инициирует одну операцию с одним потоком данных. То, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка, не имеет значения, поэтому в класс SISD одновременно попадают как ВМ CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными. Некоторые специалисты считают, что к SISD-системам можно причислить и векторно-конвейерные ВС, если рассматривать вектор как неделимый элемент данных для соответствующей команды.
MISD
MISD(Multiple Instruction Stream/Single Data Stream) — множественный поток команд и одиночный поток данных (рис. 89, б). Из определения следует, что в архитектуре ВС присутствует множество процессоров, обрабатывающих один и тот же поток данных. Примером могла бы служить ВС, на процессоры которой подается искаженный сигнал, а каждый из процессоров обрабатывает этот сигнал с помощью своего алгоритма фильтрации. Тем не менее ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не сумели представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей относят к данному классу конвейерные системы, однако это не нашло окончательного признания. Отсюда принято считать, что пока данный класс пуст. Наличие пустого класса не следует считать недостатком классификации Флинна. Такие классы, по мнению некоторых исследователей, могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
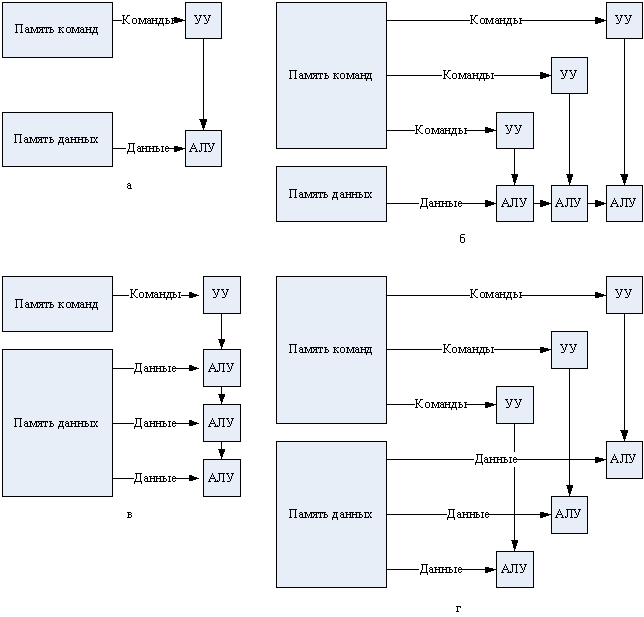
Рис. 89. Архитектура вычислительных систем по Флинну: а – SISD; б –MISD; в – SIMD; г – MIMD.
SIMD
SIMD (Single Instruction Stream/Multiple Data Stream) — одиночный поток команд и множественный поток данных (рис. 89, в). ВМ данной архитектуры позволяют выполнять одну арифметическую операцию сразу над многими данными — элементами вектора. Бесспорными представителями класса SIMD считаются матрицы процессоров, где единое управляющее устройство контролирует множество процессорных элементов. Все процессорные элементы получают от устройства управления одинаковую команду и выполняют ее над своими локальными данными. В принципе в этот класс можно включить и векторно-конвейерные ВС, если каждый элемент вектора рассматривать как отдельный элемент потока данных.
MIMD
MIMD (Multiple Instruction Stream/Multiple Data Stream) – множественный поток команд и множественный поток данных (рис. 89, г). Класс предполагает наличие в вычислительной системе множества устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы. Кроме того, приобщение к классу MIMD зависит от трактовки. Так, ранее упоминавшиеся векторно-конвейерные ВС можно вполне отнести и к классу MIMD, если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) над множественным скалярным потоком.
Схема классификации Флинна вплоть до настоящего времени является наиболее распространенной при первоначальной оценке той или иной ВС, поскольку позволяет сразу оценить базовый принцип работы системы, чего часто бывает достаточно. Однако у классификации Флинна имеются и очевидные недостатки, например неспособность однозначно отнести некоторые архитектуры к тому или иному классу. Другая слабость — это чрезмерная насыщенность класса MIMD. Все это породило множественные попытки либо модифицировать классификацию Флинна, либо предложить иную систему классификации.
Контрольные вопросы
1. Сравните схемы классификации параллелизма по уровню и гранулярности.
Каковы, на ваш взгляд, достоинства, недостатки и области применения этих
схем классификации?
2. Для заданной программы и конфигурации параллельной вычислительной системы рассчитайте значения метрик параллельных вычислений.
3. Поясните суть закона Амдала, приведите примеры, поясняющие его ограничения.
4. Какую проблему закона Амдала решает закон Густафсона? Как он это делает? Сформулируйте области применения этих двух законов.
5. Укажите достоинства и недостатки схемы классификации Флинна.
§
Многопроцессорные системы по классификации Флинна относятся к архитектурам типа MIMD(Multiple Instruction Multipl Data) с множественным потоком команд при множественном потоке данных (МКМД). В многопроцессорной системе каждый процессор выполняет свою программу достаточно независимо от других процессоров. Процессоры в ходе решения общей задачи должны связываться друг с другом в соответствии с графом взаимодействия её параллельных ветвей. Это вызывает необходимость более подробно производить классификацию систем типа MIMD.
В многопроцессорных системах с общей памятью (сильносвязанных) имеется память данных и команд, доступная всем процессорам. С общей памятью процессоры связываются с помощью коммуникационной среды, основой которой может быть либо общая шина (ОШ), либо множество шин (МШ), либо перекрёстный коммутатор (ПК).
В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с распределённой памятью) вся память разделена между процессорами и каждый блок памяти доступен только локальному процессору. Память и процессор образуют фактически независимые вычислительные модули (вычислительные узлы), которые связываются между собой при помощи высокоскоростной сети обмена с коммутацией сообщений.
Сообщение – это блок информации, сформированный процессом-отправителем таким образом, чтобы он был понятен процессу-получателю. Сообщение состоит из заголовка фиксированной длины и набора данных определённого типа обычно переменной длины. В заголовок, как правило, включают следующую информацию:
• адрес – это поле, предназначенное для идентификации процессоров (вычислительных узлов), участвующих в процедуре обмена. Адрес процессора или вычислительного узла является уникальным и состоит из двух частей – адреса процессора – отправителя и адреса процессора – получателя;
• управляющие поля, в которые могут входить символы синхронизации, отмечающие начало и конец передаваемого блока (кадра) данных, символы, обозначающие тип данных, длину передаваемых данных и др.
В качестве топологической модели коммуникационной среды применяют линейные или кольцевые моноканалы, звездообразную конфигурацию, плоскую решётку, n- мерный тор, либо n- кубическую (гиперкубическую) сеть.
Базовой моделью вычислений на MIMD-системах является совокупность независимых процессов, время от времени обращающихся к разделяемым данным. Основана она на распределенных вычислениях, в которых программа делится на довольно большое число параллельных задач.
В настоящее время всё большее внимание разработчики проявляют к архитектурам типа MIMD. Это находит объяснение главным образом существованием двух факторов:
1) в архитектурах MIMD используются высокотехнологичные, дешёвые, выпускаемые массово микропроцессоры, что позволяет оптимизировать соотношение стоимость/производительность;
2) архитектура MIMD дает большую гибкость и при наличии соответствующей поддержки со стороны аппаратных средств и программного обеспечения, поскольку может работать и как однопрограммная система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, и как многопрограммная, выполняющая множество задач параллельно, а также как некоторая комбинация этих возможностей.
Одной из отличительных особенностей многопроцессорной вычислительной системы является коммуникационная среда, с помощью которой процессоры соединяются друг с другом или с памятью. Топология коммуникационной среды настолько важна для многопроцессорной системы, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, которые в общем случае зависят от алгоритмов решаемых задач и порождаемых ими вычислительных процессов.
Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая – на использовании общей памяти.
В многопроцессорных системах с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом “почтового ящика”.
В архитектурах с распределённой памятью непосредственное разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, каналов обмена и пропускной способности памяти.
Такие системы часто называют системами с передачей сообщений. Каждый из этих механизмов обмена имеет свои преимущества. Для обмена в общей памяти это включает:
• совместимость с хорошо понятными и используемыми в однопроцессорных системах механизмами взаимодействия процессора с основной памятью;
• простота программирования, особенно это заметно в тех случаях, когда процедуры обмена между процессорами сложные или динамически меняются во время выполнения. Подобные преимущества упрощают конструирование компилятора;
• более низкая задержка обмена и лучшее использование полосы пропускания при обмене малыми порциями данных;
• возможность использования аппаратно управляемого кэширования для снижения частоты удаленного обмена, допускающая кэширование всех данных как разделяемых, так и неразделяемых.
Основные преимущества обмена с помощью передачи сообщений являются:
• аппаратура может быть более простой, особенно по сравнению с моделью разделяемой памяти, которая поддерживает масштабируемую когерентность кэш-памяти;
• процедуры обмена понятны, принуждают программистов (или компиляторы) уделять внимание обмену, который обычно имеет высокую, связанную с ним, стоимость.
Часто, в системах с общей памятью затраты времени на обмен не учитываются, так как проблемы обмена в значительной степени скрыты от программиста. Однако накладные расходы на обмен в этих системах имеются и определяются в основном конфликтами при доступе процессоров и других устройств к общим шинам и блокам основной памяти. Чем больше процессоров добавляется в систему, тем больше процессов соперничают при использовании одних и тех же данных и шины, что может привести к значительным задержкам хода вычислительного процесса и, следовательно, к потерям общей производительности. Причём с увеличением числа процессоров в системе возможно появление эффекта насыщения при котором рост числа процессоров не приведёт к росту производительности, и даже наоборот к её падению.
Модель системы с общей памятью очень удобна для прогаммирования, поскольку пользователь практически не задумывается о процедурах распараллеливания (они большей частью ложатся на компилятор) и процедурах взаимодействия параллельных процессов (они производятся аппаратными средствами посредством общей памяти).
В сетях с коммутацией сообщений по мере возрастания требований к обмену следует учитывать возможность перегрузки сети. Здесь межпроцессорный обмен связывает сетевые ресурсы: каналы, процессоры, буферы сообщений. Объем передаваемой информации может быть сокращен за счет тщательного разбиения задачи на параллельные ветви и тщательной диспетчеризации процесса их исполнения.
Таким образом, существующие MIMD-системы распадаются на два основных класса в зависимости от количества объединяемых процессоров, которое определяет способ организации памяти и методику их межсоединений.
К первому классу относятся системы с разделяемой (общей) основной памятью (Shared Memory multiProcessing, SMP), объединяющие до нескольких (2-16) процессоров, число которых зависит от типа применяемой коммуникационной среды. Сравнительно небольшое количество процессоров в таких системах позволяет иметь одну централизованную общую память и зачастую объединить процессоры и память с помощью лишь одной шины. При наличии у процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров.
Поскольку имеется единственная память с одним и тем же временем доступа, эти системы называют симметричными, а иногда – UMA (Uniform Memory Access). Симметричная архитектура предполагает однородность процессоров и единообразную схему их включения в многопроцессорную систему. Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным.
Структура подобной системы представлена на рис. 90.
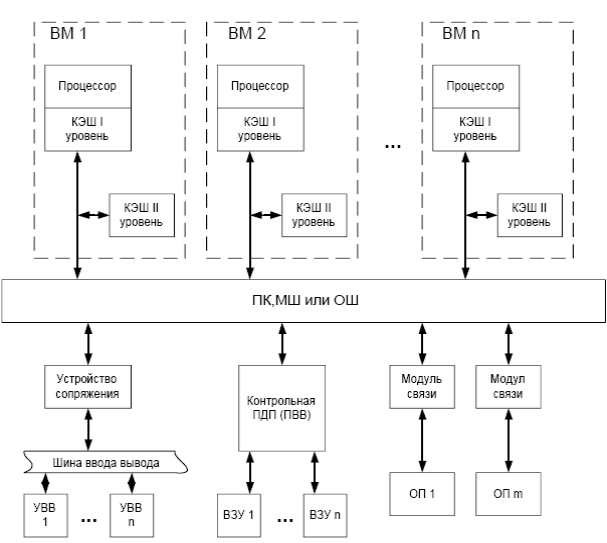
Рис. 90. Архитектура многопроцессорной системы с разделяемой (общей) памятью.
Второй класс составляют крупномасштабные вычислительные системы с распределенной памятью. Подобные ВС получили название систем с массовым параллелизмом (Mass-Parallel Processing, MPP). Для того чтобы подключать в систему большое количество процессоров необходимо физически разделять основную память и распределять её между ними. В противном случае пропускной способности памяти просто может не хватить для удовлетворения запросов, поступающих от очень большого числа процессоров. Естественно при таком подходе также требуется реализовать связь процессоров между собой. На рис. 91 показана структура такой системы.
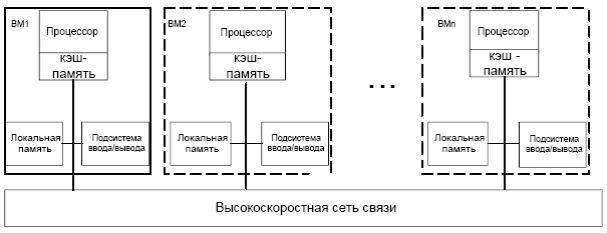
Рис. 91. Архитектура многопроцессорной системы с распределенной памятью.
Адресное пространство в таких системах состоит из отдельных адресных пространств, которые логически не связаны, и доступ к которым не может быть осуществлен аппаратно другим процессором. Фактически каждый модуль процессор-память представляет собой отдельный компьютер, поэтому такая структура в какой-то степени приближена к многопроцессорным системам.
MPP система менее эффективна с точки зрения пользователя из-за усложнённой процедуры программирования, которая связана с применением специальных коммуникационных библиотек для организации взаимодействия между вычислительными узлами (процессами). Необходимость же реализации модели распределенной памяти объясняется тем, что масштабируемость (способность системы к наращиванию числа процессоров) систем с общей памятью ограничена пропускной способностью памяти и коммуникационной среды.
Вообще распределение памяти между отдельными узлами системы имеет два главных преимущества. Во-первых, это эффективный с точки зрения стоимости способ увеличения пропускной способности памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во- вторых уменьшается задержка обращения к локальной памяти из-за отсутствия конфликтов при доступе к ней. Поэтому совершенно естественно появление промежуточного класса систем, объединяющего достоинства первого и второго классов. Память в таких системах распределена по вычислительным узлам и одновременно является доступной для всех процессоров. Такие ВС называются системами с распределенной разделяемой (общей) памятью (DSM – Distributed Shared Memory), а иногда NUMA ( Non-Uniform Memory Access), поскольку время доступа зависит от расположения данных в подсистеме памяти (Рис. 92). Если данные находятся в локальной памяти местного вычислительного узла, то время доступа к ним минимально, если в локальной памяти удалённого вычислительного узла, то время доступа
увеличивается в несколько раз.
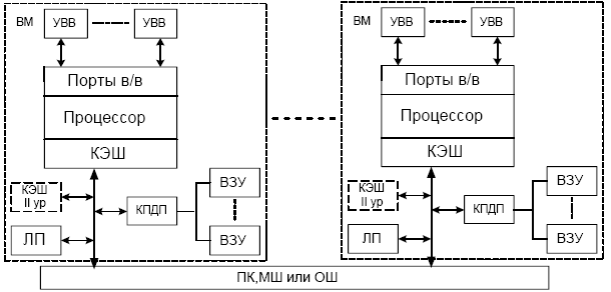
Рис. 92. Архитектура многопроцессорной системы с распределённой разделяемой памятью.
Хотя структурно DSM и MPP-системы сходны, однако технически они реализуются по-разному. В DSM-системах физически отдельные, распределённые по вычислительным узлам, устройства памяти могут представляться логически как единое адресное пространство, что означает, что любой процессор может выполнять обращения к любым ячейкам памяти, предполагая, что он имеет соответствующие права доступа.
Коммуникационная же среда и вовсе другая, так как она полностью соответствует структурам SMP-систем. Поскольку, в связи с принципами локальности, вычислительный процесс в основном развивается внутри вычислительного узла и редко обращается к удалённой памяти, что резко снижает объём передаваемых данных по коммуникационной среде, то масштабируемость таких систем повышается по сравнению с SMP-системами, и число процессоров может достигать 32-х.
Что касается устройств ввода/вывода и внешних запоминающих устройств, то они также как и память, либо распределяются по узлам, либо находятся в общем пользовании.
§
Требования, предъявляемые современными процессорами к полосе пропускания памяти можно существенно сократить путем применения больших многоуровневых кэшей. Тогда, если эти требования снижаются, то несколько процессоров смогут разделять доступ к одной и той же памяти. Начиная с 1980 года эта идея, подкрепленная широким распространением микропроцессоров, стимулировала многих разработчиков на создание небольших мультипроцессоров, в которых несколько процессоров разделяют одну физическую память, соединенную с ними с помощью разделяемой шины. Из-за малого размера процессоров и заметного сокращения требуемой полосы пропускания шины, достигнутого за счет возможности реализации достаточно большой кэш-памяти, такие машины стали исключительно эффективными по стоимости.
В первых разработках подобного рода машин удавалось разместить весь
процессор и кэш на одной плате, которая затем вставлялась в заднюю панель, с помощью которой реализовывалась шинная архитектура.
Современные конструкции позволяют разместить до четырех процессоров на одной плате. В такой машине кэши могут содержать как разделяемые, так и частные данные. Частные данные – это данные, которые используются одним процессором, в то время как разделяемые данные используются многими процессорами, по существу обеспечивая обмен между ними.
Когда кэшируется элемент частных данных, их значение переносится в кэш для сокращения среднего времени доступа, а также требуемой полосы пропускания. Поскольку никакой другой процессор не использует эти данные, этот процесс идентичен процессу для однопроцессорной машины с кэш-памятью. Если кэшируются разделяемые данные, то разделяемое значение реплицируется и может содержаться в нескольких кэшах. Кроме сокращения задержки доступа и требуемой полосы пропускания такая репликация данных способствует также общему сокращению количества обменов. Однако кэширование разделяемых данных вызывает новую проблему: когерентность кэш-памяти.
Проблема, о которой идет речь, возникает из-за того, что значение элемента данных в памяти, хранящееся в двух разных процессорах, доступно этим процессорам только через их индивидуальные кэши. На рис. 96 показан простой пример, иллюстрирующий эту проблему.
Проблема когерентности памяти для мультипроцессоров и устройств ввода/вывода имеет много аспектов. Обычно в малых мультипроцессорах используется аппаратный механизм, называемый протоколом, позволяющий решить эту проблему. Такие протоколы называются протоколами когерентности кэш-памяти. Существуют два класса таких протоколов:
1. Протоколы на основе справочника (directory based). Информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы).
2. Протоколы наблюдения (snooping). Каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии. Централизованная система записей отсутствует. Обычно КЭШи расположены на общей (разделяемой) шине и контроллеры всех КЭШей наблюдают за шиной (просматривают ее) для определения того, не содержат ли они копию соответствующего блока.

Рис. 96. Иллюстрация проблемы когерентности кэш-памяти. а) Когерентное состояние кэша и основной памяти. б) Предполагается использование кэш-памяти с обратной записью, когда ЦП записывает значение 320 в ячейку X. В результате X’ содержит новое значение, а в основной памяти осталось старое значение 88. При попытке вывода X из памяти будет получено старое значение. в) Внешняя память вводит в ячейку памяти Y новое значение 260, а в кэш-памяти осталось старое значение Y.
В мультипроцессорных системах, использующих процессоры с кэш-памятью, подсоединенные к централизованной общей памяти, протоколы наблюдения приобрели популярность, поскольку для опроса состояния кэшей они могут использовать заранее существующее физическое соединение – шину памяти.
Неформально, проблема когерентности памяти состоит в необходимости гарантировать, что любое считывание элемента данных возвращает последнее по времени записанное в него значение. Это определение не совсем корректно, поскольку невозможно требовать, чтобы операция считывания мгновенно видела значение, записанное в этот элемент данных некоторым другим процессором. Если, например, операция записи на одном процессоре предшествует операции чтения той же ячейки на другом процессоре в пределах очень короткого интервала времени, то невозможно гарантировать, что чтение вернет записанное значение данных, поскольку в этот момент времени записываемые данные могут даже не покинуть процессор. Вопрос о том, когда точно записываемое значение должно быть доступно процессору, выполняющему чтение, определяется выбранной моделью согласованного (непротиворечивого) состояния памяти и связан с реализацией синхронизации параллельных вычислений. Поэтому с целью упрощения предположим, что мы требуем только, чтобы записанное операцией записи значение было доступно операции чтения, возникшей немного позже записи и что операции записи данного процессора всегда видны в порядке их выполнения.
С этим простым определением согласованного состояния памяти мы можем гарантировать когерентность путем обеспечения двух свойств:
1. Операция чтения ячейки памяти одним процессором, которая следует за операцией записи в ту же ячейку памяти другим процессором получит записанное значение, если операции чтения и записи достаточно отделены друг от друга по времени.
2. Операции записи в одну и ту же ячейку памяти выполняются строго последовательно (иногда говорят, что они сериализованы): это означает, что две подряд идущие операции записи в одну и ту же ячейку памяти будут наблюдаться другими процессорами именно в том порядке, в котором они появляются в программе процессора, выполняющего эти операции записи.
Первое свойство очевидно связано с определением когерентного (согласованного) состояния памяти: если бы процессор всегда бы считывал только старое значение данных, мы сказали бы, что память некогерентна.
Необходимость строго последовательного выполнения операций записи является более тонким, но также очень важным свойством.
Представим себе, что строго последовательное выполнение операций записи не соблюдается. Тогда процессор P1 может записать данные в ячейку, а затем в эту ячейку выполнит запись процессор P2. Строго последовательное выполнение операций записи гарантирует два важных следствия для этой последовательности операций записи. Во-первых, оно гарантирует, что каждый процессор в машине в некоторый момент времени будет наблюдать запись, выполняемую процессором P2. Если последовательность операций записи не соблюдается, то может возникнуть ситуация, когда какой-нибудь процессор будет наблюдать сначала операцию записи процессора P2, а затем операцию записи процессора P1, и будет хранить это записанное P1 значение неограниченно долго. Более тонкая проблема возникает с поддержанием разумной модели порядка выполнения программ и когерентности памяти для пользователя: представьте, что третий процессор постоянно читает ту же самую ячейку памяти, в которую записывают процессоры P1 и P2; он должен наблюдать сначала значение, записанное P1, а затем значение, записанное P2.
Возможно он никогда не сможет увидеть значения, записанного P1, поскольку запись от P2 возникла раньше чтения. Если он даже видит значение, записанное P1, он должен видеть значение, записанное P2, при последующем чтении. Подобным образом любой другой процессор, который может наблюдать за значениями, записываемыми как P1, так и P2, должен наблюдать идентичное поведение. Простейший способ добиться таких свойств заключается в строгом соблюдении порядка операций записи, чтобы все записи в одну и ту же ячейку могли наблюдаться в том же самом порядке. Это свойство называется последовательным выполнением (сериализацией) операций записи (write serialization). Вопрос о том, когда процессор должен увидеть значение, записанное другим процессором достаточно сложен и имеет заметное воздействие на производительность, особенно в больших машинах.
Имеются две методики поддержания описанной выше когерентности. Один из методов заключается в том, чтобы гарантировать, что процессор должен получить исключительные права доступа к элементу данных перед выполнением записи в этот элемент данных. Этот тип протоколов называется протоколом записи с аннулированием (write ivalidate protocol), поскольку при выполнении записи он аннулирует другие копии. Это наиболее часто используемый протокол как в схемах на основе справочников, так и в схемах
наблюдения. Исключительное право доступа гарантирует, что во время выполнения записи не существует никаких других копий элемента данных, в которые можно писать или из которых можно читать: все другие кэшированные копии элемента данных аннулированы. Чтобы увидеть, как такой протокол обеспечивает когерентность, рассмотрим операцию записи, вслед за которой следует операция чтения другим процессором.
Поскольку запись требует исключительного права доступа, любая копия, поддерживаемая читающим процессором должна быть аннулирована (в соответствии с названием протокола). Таким образом, когда возникает операция чтения, произойдет промах кэш-памяти, который вынуждает выполнить выборку новой копии данных. Для выполнения операции записи мы можем потребовать, чтобы процессор имел достоверную (valid) копию данных в своей кэш-памяти прежде, чем выполнять в нее запись.
Таким образом, если оба процессора попытаются записать в один и тот же элемент данных одновременно, один из них выиграет состязание у второго и вызывает аннулирование его копии. Другой процессор для завершения своей
операции записи должен сначала получить новую копию данных, которая теперь уже должна содержать обновленное значение.
Альтернативой протоколу записи с аннулированием является обновление всех копий элемента данных в случае записи в этот элемент данных. Этот тип протокола называется протоколом записи с обновлением (write update protocol) или протоколом записи с трансляцией (write broadcast protocol). Обычно в этом протоколе для снижения требований к полосе пропускания полезно отслеживать, является ли слово в кэш-памяти разделяемым объектом, или нет, а именно, содержится ли оно в других кэшах. Если нет, то нет никакой необходимости обновлять другой кэш или транслировать в него обновленные данные.
Разница в производительности между протоколами записи с обновлением и с аннулированием определяется тремя характеристиками: 1. Несколько последовательных операций записи в одно и то же слово, не перемежающихся операциями чтения, требуют нескольких операций трансляции при использовании протокола записи с обновлением, но только одной начальной операции аннулирования при использовании протокола записи с аннулированием. 2. При наличии многословных блоков в кэш-памяти каждое
слово, записываемое в блок кэша, требует трансляции при использовании протокола записи с обновлением, в то время как только первая запись в любое слово блока нуждается в генерации операции аннулирования при использовании протокола записи с аннулированием. Протокол записи с аннулированием работает на уровне блоков кэш-памяти, в то время как протокол записи с обновлением должен работать на уровне отдельных слов (или байтов, если выполняется запись байта). 3. Задержка между записью слова в одном процессоре и чтением записанного значения другим процессором обычно меньше при использовании схемы записи с обновлением, поскольку записанные данные немедленно транслируются в процессор, выполняющий чтение (предполагается, что этот процессор имеет копию данных). Для сравнения, при использовании протокола записи с аннулированием в процессоре, выполняющим чтение, сначала произойдет аннулирование его копии, затем будет производиться чтение данных и его приостановка до тех пор, пока обновленная копия блока не станет доступной и не вернется в процессор.
Эти две схемы во многом похожи на схемы работы кэш-памяти со сквозной записью и с записью с обратным копированием. Также как и схема задержанной записи с обратным копированием требует меньшей полосы пропускания памяти, так как она использует преимущества операций над целым блоком, протокол записи с аннулированием обычно требует менее тяжелого трафика, чем протокол записи с обновлением, поскольку несколько записей в один и тот же блок кэш-памяти не требуют трансляции каждой записи. При сквозной записи память обновляется почти мгновенно после записи (возможно с некоторой задержкой в буфере записи). Подобным образом при использовании протокола записи с обновлением другие копии обновляются так быстро, насколько это возможно. Наиболее важное отличие в производительности протоколов записи с аннулированием и с обновлением связано с характеристиками прикладных программ и с выбором размера блока.
Основы реализации. Ключевым моментом реализации в многопроцессорных системах с небольшим числом процессоров как схемы записи с аннулированием, так и схемы записи с обновлением данных, является использование для выполнения этих операций механизма шины. Для выполнения операции обновления или аннулирования процессор просто захватывает шину и транслирует по ней адрес, по которому должно производиться обновление или аннулирование данных. Все процессоры непрерывно наблюдают за шиной, контролируя появляющиеся на ней адреса. Процессоры проверяют не находится ли в их кэш-памяти адрес, появившийся на шине. Если это так, то соответствующие данные в кэше либо аннулируются, либо обновляются в зависимости от используемого протокола. Последовательный порядок обращений, присущий шине, обеспечивает также строго последовательное выполнение операций записи, поскольку когда два процессора конкурируют за выполнение записи в одну и ту же ячейку, один из них должен получить доступ к шине раньше другого. Один процессор, получив доступ к шине, вызовет необходимость обновления или аннулирования копий в других процессорах. В любом случае, все записи будут выполняться строго последовательно. Один из выводов, который следует сделать из анализа этой схемы заключается в том, что запись в разделяемый элемент данных не может закончиться до тех пор, пока она не захватит доступ к шине.
В дополнение к аннулированию или обновлению соответствующих копий блока кэш-памяти, в который производилась запись, мы должны также разместить элемент данных, если при записи происходит промах кэш-памяти. В кэш-памяти со сквозной записью последнее значение элемента данных найти легко, поскольку все записываемые данные всегда посылаются также и в память, из которой последнее записанное значение элемента данных может быть выбрано (наличие буферов записи может привести к некоторому усложнению).
Однако для кэш-памяти с обратным копированием задача нахождения последнего значения элемента данных сложнее, поскольку это значение скорее всего находится в кэше, а не в памяти. В этом случае используется та же самая схема наблюдения, что и при записи: каждый процессор наблюдает и контролирует адреса, помещаемые на шину. Если процессор обнаруживает, что он имеет модифицированную (“грязную”) копию блока кэш-памяти, то именно он должен обеспечить пересылку этого блока в ответ на запрос чтения и вызвать отмену обращения к основной памяти. Поскольку кэши с обратным копированием предъявляют меньшие требования к полосе пропускания памяти, они намного предпочтительнее в мультипроцессорах, несмотря на некоторое
увеличение сложности. Поэтому далее мы рассмотрим вопросы реализации кэш-памяти с обратным копированием.
Для реализации процесса наблюдения могут быть использованы обычные теги кэша. Более того, упоминавшийся ранее бит достоверности (valid bit), позволяет легко реализовать аннулирование. Промахи операций чтения, вызванные либо аннулированием, либо каким-нибудь другим событием, также не сложны для понимания, поскольку они просто основаны на возможности наблюдения. Для операций записи мы хотели бы также знать, имеются ли другие кэшированные копии блока, поскольку в случае отсутствия таких копий, запись можно не посылать на шину, что сокращает время на выполнение записи, а также требуемую полосу пропускания.
Чтобы отследить, является ли блок разделяемым, мы можем ввести дополнительный бит состояния (shared), связанный с каждым блоком, точно также как это делалось для битов достоверности (valid) и модификации (modified или dirty) блока. Добавив бит состояния, определяющий является ли блок разделяемым, мы можем решить вопрос о том, должна ли запись генерировать операцию аннулирования в протоколе с аннулированием, или операцию трансляции при использовании протокола с обновлением. Если происходит запись в блок, находящийся в состоянии “разделяемый” при использовании протокола записи с аннулированием, кэш формирует на шине операцию аннулирования и помечает блок как частный (private). Никаких последующих операций аннулирования этого блока данный процессор посылать больше не будет.
Процессор с исключительной (exclusive) копией блока кэш-памяти обычно называется “владельцем” (owner) блока кэш-памяти. При использовании протокола записи с обновлением, если блок находится в состоянии “разделяемый”, то каждая запись в этот блок должна транслироваться. В случае протокола с аннулированием, когда посылается операция аннулирования, состояние блока меняется с “разделяемый” на “неразделяемый” (или “частный”). Позже, если другой процессор запросит этот блок, состояние снова должно измениться на “разделяемый”. Поскольку наш наблюдающий кэш видит также все промахи, он знает, когда этот блок кэша запрашивается другим процессором, и его состояние должно стать “разделяемый”.
Поскольку любая транзакция на шине контролирует адресные теги кэша, потенциально это может приводить к конфликтам с обращениями к кэшу со стороны процессора. Число таких потенциальных конфликтов можно снизить применением одного из двух методов: дублированием тегов, или использованием многоуровневых кэшей с “охватом” (inclusion), в которых уровни, находящиеся ближе к процессору являются поднабором уровней, находящихся дальше от него. Если теги дублируются, то обращения процессора и наблюдение за шиной могут выполняться параллельно. Конечно, если при обращении процессора происходит промах, он должен будет выполнять арбитраж с механизмом наблюдения для обновления обоих наборов тегов. Точно также, если механизм наблюдения за шиной находит совпадающий тег, ему будет нужно проводить арбитраж и обращаться к обоим наборам тегов кэша (для выполнения аннулирования или обновления бита “разделяемый”), возможно также и к массиву данных в кэше, для нахождения копии блока.
Таким образом, при использовании схемы дублирования тегов процессор
должен приостановиться только в том случае, если он выполняет обращение к кэшу в тот же самый момент времени, когда механизм наблюдения обнаружил копию в кэше. Более того, активность механизма наблюдения задерживается только когда кэш имеет дело с промахом.
Если процессор использует многоуровневый кэш со свойствами охвата, тогда каждая строка в основном кэше имеется и во вторичном кэше. Таким образом, активность по наблюдению может быть связана с кэшем второго уровня, в то время как большинство активностей процессора могут быть связаны с первичным кэшем. Если механизм наблюдения получает попадание во вторичный кэш, тогда он должен выполнять арбитраж за первичный кэш, чтобы обновить состояние и возможно найти данные, что обычно будет приводить к приостановке процессора. Такое решение было принято во многих современных системах, поскольку многоуровневый кэш позволяет существенно снизить требований к полосе пропускания. Иногда может быть даже полезно дублировать теги во вторичном кэше, чтобы еще больше сократить количество конфликтов между активностями процессора и механизма наблюдения.
В реальных системах существует много вариаций схем когерентности кэша, в зависимости от того используется ли схема на основе аннулирования или обновления, построена ли кэш-память на принципах сквозной или обратной записи, когда происходит обновление, а также имеет ли место состояние “владения” и как оно реализуется. На рис. 97 представлены несколько протоколов с наблюдением и некоторые машины, которые используют эти протоколы.
§
Рассмотрим реализацию прерываний в наиболее простых симметричных многопроцессорных системах, в которых используется несколько процессоров, объединенных общей шиной. Каждый процессор выполняет свою задачу, задаваемую операционной системой (ОС). При этом процессоры совместно используют общие ресурсы системы (память, внешние устройства), обращение к которым регулируется ОС. В каждый момент времени один из процессоров является ведущим (master) – только он имеет доступ к системной шине. Другие процессоры в случае необходимости обращения к шине выдают соответствующий запрос. Эти запросы анализируются специальным устройством – арбитром шины, который работает под управлением ОС. В соответствии с определенным алгоритмом арбитр предоставляет доступ к шине одному из запросивших процессоров, который становится таким образом ведущим. Поддержку функционирования таких мультипроцессорных систем обеспечивает ряд современных ОС (Windows NТ, Novell NetWare и другие). Чаще всего симметричные мультипроцессорные системы содержат два или четыре процессора.
Характерным примером является система прерываний, реализованная в процессорах фирмы Intel. Так, например, процессоры семейства Р6(PentiumII, PentiumIII, Celeron и др.) имеют ряд средств для поддержки работы мультипроцессорных систем, обеспечивая для процессоров взаимный доступ к содержимому внутренней кэш-памяти данных (снупинг), возможность блокировки доступа к шине при выполнении ряда процедур и другие возможности. Различные модели этого семейства позволяют организовать эффективную работу двух- или четырехпроцессорных систем.
Одной из наиболее серьезных проблем при реализации мультипроцессорных систем является организация обслуживания внешних (аппаратных) прерываний. Классическая организация обслуживания с помощью контроллера прерываний, подающего сигнал запроса INTR и формирующего код команды INT n, с реализацией процессором цикла подтверждения прерывания ориентирована на использование в однопроцессорной системе. Для обеспечения функционирования мультипроцессорных систем в процессоры семейства Р6 введен программируемый контроллер прерываний с расширенными возможностями АРIС (АРIС – Аdvanced Programmable Interrupt Controller).
Рис. 97. Схема прерываний в многопроцессорной системе.
Внутренние контроллеры прерываний связаны между собой по специальной АРIC-шине (рис.97). Общие внешние запросы прерываний поступают на системный АРIС – контроллер, который реализован в виде отдельной микросхемы, разработанной и поставляемой компанией Intel.
Каждый из процессоров содержит локальный АРIС, имеющий две входных лини LINT 0, LINT 1, на которые поступают локальные запросы прерывания, обслуживаемые только данным процессором. При работе в однопроцессорной системе АРIС отключается, и выводы LINT 1-0 используются для подачи запросов немаскируемого NMI и маскируемого INTR прерываний.
Общие запросы прерывания поступают на системный АРIС, который после их анализа выдает соответствующие послания на внутреннюю АРIС – шину. Эта шина содержит три линии, на одну из которых (РIССLК) выдается синхросигнал, а две других (РIСD 1-0) служат для последовательного обмена информацией в процессе организации обслуживания поступивших запросов. При этом для внешних устройств, формирующих запросы прерывания, мультипроцессорная система выглядит как один процессор, а процедура обслуживания запросов соответствует процедуре, выполняемой серийным контроллером прерываний Intel 8259А, который широко используется в современных системах.
ЗАКЛЮЧЕНИЕ
Охватить все аспекты строения и организации вычислительных машин в одном издании (да и в рамках одного курса) не представляется возможным. Знания в этой области человеческой деятельности развиваются стремительно, и для поддержания соответствующего профессионального уровня специалист обязан не прекращать самообучение. Тем не менее, авторы надеются, что читатель увидел основные направления и тенденции в развитии вычислительной техники, а также осознал, что рассматривая какое либо техническое или архитектурное решение в области вычислительной техники, необходимо ответить не только на вопрос «как это функционирует?» но и «почему это сделано именно так?». Только такой анализ позволит эффективно применять полученные знания, быстро получать новые знания, и кто знает, может быть даже вписать свою страницу в историю развития информационных технологий.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Авен, О. И. Оценка качества и оптимизации вычислительных систем / О.И. Авен, Н. Я . Турин, А. Я. Коган. – М.: Наука, 1982. – 464 с.
2. Воеводин, В. В. Параллельные вычисления / В. В. Воеводин, Вл.В. Воеводин. – СПб.: БХВ-Петербург, 2002. – 608 с.
3. Воеводин, Вл. В. Методы описания и классификации вычислительных систем / Вл. В. Воеводин, А. П. Капитонова. – М.: Изд. МГУ, 1994. – 103 с.
4. Каган, Б. М.Электронные вычислительные машины и системы / Б. М. Каган. – М.: Энергоатомиздат, 1991. – 592 с.
5. Кургаев, А. Ф. Об оценке эффективности системы команд ЭВМ / А. Ф. Кургаев, А. В. Писарский. – УСИМ, 1981, № 1.– С. 40-44.
6. Ларионов, А. М. Вычислительные комплексы, системы и сети / А. М. Ларионов. – М.: Энергоатомиздат, 1987. – 287 с.
7. Мураховский, В. И. Железо ПК. Новые возможности / В. И. Мураховский. – СПб.: Питер, 2005. – 592с.
8. Опадчий, Ю. Ф. Аналоговая и цифровая электроника / Ю. Ф. Опадчий, О. П. Глудкин, А. И. Гуров. – М.: Горячая линия — Телеком, 2002. – 768 с.
9. Основы современных компьютерных технологий // Под ред. А. Д. Хомоненко. – СПб: КОРОНА принт, 1998. – 448 с.
10. Цилькер, Б. Я. Архитектура вычислительных систем / Б. Я. Цилькер, В. П. Пятков. – Рига: TSI, 2001.– 249с.
11. Цилькер, Б. Я. Организация ЭВМ и систем / Б. Я. Цилькер, С. А. Орлов. – СПб.: Питер, 2007. – 668с.
12. Бикташев, Р.А. Многопроцессорные системы. Архитектура, топология, анализ производительности: Учебное пособие / Р.А. Бикташев, В.С. Князьков. – Пенза : Пенз. гос. ун-т, 2003. – 103с.
13. Юров, В. Assembler / В. Юров. – СПб.: Питер, 2000. – 624с.
14. Flood J. E.Telecommunications Switching, Traffic and Networks / J.E. Flood Prentice-Hall, 1995.
15. Flynn, M.J.Parallel Processors Were the Future… and May Yet Be / M. J. Flynn. – IEEE Computer, Vol. 29, №. 12, Dec. 1996, pp. 151-152.
16. Hwang, K. Scalable parallel computing / K. Hwang, Z. Xu. – McGraw-Hill, 1998. – 356p.





