
Описание алгоритмов с использованием блок-схем
Для разработки структуры программы удобнее использовать обозначение алгоритма в виде блок-схемы (в английской литературе используется термин flow – chart). Для представления основных алгоритмических структур и блоков на блок-схемах используются специальные графические символы. Они приведены на рисунке








Составим алгоритм вычисления квадратного корня из произвольного положительного вещественного числа х методом Герона и запишем его на естественном языке, а также в виде блок-схемы. Метод основан на многократном применении формулы:
при
Числовая последовательность 

А теперь займёмся самым любимым занятием школьников всех времён и народов – решением квадратного уравнения:
Будем полагать, что коэффициенты этого уравнения 


возможны три случая:
1. Если 




Блок схема алгоритма приведена на рисунке:
Следует отметить, что данный алгоритм предназначен для решения узкого класса задач – квадратичных уравнений с “хорошими” коэффициентами. Если предположить, что коэффициенты могут принимать любые реальные значения, то существует риск того, что при определенных значениях коэффициента (например, ) возникнет аварийная ситуация (деление на ноль).
Алгоритм качества и программа качества должны быть стабильными, т.е. прерывание программы должно быть нормальным для всех входных параметров, хотя может сопровождаться предупреждением о некорректности входных данных. Алгоритм решения квадратичного уравнения, показанный на рисунке, обладает свойством устойчивости:

i | z |
0 | 1,00000 |
1 | 1,50000 |
2 | 1,41666 |
3 | 1,41421 |
4 | 1,41421 |
5 | 1,41421 |
Как видно из таблицы, уже после третьей итерации приближенное значение квадратного корня отличается от точного 1,414213 лишь в шестом знаке после запятой.
Описание алгоритмов на естественном языке
Когда речь идет о создании алгоритмов для процессора компьютера (электронной вычислительной машины), исполнитель является процессором. Упрощенная модель процессора включает в себя устройство для считывания данных, стек (специальная малообъемная оперативная память, предназначенная для временного хранения данных) и арифметическое устройство, способное выполнять арифметические действия.
Предположим, что программа, составленная для такого процессора, содержит числовые данные и символы для арифметических операций с такими данными. Приведем пример такой программы для вычисления двух чисел 2 и 3:
2, 3,
Давайте продолжим эту программу. Первая операция заключается в считывании значения 2 в стек. Затем второе значение (3) считывается в стек. Первое значение перемещается во вторую ячейку памяти. На третьем этапе выполнения программы вычисляется сумма двух прочитанных значений (они называются операндами). Результат этой операции – значение 5 – записывается в первую ячейку стека.
Рассматривался пример самой простой программы. Это запись алгоритма решения класса задач – задач для вычисления суммы двух чисел. Давайте назовем эти номера a и b. Тогда алгоритм можно записать следующим образом:
- Считать число a .
- Считать число b .
- Выполнить суммирование c := a b .
- Вывести число c .
Это пример записи алгоритма на естественном языке, т.е. на языке человеческого общения. Мы видим, что формулировка алгоритма не зависит от конкретных значений переменных a и b, так что его можно использовать для решения достаточно большого количества аналогичных задач, которые вместе образуют класс задач суммы. Алгоритм описывает действия не по конкретным значениям, а по абстрактным объектам.
Основными объектами программирования являются переменные . Переменные в программе отличаются от переменных, используемых при записи математических формул. Несмотря на сходство терминов, правила использования переменных в компьютерных программах отличаются от правил работы с математическими переменными.
Это различие должно быть понято. При программировании переменная может рассматриваться как одна или несколько ячеек памяти компьютера, которым присваивается определенное имя. Содержимое этих ячеек может измениться, но имя переменной остается неизменным. В математике значение переменной фиксируется внутри конкретной задачи, но меняется для других задач данного класса.
Именно поэтому конструкция
а := а 1
воспринимается программистом совершенно естественно, а уравнение
a = a 1
математик сочтёт неверным. В первом случае это означает вычисление суммы содержимого ячейки a и числовой константы 1 и введение результата в ту же ячейку a. Второй случай равен ложной идентификации 0 = 1.
Оставим алгоритм для решения следующей задачи. Давайте установим два значения x и y. Сравним эти значения и выведем имя более крупной переменной. Для этого достаточно сравнить оба значения и в зависимости от результата сравнения распечатать символ “х” и “у”:
- Ввести значение x .
- Ввести значение y .
- Если x < y , то напечатать «у», иначе напечатать «х».
В данном алгоритме используются алгоритмические структуры – линейная последовательность операций и ветвей (шаг 3, условный оператор). Последняя структура называется так потому, что после передачи ей управления алгоритм может быть выполнен на одной из двух возможных ветвей.
Для написания алгоритмов использовался естественный язык. Иногда используется полуофициальный язык с ограниченным словарным запасом (часто основанным на английском языке), промежуточный язык между естественным языком и языком программирования. Такой язык называется псевдокодом.
История развития понятия алгоритма
Понятие алгоритма является одним из основных понятий современной математики. Еще на самых ранних ступенях развития математики (Древний Египет, Вавилон, Греция) в ней стали возникать различные вычислительные процессы чисто механического характера. С их помощью искомые величины ряда задач вычислялись последовательно из исходных величин по определенным правилам и инструкциям. Со временем все такие процессы в математике получили название алгоритмов.
Термин алгоритм происходит от имени средневекового узбекского математика Аль-Хорезми, который еще в ІХ в. дал правила выполнения четырех арифметических действий в десятичной системе счисления.
Вплоть до 30-х годов прошлого века понятие алгоритма имело скорее методологическое, чем математическое значение. Под алгоритмом понимали конечную совокупность точно сформулированных правил, которые позволяют решать те или иные классы задач. Однако в этом определении не содержится точной характеристики того, что следут понимать под классом задач и под правилами их решения. В течение длительного времени математики довольствовались этим определением, поскольку общей теории алгоритмов фактически не существовало. Однако, практически не было серьезных случаев, когда математики разошлись бы во мнении относительно того, является ли алгоритмом тот или иной конкретно заданный процесс.
Положение существенно изменилось, когда на первый план выдвинулись такие алгоритмические проблемы, положительное решение которых было сомнительным. Действительно, одно дело доказать существование алгоритма, другое – его отсутствие. Первое можно сделать путем фактического описания процесса, решающего задачу. В этом случае достаточно и интуитивного понятия алгоритма, чтобы удостовериться в том, что описанный процесс есть алгоритм. Доказать несуществование алгоритма таким путем невозможно. Для этого надо точно знать, что такое алгоритм.
В двадцатых годах прошлого века задача такого определения понятия алгоритма стала одной из центральных математических проблем. Решение ее было получено в середине тридцатых годов в работах известных математиков: Гильберта, Геделя, Черча, Клини, Поста и Тьюринга.
В 50-е годы прошлого столетия существенный вклад в развитие теории алгоритмов внесли работы Колмогорова и Маркова. Формальные модели алгоритмов Поста, Тьюринга и Черча, равно как и модели Колмогорова и Маркова, оказались эквивалентными в том смысле, что любой класс проблем, разрешимых в одной модели, разрешим и в другой.
Хотя первоначально теория алгоритмов возникла в связи с внутренними потребностями теоретической математики (математическая логика, алгебра, геометрия и т.д. остаются и сегодня одной из основных областей приложения теории алгоритмов), другая область ее применения возникла в 40-х годах в связи с созданием быстродействующих электронных вычислительных и управляющих машин. Появление ЭВМ способствовало развитию теории алгоритмов, вызвало к жизни разделы этой теории , имеющие ярко выраженную прикладную направленность. Это, прежде всего, алгоритмические системы и алгоритмические языки, являющиеся основой современной теории программирования для универсальных ЭВМ, и способы точного описания отображений, реализуемых цифровыми автоматами.
Теория алгоритмов оказалась тесно связанной и с рядом областей лингвистики, экономики, физиологии мозга и психологии, философии, естествознания. Примером одной из задач этой области может служить точное описание алгоритмов, реализуемых человеком в процессе умственной деятельности.
2. Общие требования к алгоритму
Во всех сферах своей деятельности человек сталкивается с различными способами или методиками решения разнообразных задач. Они определяют порядок выполнения действий для получения желаемого результата – мы можем трактовать это как первоначальное или интуитивное определение алгоритма. Таким образом, можно нестрого определить алгоритм как однозначно трактуемую процедуру решения задачи. Дополнительные требования о выполнении алгоритма за конечное время для любых входных данных приводят к следующему неформальному определению алгоритма:
Алгоритм – это заданное на некотором языке конечное предписание, задающее конечную последовательность выполнимых и точно определенных элементарных операций для решения задачи, общее для класса возможных исходных данных.
Пусть  – множество исходных данных задачи
– множество исходных данных задачи  , а
, а  – множество возможных результатов. Тогда можно говорить, что алгоритм осуществляет отображение
– множество возможных результатов. Тогда можно говорить, что алгоритм осуществляет отображение
 .
.
Алгоритм называется частичным, если мы получаем результат только для некоторых  , и полным, если алгоритм получает правильный результат для всех .
, и полным, если алгоритм получает правильный результат для всех .
На сегодняшний день отсутствует одно исчерпывающее опредление алгоритма. Приведем несколько используемых определений.
Определение 1.(Колмогоров): Алгоритм – это всякая система вычислений, выполняемых по строго определенным правилам, которая после какого-либо числа шагов заведомо приводит к решению поставленной задачи.
Определение 2.(Марков): Алгоритм – это точное предписание, определяющее вычислительный процесс, идущий от варьируемых исходных данных к искомому результату.
В приведенных словесных определениях очевидна проблема однозначной трактовки терминов, в силу чего возникают следующие неопределенности с
- исполнителем предписаний,
- вычислительными возможностями исполнителя,
- указанием, какие именно операции для исполнителя являются «элементарными».
Более того, если даже алгоритм заведомо существует, его может быть очень трудно описать в некоторой зараннее заданной форме. Например, алгоритм завязывания шнурков.
Однако, несмотря на имеющиеся неопределенности и неоднозначности, различные определения алгоритма в явной или неявной форме постулируют следующие общие требования [Макконнелл]:
· Алгоритм должен содержать конечное количество элементарно выполнимых предписаний, т.е. удовлетворять требованию конечности записи;
· Алгоритм должен выполнять конечное количество шагов при решении задачи, т.е. удовлетворять требованию конечности действий;
· Алгоритм должен быт единым для всех допустимых исходных данных, т.е. удовлетворять требованию универсальности;
· Алгоритм должен приводить к правильному по отношению к поставленной задаче решению, т.е. удовлетворять требованию правильности.
Необходимо отметить, что сравнение алгоритмов по их эффективности, проверка их правильности и эквивалентности, определение областей применимости возможны только на основе формализации понятия алгоритма. В связи с этим чрезвычайно важно наличие формально строгого определения понятия алгоритма. Формализации данного понятия связаны с введением специальных математических конструкций – формальных алгоритмических систем или моделей вычислений, каковыми являются машина Поста, машина Тьюринга, рекурсивно-вычислимые функции Черча, и постулированием тезиса об эквивалентности такого формализма и понятия «алгоритм». Несмотря на принципиально разные модели вычислений, использующиеся в теории алгоритмов для определения термина «алгоритм», интересным результатом является формулировка гипотез об эквивалентности этих формальных определений.
§
Тьюринг дал четкое определение понятия метода. Отталкиваясь от интуитивного представления о методе как о некоем алгоритме, т.е. процедуре, которая может быть выполнена механически, без творческого вмешательства, он показал, как эту идею можно воплотить в виде подробной модели вычислительного процесса. Полученная модель вычислений, в которой каждый алгоритм разбивался на последовательность простых, элементарных шагов, и была логической конструкцией, названной впоследствии машиной Тьюринга.
Машину Тьюринга можно представить следующим образом. Это есть автоматически работающее устройство, способное находиться в конечном числе состояний. Среди ее состояний имеются два выделенных – начальное и конечное. Процесс функционирования осуществляется по шагам. Во время каждого из них машина Тьюринга переходит из одного состояния в какое-то другое, причем это другое состояние, в частности, может совпадать с предыдущим. Процесс начинается с начального состояния и заканчивается конечным.
Вся информация, необходимая для реализации алгоритма, хранится в памяти. Память представляет бесконечную в обе стороны ленту, разделенную на клетки. В каждой клетке ленты может быть записана какая-то одна буква из некоторого алфавита. Если в клетке ничего не записано, то считается, что в ней записана «пустая» буква.
В машине Тьюринга имеется комбинированная головка считывания-записи информации. Условно можно считать, что головка расположена над лентой. Процесс считывания-записи осуществляется последовательно по одной букве за один шаг. Во время считывания-записи головка находится над одной клеткой ленты.
При реализации каждого шага функционирования машины Тьюринга происходит следующее. Предположим, что головка считывания-записи расположена над какой-то клеткой, и машина Тьюринга находится в одном из своих состояний, отличном от конечного. Тогда в зависимости от состояния машины Тьюринга и буквы, записанной в клетке, осуществляется запись некоторой буквы в эту же клетку, а сама машина Тьюринга переходит в новое состояние. Вновь записанная буква, в частности, может совпадать с буквой, бывшей в клетке перед записью. После этого лента передвигается на одну клетку вправо или влево, или остается на месте. Как только машина Тьюринга переходит в конечное состояние, процесс останавливается.
Перечисление всех возможных шагов машины Тьюринга называется программой. Программа является точно описанным объектом. Вообще говоря, ее содержание зависит от используемого алфавита.
Конкретное описание машины Тьюринга может в деталях отличаться от рассмотренного. Например, память может представлять ленту, бесконечную только в одну сторону, в машине могут выделяться некоторые другие устройства, такие как исполнительное, лентопротяжное и т.п., можно допустить наличие нескольких головок считывания-записи со своими лентами и многое другое. Однако в любом случае процесс функционирования машины Тьюринга будет описываться некоторой программой. Так как машины Тьюринга достаточно адекватно отражают интуитивное понятие алгоритма, то это означает, что изучение структуры алгоритмов неизбежно связано с изучением структуры описывающих алгоритмы программ.
Формально машина Тьюринга может быть описана следующим образом:
Пусть заданы
· Конечное множество состояний  , в которых может находиться машина Тьюринга;
, в которых может находиться машина Тьюринга;
· Конечное множество символов ленты  ;
;
· Функция  (функция переходов или программа), которая задается отображением пары из декартова произведения
(функция переходов или программа), которая задается отображением пары из декартова произведения  (например, машина находится в состоянии
(например, машина находится в состоянии  и обозревает символ
и обозревает символ  ) в тройку из произведения
) в тройку из произведения 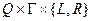 (машина переходит в состояние
(машина переходит в состояние  , заменяет символ на
, заменяет символ на  и пердвигается влево или вправо на одну ячейку ленты), т.е. :
и пердвигается влево или вправо на одну ячейку ленты), т.е. :  ;
;
· Существует выделенный пустой символ  ;
;
· Подмножество  – входной алфавит,
– входной алфавит,  , определяется как подмножество входных символов ленты, причем
, определяется как подмножество входных символов ленты, причем 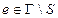 ;
;
· Одно из состояний  является начальным состоянием машины.
является начальным состоянием машины.
Решаемая проблема задается путем записи на ленту конечного количества символов  образующих слово
образующих слово  в алфавите
в алфавите  .
.

После задания проблемы машина переводится в начальное состояние, и головка устанавливается у самого левого непустого символа, после чего в соответствии с указанной функцией переходов :  машина начинает заменять обозреваемые символы, передвигать головку вправо или влево и переходить в другие состояния. Останов машины происходит в том случае, если для пары
машина начинает заменять обозреваемые символы, передвигать головку вправо или влево и переходить в другие состояния. Останов машины происходит в том случае, если для пары  функция перехода неопределена.
функция перехода неопределена.
Алгоритмы, реально используемые на практике, очень редко записываются в виде программ для машины Тьюринга. Но машина Тьюринга имеет чрезвычайно важное значение в силу следующего.
Тьюринг высказал предположение, что любой алгоритм в интуитивном смысле этого слова может быть представлен эквивалентной машиной в предложенной им модели вычислений. Это предположение известно как тезис Черча-Тьюринга. Каждый компьютер может моделировать машину Тьюринга, для этого достаточно моделировать операции перезаписи ячеек, сравнения и перехода к другой соседней ячейке с учетом изменения состояния машины. Таким образом, он может моделировать алгоритмы в машине Тьюринга, и из этого тезиса следует, что все компьютеры, независимо от мощности, архитектуры и других особенностей, эквивалентны с точки зрения принципиальной возможности решения алгоритмически разрешимых задач.
4. Алгоритмически неразрешимые проблемы: их существование и примеры
Существуют ли какие-нибудь проблемы, для которых невозможно придумать алгоритмы их решения? Утверждение о существовании алгоритмически неразрешимых проблем является весьма сильным – мы констатируем, что мы не только сейчас не знаем соответствующего алгоритма, но мы не сможем никогда принципиально его найти.
Сегодня при доказательстве алгоритмической неразрешимости некоторой задачи принято сводить ее к ставшей классической задаче – «задаче останова» машины Тьюринга.
Имеет место следующая теорема [Макконнелл].
Теорема. Не существует алгоритма (машины Тьюринга), позволяющего по описанию произвольного алгоритма и его исходных данных, при этом и алгоритм и данные заданы символами на ленте машины Тьюринга, определить, останавливается ли этот алгоритм на этих данных или работает бесконечно.
Таким образом, фундаметально алгоритмическая неразрешимость связана с бесконечностью выполняемых алгоритмом действий.
Примеры алгоритмически неразрешимых проблем.
Пример 1.Распределение девяток в записи числа  .Определим функцию
.Определим функцию  , где
, где  – количество девяток подряд в десятичной записи числа , а
– количество девяток подряд в десятичной записи числа , а  – номер самой левой после запятой девятки из девяток подряд. Поскольку
– номер самой левой после запятой девятки из девяток подряд. Поскольку 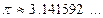 , то
, то  . Задача состоит в вычислении функции
. Задача состоит в вычислении функции  для произвольного .
для произвольного .
Поскольку число является иррациональным, мы не знаем распределение девяток, равно как и любых других цифр. Вычисление связано с вычислением последующих цифр в разложении числа до тех пор, пока мы не обнаружим девяток подряд. У нас нет общего метода вычисления , для некоторых вычисления могут продолжаться бесконечно – мы даже не знаем в принципе (по природе числа ) существует ли решение для всех значений .
Пример 2. Вычисление совершенных чисел. Совершенные числа – это числа, которые равны сумме своих делителей, за исключением самого числа, например: 28=1 2 4 7 14. Определим функцию  = -ое по счету совершенное число. Задача: вычислить для произвольного . Нет общего метода вычисления совершенных чисел, неизвестно даже, конечно или счетно множество совершенных чисел.
= -ое по счету совершенное число. Задача: вычислить для произвольного . Нет общего метода вычисления совершенных чисел, неизвестно даже, конечно или счетно множество совершенных чисел.
Пример 3.Десятая проблема Гильберта. Пусть задан  – многочлен степени с целыми коэффициентами. Существует ли алгоритм, который определяет имеет ли уравнение
– многочлен степени с целыми коэффициентами. Существует ли алгоритм, который определяет имеет ли уравнение  решение в целых числах. Ю.В.Матиясевич показал, что такого алгоритма не существует, т.е. отсутствует общий метод определения целых корней уравнения по его целочисленным коэффициентам.
решение в целых числах. Ю.В.Матиясевич показал, что такого алгоритма не существует, т.е. отсутствует общий метод определения целых корней уравнения по его целочисленным коэффициентам.
Пример 4.Проблема останова машины Тьюринга.
Пример 5.Проблема эквивалентности алгоритмов. По двум произвольным заданным алгоритмам, например, по двум машинам Тьюринга, определить, будут ли они выдавать одинаковые выходные результаты для любых входных данных.
Пример 6.Проблема тотальности. По записи произвольного заданного алгоритма определить, будет ли он останавливаться на всех возможных наборах исходных данных. Другая формулировка этой задачи: является ли частичный алгоритм А всюду определенным алгоритмом?
В теории алгоритмов проблемы, для которых может быть предложен частичный алгоритм их решения, частичный в том смысле, что он возможно, но не обязательно, за конечное количество шагов находит решение проблемы, называются частично разрешимыми проблемами. Например, проблема останова является частично разрешимой проблемой, а проблема эквивалентности и тотальности не являются таковыми.
Вопросы
1. Интуитивные определения понятия алгоритма, их недостатки.
2. Определения алгоритма по Колмогорову, по Маркову. Сравнение этих определений.
3. Общие требования к алгоритму, не зависящие от используемого определения алгоритма.
4. В чем заключается требование конечности записи алгоритма?
5. В чем заключается требование конечности действий алгоритма?
6. В чем заключаются требования универсальности и правильности алгоритма?
7. Постройте алгоритм получения положительной оценки на экзамене.
8. Постройте алгоритм для процесса завязывания шнурков, проверте его работу на своем коллеге.
9. Для чего служит машина Тьюринга?
10. Что представляет из себя алгоритмически неразрешимая проблема?
11. Является ли алгоритмически неразрешимой проблема решения уравнения:  , где
, где  – многочлен степени n? Почему?
– многочлен степени n? Почему?
Література
1. Дж. Макконнелл. Основы современных алгоритмов. 2-е дополненное издание. – М.: Техносфера, 2004. – 368 с.
2. Воеводин В.В. Параллельные вычисления / В.В.Воеводин, Вл.В.Воеводин. — СПб.: БХВ-Петербург, 2002. — 608 с.
§
Алгоритмы, в соответствии с которыми решение поставленных задач сводится к арифметическим действиям, называются численными алгоритмами. Численные алгоритмы занимают очень существенное место среди всевозможных алгоритмов, включающих, например, логические – алгоритмы, в соответствии с которыми решение поставленных задач сводится к логическим действиям,например, алгоритм поиска пути на графе.
При решении произвольной реальной задачи в общем случае невозможно получить точное значение искомого численного результата [53,55,60]. Существование неустранимой погрешности в математической модели объекта или процесса, фигурирующего в задаче (математическое описание задачи является неточным), погрешности входных данных, многие из которых в реальных условиях получены экспериментально, погрешность численного алгоритма, используемого для решения, и вычислительная, погрешности, возникающие при каких-либо дополнительных воздействиях на объект, которые часто трактуются как возмущения входных данных, приводят к необходимости их совокупного учета при оценке погрешности результата. Даже в случае, когда входные данные математической модели не имеют погрешностей, а алгоритм, выбранный для решения полученной математической задачи является точным [54], избежать вычислительной погрешности при проведении вычислений в системе чисел с плавающей точкой, а значит и погрешности в полученном результате, невозможно [69]. После построения математической модели реального процесса, которая необходимо удовлетворяет требованию адекватности (решение математической задачи, полученное с ее помощью, незначительно отличается от истинного решения реальной задачи), исходная задача и ее математическая формализация в процессе решения и анализа полученного результата, как правило, не разделяются. Однако, в силу особенностей машинной арифметики, невозможно в общем случае получить точное решение даже смоделированной математической задачи (пренебрегая неустранимой погрешностью и погрешностью метода) [53,60]. Действительно, для конечной системы чисел с плавающей точкой 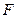 , реализованной в ЭВМ для представления бесконечного множества вещественных чисел
, реализованной в ЭВМ для представления бесконечного множества вещественных чисел  , арифметические операции обладают своими особенностями: основные законы арифметики могут нарушаться. Рассмотрим это подробнее.
, арифметические операции обладают своими особенностями: основные законы арифметики могут нарушаться. Рассмотрим это подробнее.
Множество чисел с плавающей точкой характеризуется четырьмя параметрами: числом разрядов  , основанием системы счисления
, основанием системы счисления 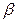 , границами
, границами 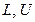 изменения показателя степени
изменения показателя степени  , при том, что каждое число
, при том, что каждое число  представляется в виде:
представляется в виде:
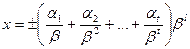 , (200)
, (200)
где  – целые числа, такие, что
– целые числа, такие, что  , а
, а 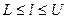 .
.
Часть 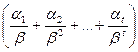 в (200) – дробная часть, или мантисса числа
в (200) – дробная часть, или мантисса числа 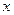 . Система нормализованная, если для
. Система нормализованная, если для 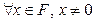 выполняется:
выполняется: 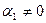 .
.
Таким образом, очевидно, что точно в системе могут быть представлены лишь конечное множество действительных чисел. Если число находится в границах представления чисел данной системы , однако не совпадает ни с одним из них, то оно приближается одним из чисел за счет операции округления (усечения) [Бахвалов], получая в результате определенную погрешность.
Пусть  . Результат выполнения арифметических операций над
. Результат выполнения арифметических операций над 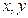 в системе будем обозначать
в системе будем обозначать 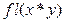 , где символ «*» может быть конкретизирован операцией сложения, вычитания, умножения, деления.
, где символ «*» может быть конкретизирован операцией сложения, вычитания, умножения, деления.
Идеальным для выполнения арифметических операций в системе является ситуация, когда сама операция над числами выполняется точно, а затем результат, при необходимости, либо усекается, либо округляется. На практике при выполнении арифметических операций обычно выделяются дополнительные разряды, полученный результат нормализуется, и лишь затем выполняется округление (усечение).
Рассмотрим гипотетическую систему , для которой 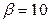 ,
,  , и вычислим в этой системе сумму 0.12 0.17 0.87. В точной арифметике 0.12 (0.17 0.87)=(0.12 0.17) 0.87. В системе результат левой части равен:
, и вычислим в этой системе сумму 0.12 0.17 0.87. В точной арифметике 0.12 (0.17 0.87)=(0.12 0.17) 0.87. В системе результат левой части равен:
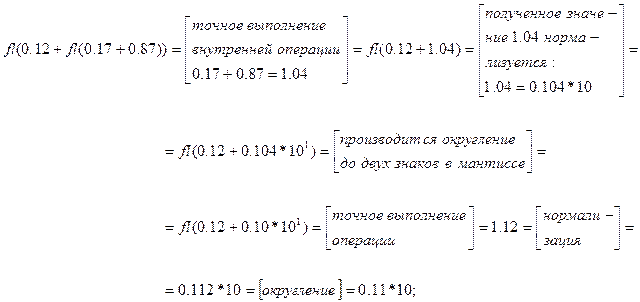
при этом результат правой части:
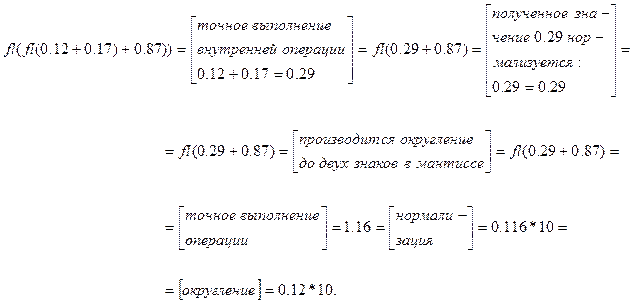
Очевидно, результат даже такого простого выражения зависит от порядка выполнения операций. Таким образом, одному алгоритму, записанному «на бумаге», соответствует множество «машинных» алгоритмов, в каждом из которых свой порядок выполнения действий, а значит, может быть и другой результат.
Полученное приближенное (в силу перечисленных выше причин) решение некоторой вычислительной задачи 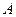 может рассматриваться как точное решение, но другой, возмущенной задачи
может рассматриваться как точное решение, но другой, возмущенной задачи 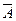 ( отличается от возмущением входных данных) [60]. В этом случае для определения качества полученного приближения необходимо иметь возможность оценить степень зависимости решения от возмущений исходных данных.
( отличается от возмущением входных данных) [60]. В этом случае для определения качества полученного приближения необходимо иметь возможность оценить степень зависимости решения от возмущений исходных данных.
§
Чтобы анализировать ошибки, порождаемые самим алгоритмом, требуется исследовать влияние погрешностей округлений в арифметических операциях. В такого рода исследованиях используется свойство, называемое обратной устойчивостью, определяемое следующим образом.
Пусть 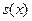 — некоторая вещественная функция. Через
— некоторая вещественная функция. Через  обозначим непосредственно выбранный численный алгоритм для вычисления . Необходимо отметить, что результат содержит вычислительную погрешность. Предположим, что является обратно устойчивым алгоритмом для [53], т.е. для всякого
обозначим непосредственно выбранный численный алгоритм для вычисления . Необходимо отметить, что результат содержит вычислительную погрешность. Предположим, что является обратно устойчивым алгоритмом для [53], т.е. для всякого  найдется малое
найдется малое  , такое, что:
, такое, что:
 .
.
Величина называется обратной ошибкой. Иначе говоря,  – это точный ответ для слабо возмущенной задачи
– это точный ответ для слабо возмущенной задачи  .
.
Для погрешности вычисленного значения 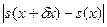 , исходя из соотношения (2.8), становится возможной оценка:
, исходя из соотношения (2.8), становится возможной оценка:
 ,
,
являющаяся произведением абсолютного числа обусловленности  и величины обратной ошибки
и величины обратной ошибки  .
.
При обратной устойчивости величина мала, тогда если абсолютное число обусловленности невелико, то мала будет и погрешность. Если же число обусловленности большое (или бесконечно большое), то несмотря на малое значение обратной ошибки [53] , результирующая погрешность может оказаться неприемлемо большой.
Программирование численных алгоритмов
Как правило, три главных соображения, которыми руководствуются при машинной реализации численных алгоритмов или выборе готовой программы, это
· Простота использования,
· Надежность,
· Временные затраты.
Если какая-то из уже существующих программ способна решить конкретную рассматриваемую задачу,то простота ее использования может перевесить все остальные факторы, например, временные затраты. Действительно, если задачу нужно решить лишь один или несколько раз, то, как правило, легче воспользоваться универсальной программой, составленной экспертами, чем писать свою более специализированную программу.
Существует три основные формы использования программных продуктов, разработанных другими специалистами. Первая форма – это традиционная библиотека, представляющая собой набор программ для решения фиксированного круга задач, например, решения систем линейных уравнений, вычисления собственных значений и т.д. Примером может служить библиотека LAPACK.
Второй формой являются программные среды, значительно «более дружественные к пользователю» по сравнению с библиотеками типа LAPACK. Это достигается ценой утраты производительности. Эту форму представляет коммерческая система Matlab и ряд подобных ей систем. Matlab можно рассматривать как простую интерактивную программную среду, где большинство операций линейной алгебры реализованы как встроенные функции. Однако Matlab принимает ряд алгоритмических решений автоматически, не консультируясь с пользователем, поэтому получаемые этим путем программы могут работать медленнее, чем удачно выбранные библиотечные программы.
Третья форма – это шаблоны или, иначе говоря, рецепты для сборки сложных алгоритмов из более простых «строительных блоков». Шаблоны полезны в ситуации, когда алгоритм можно построить многими разными способами, но при этом отсутствует простое правило выбора наилучшей конструкции для конкретной входной задачи. Таким образом, значительная роль в конструировании оставлена пользователю. Примером подобного подхода может служить книга «Шаблоны для решения линейных систем. Строительные блоки для итерационных методов».
Вопросы
- Какие алгоритмы называются численными, логическими?
- Почему численным алгоритмом практически невозможно получить точное решение задачи?
- Особенности машинной арифметики. С чем связаны эти особенности?
- Как можно рассматривать приближенное решение вычислительной задачи?
- Число обусловленности задачи. Абсолютное и относительное число обусловленности функции.
- Вывести формулу абсолютного числа обусловленности функции одной переменной, многих переменных?
- Какой алгоритм является обратно устойчивым?
- Чем, как правило, руководствуются при машинной реализации численных алгоритмов или выборе готовой программы?
Литература
- Дж. Макконнелл. Основы современных алгоритмов. 2-е дополненное издание. – М.: Техносфера, 2004. – 368 с.
2. Кобозєва А.А., Мачалін І.О., Хорошко В.О. Аналіз захищеності інформаційних систем. – К.: Вид. ДУІКТ, 2021. – 316 с.
3. Кобозева А.А., Хорошко В.А. Анализ информационной безопасности. – К.: Изд.ГУИКТ, 2009. – 251 с.
4. Деммель Дж. Вычислительная линейная алгебра / Дж.Деммель; пер.с англ. Х.Д.Икрамова. — М.: Мир, 2001. — 430 с.
5. Бахвалов Н.С. Численные методы / Н.С.Бахвалов, Н.П.Жидков, Г.М.Кобельков. — М.: БИНОМ. Лаборатория знаний, 2006. — 636 с.
6. Каханер Д. Численные методы и программное обеспечение / Д.Каханер, К.Моулер, С.Нэш; пер. с англ. Х.Д.Икрамова. — М.: Мир, 2001. — 575 с.
7. E.Anderson, Z.Bai, C.Bischof, J.Demmel, J.Dongarra, J.Du Croz, A.Greenbaum, S.Hammarling, A.McKenney, S.Ostrouchov, and D.Sorensen. LAPACK Users’ Guide (2nd edition). SIAM, Philadelphia,PA, 1995.
§
Одну и ту же задачу может решать множество алгоритмов. Эффективность работы каждого из них описывается разнообразными характеристиками. Основные характеристики – это
· Вычислительная сложность;
· Запросы к памяти.
Прежде чем анализировать эффективность алгоритма, нужно доказать, что данный алгоритм правильно решает задачу. В противном случае вопрос об эффективности не имеет смысла.
При анализе алгоритма определяется количество «времени» для его выполнения. Это не реальное число секунд или других промежутков времени, а число операций, выполняемых алгоритмом. Число операций измеряет относительное время выполнения алгоритма или его вычислительную сложность. Фактическое количество секунд работы алгоритма непригодно для его анализа, т.к.
а) нас интересует относительная эффективность алгоритма;
б) алгоритм не становится лучше (хуже), если его перенести на более быстрый (медленный) компьютер.
Более того, даже фактическое количество операций алгоритма на тех или иных входных данных не представляет большого интереса и не очень много сообщает об алгоритме. Вместо этого более важной и интересной является зависимость числа операций алгоритма от размера входных данных. Мы можем сравнивать два алгоритма по скорости роста числа операций. Именно скорость роста играет ключевую роль, и, как правило, рассматривается как показатель вычислительной сложности алгоритма, поскольку при небольшом размере входных данных алгоритм А может требовать меньшего количества операций, чем алгоритм В, но при росте объема входных данных ситуация может поменяться на противоположную.
Два самых больших класса алгоритмов – это
- алгоритмы с повторением,
- рекурсивные.
В основе алгоритмов с повторением лежат циклы и условные выражения; для анализа таких алгоритмов требуется оценить число операций, выполняемых внутри цикла, и число итераций цикла.
Рекурсивные алгоритмы разбивают большую задачу на фрагменты и применяются к каждому фрагменту отдельно. Такие алгоритмы называются иногда «разделяй и властвуй». В процессе решения большой задачи путем деления ее на меньшие создаются небольшие простые и понятные алгоритмы. Анализ рекурсивного алгоритма требует подсчета количества операций, необходимых для разбиения задачи на части, выполнения алгоритма на каждой из частей и объединения отдельных результатов для решения задачи в целом. Объединяя эту информацию и информацию о числе частей, мы можем вывести рекурентное соотношение для сложности алгоритма.
Анализируя алгоритм, можно получить представление о том, сколько времени займет решение данной задачи при помощи данного алгоритма. Для каждого алгоритма необходимо оценивать, насколько быстро решается задача на множестве (массиве) входных данных длины  .
.
Одну и ту же задачу можно решить при помощи различных алгоритмов. Анализ алгоритмов дает инструмент для выбора алгоритма.
Пример. Выбрать наибольшую из трех величин  .
.

В каждом алгоритме делается два сравнения. Первый алгоритм легче прочесть и понять, но с точки зрения выполнения на компьютере у них одинаковый уровень сложности, но первый требует больше памяти из-за временной переменной . Это не играет значительной роли, если сравниваются числа или символы, но при работе с другими типами данных это может стать существенным. Многие современные языки программирования позволяют определять операторы сравнения для больших и сложных объектов или записей. В этих случаях размещение временной переменной может потребовать много места. При анализе эффективности алгоритмов нас, в первую очередь, будет интересовать вопрос времени, но в тех случаях, когда память играет существенную роль, мы будем обсуждать и ее.
Различные характеристики алгоритмов предназначены для сравнения эффективности разных алгоритмов, решающих одну задачу. Не имеет смысла сравнивать между собой, например, алгоритм сортировки и алгоритм умножения матриц.
Результат анализа алгоритмов – не формула для точного количества секунд или компьютерных циклов, которые потребует конкретный алгоритм. Такая информация бесполезна, т.к. в этом случае нужно указывать также тип компьютера, используется ли он одним пользователем или несколькими, какой у него процессор и тактовая частота, полный или редуцированный набор команд на чипе процессора и насколько хорошо компилятор оптимизирует выполняемый код. Эти условия влияют на скорость работы программы, реализующей алгоритм. Учет этих условий означал бы, что при переносе программы на более быстрый компьютер алгоритм становится лучше, т.к. он работает быстрее.Но это не так, поэтому анализ не должен учитывать указанных особенностей компьютера.
В случае небольшой или простой программы количество выполняемых алгоритмом операций как функцию от можно посчитать точно. Однако в большинстве случаев в этом нет нужды. Действительно, рассмотрим для примера два простых гипотетических алгоритма, один из которых требует для своей реализации  операций, а второй –
операций, а второй –  . Очевидно, что разница между ними становится незаметной, как только становится достаточно большим. В силу этого имеет смысл оценивать главный член в формуле зависимости количества операций от размера входных данных. В рассмотренном случае – это
. Очевидно, что разница между ними становится незаметной, как только становится достаточно большим. В силу этого имеет смысл оценивать главный член в формуле зависимости количества операций от размера входных данных. В рассмотренном случае – это  .
.
Классы входных данных
Роль входных данных в анализе алгоритмов чрезвычайно велика, поскольку последовательность действий алгоритма определяется не в последнюю очередь входными данными. Например, чтобы найти наибольший элемент в списке из  элементов, можно воспользоваться следующим алгоритмом:
элементов, можно воспользоваться следующим алгоритмом:

Если список изначально упорядочен в порядке убывания, то перед началом цикла будет сделано одно присваивание, а в теле цикла присваиваний не будет вообще. Если список первоначально упорядочен по возрастанию, то всего будет сделано присваиваний. При анализе необходимо рассмотреть различные возможные множества входных данных, поскольку при ограничении одним множеством, оно может оказаться тем самым, на котором решение самое быстрое (медленное). В результате можно получить ложное представление об алгоритме. Вместо этого, как правило, рассматриваются все типы входных множеств. Для этого различные входные множества разбиваются на классы в зависимости от поведения алгоритма на каждом множестве. Такое разбиение позволяет уменьшить количество рассматриваемых возможностей. Например, число различных расстановок 10 различных чисел в списке есть 10!=3628800. Применим к списку из 10 чисел алгоритм поиска наибольшего элемента. Имеется 362880 входных множеств, у которых первое число является наибольшим; они все помещаются в один класс. Для любого множества из этого класса алгоритм сделает единственное присваивание. Если наибольшее по величине число стоит на втором месте, то алгоритм сделает ровно два присваивания. Все такие множества (их 362880) можно поместить в другой класс. Очевидно, число присваиваний будет на единицу возрастать при последовательном изменении положения наибольшего числа от 1 до . Таким образом можно разбить все входные множества на разных классов по числу производимых присваиваний. Очевидно, нет необходимости выписывать или описывать детально все множества, оказавшиеся в одном классе.
Как только выделены классы, просматривается поведение алгоритма на одном множестве из каждого класса. Если классы выбраны правильно, то на всех множествах входных данных одного класса алгоритм производит одинаковое количество операций, а на множествах из другого класса это количество, в общем случае, будет другим.
§
В основном сложность алгоритмов обсуждается по времени, однако в некоторых случаях значимым является и вопрос используемой алгоритмом памяти. Этот вопрос был особенно актуальным на ранних этапах развития компьютеров при ограниченных объемах компьютерной памяти (как внутренней, так и внешней), однако не потерял своей актуальности и на сегодняшний день, поскольку с развитием информационных технологий, проникновением их во все сферы жизни общества, использование вычислительной техники для решения задач из разных областей человеческой деятельности, задач большой и очень большой размерности, этот анализ приобрел принципиальный характер.
Все алгоритмы разделяются на такие, которым достаточно ограниченной памяти, и те, которым нужно дополнительное пространство [Макконнелл]. Иногда программистам приходится выбирать более медленный алгоритм лишь потому, что он обходится имеющейся памятью и не требует внешних устройств.
Спрос на компьютерную память велик, поэтому и важен вопрос, какие данные необходимо хранить, а также эффективные способы хранения. Проиллюстрируем сказанное на примере. Предположим, что производится запись вещественного числа из сегмента [-10,10], имеющего один десятичный знак после запятой. При записи вещественного числа большинство компьютеров потратит от 4 до 8 байтов памяти. Однако если предварительно умножить число на 10, то для хранения полученного целого числа из сегмента [-100,100] потребуется всего 1 байт.
При взгляде на программное обеспечение, предлагаекмое на рынке сегодня, ясно, что необходимый подробный анализ памяти во многих случаях проведен не был. Объем памяти, необходимый даже для сравнительно простых программ, измеряется мегабайтами. Разработчики программ часто не отдают себе отчет в необходимости экономии места, полагая, что если у пользователя недостаточно памяти, то он может ее приобрести и установить дополнительно. Этот подход является крайне неправильным и негативным, в результате его компьютеры приходят «в негодность» задолго до того, как они действительно устаревают.
Новую струю внесло распространение в настоящий момент карманных компьютеров, у которых ограниченный объем памяти, что сделало критичным обеспечение возможности компактного хранения данных.
Вопросы
1. Какие основные характеристики алгоритма оцениваются при его анализе?
2. Как целесообразно оценивать «время» выполнения алгоритма? Почему? Что такое вычислительная сложность алгоритма?
3. В каких случаях сравнивается эффективность работы разных алгоритмов?
4. Должен ли анализ алгоритма учитывать особенности компьютера, на котором этот алгоритм реализован? Почему?
5. Влияют ли входные данные задачи на последовательность действий алгоритма? Привести пример.
6. Что представляют из себя классы входных данных?
7. Насколько значимым в настоящее время является вопрос используемой алгоритмом памяти?
Литература
1. Дж. Макконнелл. Основы современных алгоритмов. 2-е дополненное издание. – М.: Техносфера, 2004. – 368 с.
2. Гуц А.К. Математическая логика и теория алгоритмов: Учебное пособие. – Омск: Изд-во Наследие. Диалог-Сибирь, 2003. – 108 с.
3. Деммель Дж. Вычислительная линейная алгебра / Дж.Деммель; пер.с англ. Х.Д.Икрамова. — М.: Мир, 2001. — 430 с.
4. Бахвалов Н.С. Численные методы / Н.С.Бахвалов, Н.П.Жидков, Г.М.Кобельков. — М.: БИНОМ. Лаборатория знаний, 2006. — 636 с.
5. Каханер Д. Численные методы и программное обеспечение / Д.Каханер, К.Моулер, С.Нэш; пер. с англ. Х.Д.Икрамова. — М.: Мир, 2001. — 575 с.
Лекция 4. Оценка вычислительной сложности алгоритма
План
Предварительные шаги для оценки вычислительной сложности алгоритма
Скорость роста алгоритма
Анализ подходов, связанных с поиском информации
Предварительные шаги для оценки вычислительной сложности алгоритма
Подсчет вычислительной сложности алгоритма состоит из двух основных шагов:
Шаг 1. Выбор значимой операции или группы операций.
Шаг 2. Определение, какие из выбранных операций содержатся в теле алгоритма, а какие составляют накладные расходы или уходят на регистрацию и учет данных.
В качестве значимых часто (но не обязательно) выступают операции двух типов:
- Сравнение,
- Арифметические операции.
Арифметические операции разбиваются на две группы:
- Аддитивные,
- мультипликативные.
Аддитивные операторы (сложения) включают сложение, вычитание, увеличение и уменьшение счетчика.
Мультипликативные операторы (умножения) включают умножение, деление, взятие остатка по модулю.
Разбиение на эти две группы связано с тем, что умножения работают дольше, чем сложения. На практике некоторые алгоритмы считаются предпочтительнее других, если в них меньше умножений, даже если число сложений при этом пропорционально возрастает.
Поскольку при анализе алгоритма выбор входных данных может существенно повлиять на его выполнение, желательно найти такие данные, которые обеспечивают как самое быстрое, так и самое медленное выполнение алгоритма, а также оценить среднюю эффективность алгоритма на всех возможных наборах данных. Очень часто при анализе алгоритма оценивается лишь наихудший (самый медленный) вариант.
Скорость роста алгоритма
Точное значение количества операций, выполненных алгоритмом, не играет существенной роли в его анализе. Более важной оказывается скорость роста этого числа при возрастании объема входных данных. Она называется скоростью роста алгоритма. Именно эта характеристика часто и фигурирует как оценка вычислительной сложности алгоритма.
Существенным является общий характер поведения алгоритмов, а не подробности этого поведения. Предположим, что количество операций четырех различных алгоритмов определяется в соответствии с функциями

где – длина массива входных данных.
Если рассмотреть графики этих функций (рис.4.1)

Рис. 4.1.
например, на промежутке от 1 до 35, то становится очевидным, что несмотря на то, что функция  сначала растет медленнее всех рассматриваемых функций, при росте аргумента она увеличивает скорость возрастания быстрее всех остальных, что приводит к тому, что, начиная с некоторого значения аргумента , ее значения (а значит количество операций и время выполнения соответствующего алгоритма) становятся значительно больше значений всех остальных рассматриваемых функций.
сначала растет медленнее всех рассматриваемых функций, при росте аргумента она увеличивает скорость возрастания быстрее всех остальных, что приводит к тому, что, начиная с некоторого значения аргумента , ее значения (а значит количество операций и время выполнения соответствующего алгоритма) становятся значительно больше значений всех остальных рассматриваемых функций.
Таким образом, при анализе алгоритмов существенным является поведении функции зависимости количества операций от размера входных данных при больших значениях аргумента.
Некоторые часто встречающиеся функции приведены в таблице 4.1. Очевидно, что при небольших размерах входных данных значения функций отличаются незначительно, при росте этих размеров разница существенно возрастает. Поэтому существенным является поведение функции на больших объемах входных данных, поскольку на малых объемах принципиальная разница оказывается скрытой.
Таблица 4.1-
Для иллюстрации последующего вывода рассмотрим пример функции, которая трактуется как закон зависимости количества арифметических операций некоторого гипотетического алгоритма от размера входных данных :
 .
.
Предложенная функция является суммой нескольких функций, скорость возрастания которых различна. Очевидно, что скорость роста всей  будет определяться самым быстровозрастающим слагаемым –
будет определяться самым быстровозрастающим слагаемым –  . Иначе говоря, быстрорастущие функции доминируют функции с более медленным ростом, что приводит к тому, что если сложность алгоритма представляет собой сумму двух или нескольких функций, то для оценки алгоритма целесообразно отбрасывать все функции, кроме тех, которые растут быстрее всех.
. Иначе говоря, быстрорастущие функции доминируют функции с более медленным ростом, что приводит к тому, что если сложность алгоритма представляет собой сумму двух или нескольких функций, то для оценки алгоритма целесообразно отбрасывать все функции, кроме тех, которые растут быстрее всех.
Определение. Говорят, что функции  и
и  связаны соотношением (или сравнимы)
связаны соотношением (или сравнимы)

(читается: функция есть О-большое от ), если
 .
.
Рассмотрим другой пример:
 .
.
Ясно, что скорость возрастания будет определяться первым слагаемым –  , остальными слагаемыми при оценке скорости роста можно пренебречь. Кроме того:
, остальными слагаемыми при оценке скорости роста можно пренебречь. Кроме того:
 ,
,
Из чего вытекает, что
 .
.
Отбрасывая все младшие члены, скорость роста которых меньше, получаем порядок вычислительной сложности алгоритма [Макконнелл]. В предыдущем рассмотренном примере поскольку  , то соответствующий гипотетический алгоритм имеет вычислительную сложность порядка
, то соответствующий гипотетический алгоритм имеет вычислительную сложность порядка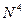 .
.
§
Поиск необходимой информации в списке – одна из фундаментальных задач теоретического программирования. При обсуждении алгоритмов поиска мы предполагаем, что информация содержится в записях, составляющих некоторый список, который представляет собой массив данных в программе. Записи, или элементы списка, идут в массиве последовательно и между ними нет промежутка. Номера записей в списке идут от 1 до N– полного числа записей. В принципе записи могут быть составлены из полей, однако нас будут интересовать значения лишь одного из этих полей, называемого ключом. Списки могут быть неотсортированы или отсортированы по значению ключевого поля. В неотсортированном списке порядок записей случаен, в отсортированном они идут в порядку возрастания ключа. Поиск нужной записи в неотсортированном списке сводится к просмотру всего списка до того, как нужная запись будет найдена. Это простейший из алгоритмов поиска. Этот алгоритм не очень эффективен, но работает на произвольном списке.
В отсортированном списке возможен также двоичный поиск. Двоичный поиск использует преимущества, предоставляемые имеющимся упорядочиванием, для того, чтобы отбрасывать за одно сравнение больше одного элемента. В результате поиск становится более эффективным.
Последовательный поиск. В алгоритмах поиска нас интересует процесс просмотра списка в поисках некоторого конкретного элемента, называемого целевым. Предполагаем, что список неотсортирован. Алгоритмы поиска возвращают индекс записи, содержащей нужный ключ. Если ключевое значение не найдено, то алгоритм поиска может возвращать значение индекса, превышающее верхнюю границу массива. Пусть элементы списка имеют номера от 1 до N. Если целевой элемент отсутствует в списке, будет возвращаться 0. Для простоты предполагается, что ключевые значения не повторяются.
Алгоритм последовательного поиска последовательно просматривает по одному элементу списка, пока не обнаружит целевой. Чем дальше в списке находится конкретное значение ключа, тем больше времени уйдет на его поиск.
Анализ наихудшего случая У алгоритма последовательного поиска два наихудших случая: целевой элемент стоит в списке последним или отсутствует вообще. Здесь потребуется Nсравнений. N– верхняя граница сложности любого алгоритма поиска.
Между понятиями верхней границы сложности и сложности в наихудшем случае есть разница. Верхняя граница присуща самой задаче, а понятие наихудшего случая относится к решающему ее конкретному алгоритму.
Двоичный поиск. При сравнении целевого значения со средним элементом отсортированного списка возможен один из трех результатов: значения равны, целевое значение меньше (больше) элемента списка. В первом, наилучшем случае, поиск завершен. В остальных двух случаях мы можем отбросить половину списка. Когда целевое значение меньше среднего элемента, то если оно имеется в списке, то находится только перед средним элементом, значит половину списка после него можно сразу отбросить. Аналогично, если целевое значение больше среднего. При повторении этой процедуры можно отбросить половину оставшейся части списка и т.д.
Анализ наихудшего случаяДля простоты предположим, что  . На первом шаге 1 сравнение, после которого остается
. На первом шаге 1 сравнение, после которого остается  элементов. Затем еще одно сравнение, после которого
элементов. Затем еще одно сравнение, после которого  элементов и т.д. Количество сравнений равно количеству шагов. После последнего останется только один элемент, т.е.
элементов и т.д. Количество сравнений равно количеству шагов. После последнего останется только один элемент, т.е.  . Количество шагов равно
. Количество шагов равно  .
.
Выборка.Иногда нужен элемент из списка, обладающий некоторыми специальными свойствами, а не имеющий некоторое конкретное значение. Другими словами, вместо записи с некоторым конкретным значением поля нас интересует, скажем, запись с наибольшим, наименьшим или средним значением этого поля. В более общем случае нас интересует запись с к-ым по величине значением поля.
Один из способов найти такую запись – отсортировать по убыванию список, тогда искомая запись окажется на к-ом месте. Но на это уйдет гораздо больше сил, чем необходимо, ведь значения, меньшие к-ого, нас не интересуют.
Другой подход: находим наибольшее значение в списке и помещаем его в конец списка.Затем находится наибольшее значение в оставшейся части списка, исключая уже найденное. В результате получаем второе по величине значение списка, которое помещается на второе с конца место. Повторив процедуру к раз, мы найдем к-ое по величине значение.
Вычислительная сложность алгоритма: на первом проходе – N-1сравнение, на втором – N-2 и т.д., т.е. общее количество операций –
 .
.
Вопросы
1. Какие предварительные шаги предпринимаются для оценки вычислительной сложности алгоритма?
2. На какие две группы разбиваются арифметические операции? Почему?
3. Какие наборы данных желательно найти при оценке вычислительной сложности алгоритма?
4. Что называется скоростью роста алгоритма?
5. Что такое порядок вычислительной сложности алгоритма? Как он оценивается?
6. Что представляет из себя последовательный поиск информации, двоичный поиск, выборка?
Литература
1. Дж. Макконнелл. Основы современных алгоритмов. 2-е дополненное издание. – М.: Техносфера, 2004. – 368 с.
2. Гуц А.К. Математическая логика и теория алгоритмов: Учебное пособие. – Омск: Изд-во Наследие. Диалог-Сибирь, 2003. – 108 с.
3. Деммель Дж. Вычислительная линейная алгебра / Дж.Деммель; пер.с англ. Х.Д.Икрамова. — М.: Мир, 2001. — 430 с.
4. Бахвалов Н.С. Численные методы / Н.С.Бахвалов, Н.П.Жидков, Г.М.Кобельков. — М.: БИНОМ. Лаборатория знаний, 2006. — 636 с.
5. Каханер Д. Численные методы и программное обеспечение / Д.Каханер, К.Моулер, С.Нэш; пер. с англ. Х.Д.Икрамова. — М.: Мир, 2001. — 575 с.
Лекция 5. Сложностные классы задач
План
1. Класс Р – задачи с полиномиальной сложностью
§
К задаче вычисления значения многочлена приводят многие задачи, Например, вычисление значений тригонометрических функций, которое осуществляется путем предварительного разложения функции в степенной ряд с последующим подсчетом усеченной суммы этого ряда (которая представляет из себя многочлен).
Общий вид многочлена:
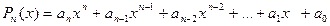
Будем предполагать, что все коэффициенты известны и записаны в массив 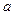 . Значение нужно вычислить в т. .
. Значение нужно вычислить в т. .
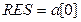 ,
, 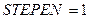
Для 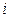 от 1 до
от 1 до 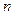
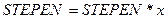
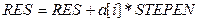
Конец цикла
Возврат 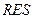
Вычислительная сложность – 3n.
Схема Горнера.
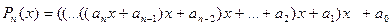 .
.
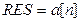
Для от 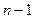 до 0
до 0
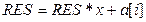
Конец цикла
Возврат
Вычислительная сложность – 2n.
Предварительная обработка коэффициентов. Результат можно еще улучшить, если обработать коэффициенты до начала вычислений. Основная идея: выразить многочлен через многочлены меньшей степени. Например, для вычисления 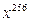 можно в цикле выполнить 255 умножений, а можно
можно в цикле выполнить 255 умножений, а можно 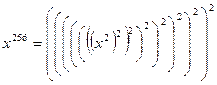 . Положим
. Положим
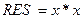
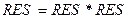 – 7 раз
– 7 раз
Для того, чтобы метод предварительной обработки коэффициентов работал, нужно, чтобы многочлен был унимодальным (т.е. 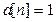 ), а степень многочлена на 1 меньше некоторой степени двойки (
), а степень многочлена на 1 меньше некоторой степени двойки ( 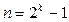 для некоторого
для некоторого 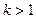 ). Преимущества описываемого подхода могут оказаться настолько велики, что иногда стоит добавить к многочлену слагаемые, позволяющие его применить, а затем вычесть добавленные значения из окончательного результата. Например, если мы имеем дело с многочленом 30 степени, то нужно прибавить к нему
). Преимущества описываемого подхода могут оказаться настолько велики, что иногда стоит добавить к многочлену слагаемые, позволяющие его применить, а затем вычесть добавленные значения из окончательного результата. Например, если мы имеем дело с многочленом 30 степени, то нужно прибавить к нему 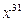 , найти разложение, а затем вычесть из каждого результата вычисления. Алгоритм все равно будет работать быстрее остальных методов.
, найти разложение, а затем вычесть из каждого результата вычисления. Алгоритм все равно будет работать быстрее остальных методов.
Многочлен представляется в виде: 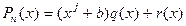 , где
, где 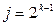 . В обоих многочленах
. В обоих многочленах 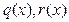 будет вдвое меньше членов, чем в
будет вдвое меньше членов, чем в  . Для получения нужного результата мы вычислим по отдельности , а затем сделаем одно дополнительное умножение и два сложения. Если при этом правильно выбрать значение
. Для получения нужного результата мы вычислим по отдельности , а затем сделаем одно дополнительное умножение и два сложения. Если при этом правильно выбрать значение  , то оба многочлена оказываются унимодальными, причем степень каждого из них позволяет применить к каждому из них ту же самую процедуру. Ее последовательное применение позволяет сэкономить вычисления.
, то оба многочлена оказываются унимодальными, причем степень каждого из них позволяет применить к каждому из них ту же самую процедуру. Ее последовательное применение позволяет сэкономить вычисления.
Рассмотрим пример: 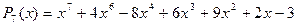 . Определим
. Определим 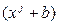 . Поскольку степень многочлена равна 7, то
. Поскольку степень многочлена равна 7, то 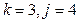 . Выберем значение таким образом, чтобы оба многочлена были унимодальными:
. Выберем значение таким образом, чтобы оба многочлена были унимодальными: 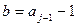 . Для нашего примера
. Для нашего примера 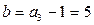 . Теперь мы хотим найти , удовлетворяющие уравнению
. Теперь мы хотим найти , удовлетворяющие уравнению
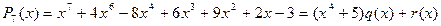 .
.
Многочлены – это частное и остаток от деления 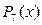 на
на 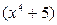 . Деление с остатком дает:
. Деление с остатком дает:
На следующем шаге мы можем применить ту же самую процедуру к каждому из многочленов :
 ;
; 
В результате:
 .
.
Для вычисления 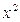 – одно умножение. Еще одно умножение для
– одно умножение. Еще одно умножение для 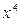 .
.
Способ Умножения Сложения
Стандартный 13 7
Схема Горнера 7 7
Предварительная обработка 5 10
Способ Умножения Сложения
Стандартный 2N-1 N
Схема Горнера N N
Предварительная обработка 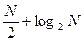
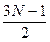
В последнем алгоритме удалось сэкономить 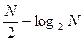 умножений за счет дополнительных
умножений за счет дополнительных 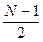 сложений по сравнению со схемой Горнера. Во всех существующих вычислительных системах обмен умножений на сложения считается выгодным, поэтому предварительная обработка коэффициентов повышает эффективность.
сложений по сравнению со схемой Горнера. Во всех существующих вычислительных системах обмен умножений на сложения считается выгодным, поэтому предварительная обработка коэффициентов повышает эффективность.
Решение системы линейных алгебраических уравнений
Система 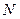 уравнений с неизвестными:
уравнений с неизвестными: 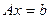 .
.
Один из способов решения СЛАУ – метод последовательной подстановки:
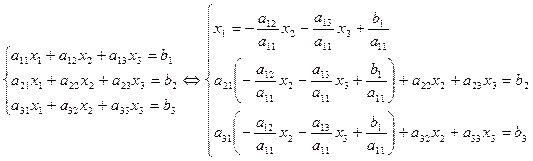
Такая процедура хорошо работает, но здесь производится очень много алгебраических преобразований, в которые легко может вкрастся ошибка. При возрастании числа уравнений и неизвестных время на выполнение этих преобразований быстро растет.
Метод Жордана-Гаусса. СЛАУ можно представить матрицей с строками и 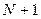 столбцами:
столбцами:
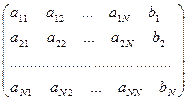
Со строками матрицы можно выполнить некоторые преобразовавния, которые приведут к следующему результату:
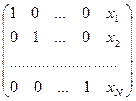 .
.
Пример.
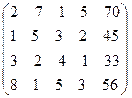 .
.
Делим первую строку на ее первый элемент, затем подбираем для нее коэффициенты таким образом, чтобы при умножении на коэффициент и сложении с ккакой-либо из оставшихся строк элементы первого столбца обнулялись
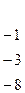
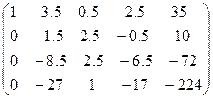 .
.
Повторим эти действия для второй строки.
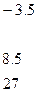
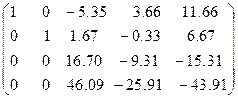
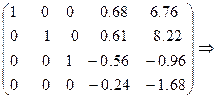
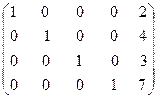
Для итерационных методов решения операций меньше, но нужно выполнить условия сходимости итерационного процесса. Рассмотрим метод простой итерации 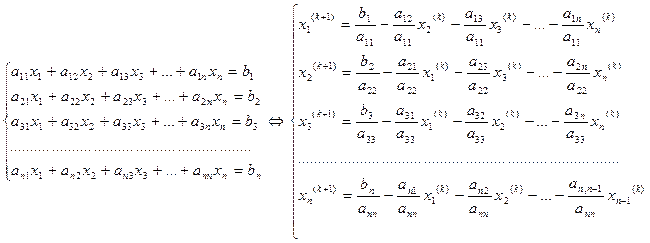
Вопросы
- Какие алгоритмы называются численными?
- Схемы вычисления значения многочлена, их сравнение, преимущества и недостатки каждой.
- Какие из арифметических операций являются предпочтительными при оценке вычислительной сложности алгоритма? Почему?
- Методы решения систем линейных алгебраических уравнений, сравнение их вычислительных сложностей.
Литература
- Деммель Дж. Вычислительная линейная алгебра / Дж.Деммель; пер.с англ. Х.Д.Икрамова. — М.: Мир, 2001. — 430 с.
- Бахвалов Н.С. Численные методы / Н.С.Бахвалов, Н.П.Жидков, Г.М.Кобельков. — М.: БИНОМ. Лаборатория знаний, 2006. — 636 с.
- Каханер Д. Численные методы и программное обеспечение / Д.Каханер, К.Моулер, С.Нэш; пер. с англ. Х.Д.Икрамова. — М.: Мир, 2001. — 575 с.
4. Воеводин В.В. Вычислительные основы линейной алгебры / В.В.Воеводин. — М.: Наука. Гл.ред.физ.-мат.лит., 1977. — 304 с.
Семестровий модуль 2. АНАЛИЗ ПОСЛЕДОВАТЕЛЬНЫХ АЛГОРИТМОВ ДЛЯ ИСПОЛЬЗОВАНИЯ В ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМАХ
Лекция 8.Граф информационной зависимости реализации алгоритма – основной способ представления алгоритма для выявления внутреннего параллелизма
План
§
Основы построения графа алгоритма
3. Допустимые преобразования алгоритма
Цели анализа последовательных алгоритмов
Появление параллельных вычислительных систем и внедрение их в практику решения больших прикладных задач привело к возникновению целого ряда проблем в области численного программного обеспечения. Построение новых численных методов для параллельных вычислительных систем процесс долговременный и сложный. Попытки разработать специальные параллельные методы не всегда оказывались состоятельными [1]. Кроме того, непростительно просто отбросить при работе на параллельных ЭВМ огромный багаж численных методов и программ, накопленный в процессе длительного использования последовательных компьютеров. Актуальны не только исследования “классических” последовательных алгоритмов для определения возможности их использования в параллельных вычислительных системах, но и сведения о параллельных свойствах алгоритмов, а также знания, позволяющие эти сведения получать.
Эффективное использование различного типа параллельных вычислительных систем возможно за счет одновременного выполнения ими ветвей вычислений, не связанных между собой информационно. Поэтому целью исследования последовательного алгоритма является поиск и выделение таких ветвей. Если они найдены, говорят, что алгоритму присущ внутренний параллелизм, и его принципиально возможно реализовать на параллельной вычислительной системе, в противном случае его использование в ней нецелесообразно.
Одной из возможных форм записи алгоритмов является их представление в виде графов (грубо говоря, любая блок-схема алгоритма также может с определенными оговорками рассматриваться как граф) [2].
Основы построения графа алгоритма
При построении графа алгоритма никаких существенных ограничений на вид переменных и операций не накладывается. Переменными могут быть числа, буквы алфавита, логические переменные, матрицы, массивы и т.д., операциями – любые арифметические, логические, матричные операции и т.п. Предполагается, что число входов и выходов (аргументов и результатов) каждой операции алгоритма в терминах выбранных переменных фиксировано и не зависит от общего числа всех операций алгоритма.
Множеству операций алгоритма, реально выполняемых при заданных входных данных, ставится во взаимно однозначное соответствие множество вершин графа. Если аргумент одной операции есть результат выполнения другой операции, то соответствующие вершины образуют ребро, направленное из той вершины, откуда берется результат.
Вершины графа, отвечающие операциям ввода (входным данным), не будут иметь входящих дуг, а операциям вывода – выходящих. При этом совсем не обязательно, чтобы одному и тому же входному данному соответствовала одна входная вершина (одна операция ввода). Число подобных операций может выбираться, исходя из конкретных условий. Аналогично с операциями вывода. В тех случаях, когда изображение графа является достаточно громоздким, возможно не изображать входные и выходные вершины, считая их положение ясным по умолчанию.
Описанный граф – граф информационной зависимости реализации алгоритма при фиксированных входных данных [Воев], который для удобства далее называется графом алгоритма.
Граф алгоритма 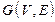 , где V — множество вершин графа, а E — множество его ребер, является ориентированным ациклическим мультиграфом (в мультиграфе не допускаются петли, но допускаются кратные ребра).
, где V — множество вершин графа, а E — множество его ребер, является ориентированным ациклическим мультиграфом (в мультиграфе не допускаются петли, но допускаются кратные ребра).
Пример 10. Необходимо вычислить значение выражения
 . (100)
. (100)
Порядок выполнения операций в правой части выражения однозначно не определен: например, произведение  можно вычислить на первом шаге, а можно после нахождения значения
можно вычислить на первом шаге, а можно после нахождения значения  . Существует и множество других вариантов, некоторые из которых представлены в следующей таблице 8.1. Операции на одном шаге могут выполняться одновременно (параллельно), сами шаги выполняются последовательно.
. Существует и множество других вариантов, некоторые из которых представлены в следующей таблице 8.1. Операции на одном шаге могут выполняться одновременно (параллельно), сами шаги выполняются последовательно.
Таблица 8.1-
Последовательность операций

Очевидно, что графы, отвечающие различным последовательностям операций для рассматриваемого примера (рис.8.1), являются изоморфными.


Рис.8.1
По существу, в (100) фиксирован не один алгоритм, а несколько математически эквивалентных.
Пример 20. Исследовать различные способы вычисления суммы
 . (150)
. (150)
В точной арифметике операция сложения обладает свойством коммутативности и ассоциативности. Очевидно, что общее число различных способов вычисления выражения (150) при больших будет очень значительным. Какой способ выбрать? С точки зрения точных вычислений все они эквивалентны. Но в условиях влияния ошибок округления появляются значительные различия. Рассмотрим две возможных реализации вычисления (150) при  :
:
- схема последовательного суммирования:
 ,
,
которой соответствует граф

 ,
,
соответствующий граф которой:

Можно показать, что схема последовательного суммирования хуже по точности, чем схема сдваивания, примерно, в  раз. Различия есть и в информационных связях между отдельными операциями. Хотя оба графа имеют одно и тоже число вершин и соответствуют одному и тому же вычисляемому выражению (150), эти графы не изоморфны (у них разные длины критических путей), перенос информации в соответствующих им схемах осуществляется принципиально различными способами. Как видно из первого графа, схема последовательного суммирования не имеет никаких параллельных ветвей вычислений. второй граф показывает наличие в схеме сдваивания большого числа информационно не связанных между собой, а значит имеющих возможность выполняться одновременно, операций.
раз. Различия есть и в информационных связях между отдельными операциями. Хотя оба графа имеют одно и тоже число вершин и соответствуют одному и тому же вычисляемому выражению (150), эти графы не изоморфны (у них разные длины критических путей), перенос информации в соответствующих им схемах осуществляется принципиально различными способами. Как видно из первого графа, схема последовательного суммирования не имеет никаких параллельных ветвей вычислений. второй граф показывает наличие в схеме сдваивания большого числа информационно не связанных между собой, а значит имеющих возможность выполняться одновременно, операций.
Замечание. Графы алгоритмов примера 10 и схемы сдваивания примера 20 очевидно являются изоморфными, хотя соответствуют решению совершенно разных задач. Алгоритмы с изоморфными графами обладают многими общими свойствами, по крайней мере, в той части, которая касается распределения информации при реализации алгоритмов (хотя призваны решать возможно совершенно разные задачи).
Замечание. Графы алгоритмов примеров 10, 20 имеют достаточно ясную и простую структуру, которая определяется не только самими алгоритмами. Во многом она зависит и от того, как конкретно на плоскости выбраны места расположения вершин. При случайном выборе расположения вершин структуру графа можно не разглядеть. Задачу выбора наилучшего расположения вершин можно пытаться решить, если число вершин невелико. При этом, возможно, придется использовать полный перебор рассматриваемых вариантов. В типичных ситуациях число операций алгоритма огромно, более того, чаще всего оно даже точно не определено и задается какими-нибудь параметрами. В этих случаях использование полного перебора вариантов для решения задачи о построении и исследовании графа алгоритма практически нереально.
3. Допустимые преобразования алгоритма
Граф алгоритма не накладывает на порядок выполнения операций никаких ограничений, кроме одного: к моменту начала реализации любой операции должны закончить свое выполнение все те операции, которые поставляют для нее аргументы. Таким образом, граф алгоритма определяет некоторое множество допустимых порядков выполнения операций, показывая, как при этом происходит распространение информации.
Утверждение 100. Пусть при выполнении операций ошибки округлений определяются только значениями аргументов операций. Тогда при одних и тех же входных данных все реализации алгоритма, соответствующие одному и тому же графу, дают один и тот же результат, включая всю совокупность ошибок округления, независимо от порядка выполнения операций [Воев].
Доказательство. Разобьем множество вершин графа алгоритма  на подмножества
на подмножества  , где
, где  содержит только входные вершины, а в вершины из множества
содержит только входные вершины, а в вершины из множества  входят дуги лишь из вершин, принадлежащих множествам
входят дуги лишь из вершин, принадлежащих множествам  . Независимо от порядка выполнения операций, каждая из вершин
. Независимо от порядка выполнения операций, каждая из вершин  даст один и тот же результат. Действительно, аргументами операций являются входные данные, эти данные не зависят от порядка выполнения операций. Результаты выполнения операций в – входные данные для
даст один и тот же результат. Действительно, аргументами операций являются входные данные, эти данные не зависят от порядка выполнения операций. Результаты выполнения операций в – входные данные для  , тогда результаты выполнения операций в не будут зависеть от порядка и т.д.
, тогда результаты выполнения операций в не будут зависеть от порядка и т.д.
Замечание 100. При реализации алгоритма либо алгоритм в целом, либо отдельные его фрагменты иногда приходится подстраивать под особенности вычислительной техники. Эта подстройка фактически означает преобразование алгоритма. Из утверждения 100 вытекает, что преобразования сохраняют уровень достоверности результатов и, следовательно, являются допустимыми, если эти преобразования сохраняют граф алгоритма.
Вопросы
1. Почему исследования “классических” последовательных алгоритмов для определения возможности их использования в параллельных вычислительных системах остаются актуальными в настоящее время?
2. Что такое внутренний параллелизм алгоритма? Любому ли алгоритму присущ внутренний параллелизм?
3. Что представляет из себя граф информационной зависимости реализации алгоритма?
4. Какие ограничения накладывает граф алгоритма на порядок выполнения операций?
5. Какие преобразования алгоритма сохраняют уровень достоверности его результатов?
Литература
1. Воеводин В.В. Параллельные вычисления / В.В.Воеводин, Вл.В.Воеводин. — СПб.: БХВ-Петербург, 2002. — 608 с.
2. Харари Ф. Теория графов / Ф.Харари; пер.с англ. В.П.Козырева. — М.: Мир, 1973. — 300 с.
3. Уилсон Р. Введение в теорию графов / Р.Уилсон. — М.: Мир, 1977. — 207 с.
4. Кристофидес Н. Теория графов. Алгоритмический подход / Н.Кристофидес. — М.: Мир, 1978. — 432 с.
5. Новиков Ф.А. Дискретная математика для программистов / Ф.А.Новиков. — СПб.: Питер, 2006. — 364 с.
6. Иванов Б.Н. Дискретная математика. Алгоритмы и программы / Б.Н.Иванов. — М.: Лаборатория Базовых Знаний, 2001. — 288с.
Лекция 9. Топологическая сортировка графа
План
§
Утверждение 111 показывает, что вершины графа любого алгоритма можно разбить, по крайней мере, на три группы. Первая группа содержит не менее одной входной вершины, третья – не менее одной выходной вершины. Вторая группа – все остальные вершины. Соответствующие группы операций алгоритма могут быть выполнены последовательно друг за другом. Наибольший интерес с точки зрения анализа алгоритма вызывает вторая группа.
Утверждение 123. Пусть задан ориентированный ациклический граф, имеющий вершин. Существует натуральное число 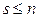 , для которого все вершины графа можно так пометить одним из индексов
, для которого все вершины графа можно так пометить одним из индексов 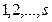 , что если дуга идет из вершины с индексом
, что если дуга идет из вершины с индексом  в вершину с индексом
в вершину с индексом 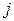 , то
, то  [Воев].
[Воев].
Доказательство. Выберем в графе любое число входных вершин и пометим их индексом 1. Удалим из графа помеченные вершины и инцидентные им ребра. Оставшийся граф также ориентированный и ациклический. Выберем в нем любое число входных вершин (в соответствии с утверждением 111 хотя бы одна такая вершина есть) и пометим их индексом 2. Снова удалим помеченные вершины и инцидентные им ребра. Продолжим этот процесс, пока не исчерпаем весь граф. Так как при каждом помечивании помечается не менее одной вершины, то число различных индексов не превышает числа вершин.
Следствие 1. Никакие две вершины с одинаковыми индексами не являются смежными.
Следствие 2. Минимальное число индексов, которыми можно пометить все вершины графа, на 1 больше длины его критического пути.
Следствие 3. Для любого натурального числа , большего длины критического пути, существует такая разметка вершин графа, при которой используются все 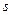 индексов.
индексов.
Разметка вершин графа, проведенная в соответствии с утверждением 123, называется топологической сортировкой, а вершины, помеченные одним индексом, образуют топологический уровень.
Если при топологической сортировке графа некоторая вершина помечена индексом  , то длина всех путей, оканчивающихся в этой вершине, меньше .
, то длина всех путей, оканчивающихся в этой вершине, меньше .
Пример. Построить топологическую сортировку графа  (рис.9.1(а)). На рис.9.1(б-к) отражены последовательные шаги построения сортировки в соответствии с доказательством утверждения 123. В результате получено разбиение множества вершин графа на следующие топологические уровни:
(рис.9.1(а)). На рис.9.1(б-к) отражены последовательные шаги построения сортировки в соответствии с доказательством утверждения 123. В результате получено разбиение множества вершин графа на следующие топологические уровни:
| Номер топологического уровня | Вершины графа |
| 1, 2 | |
| 3, 4, 5 | |
| 6, 8 | |
| 7, 10 | |
| 14, 15 |
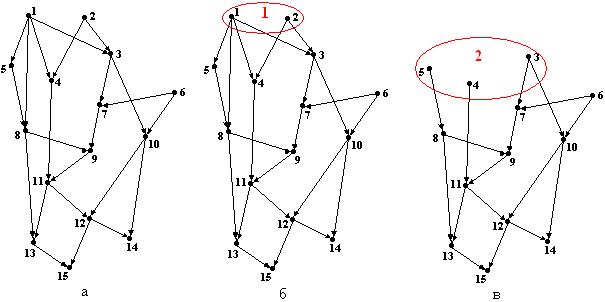


Рис.9.1. Исходный граф (а), последовательные шаги построения топологической сортировки (б-к)
Если на каждом шаге построения топологической сортировки помечать все возможные вершины, то количество уровней будет минимальным и равным 7 (рис.9.2) (сравнить с длиной критического пути графа, которая равна 6), при этом разбиение множества вершин графа на топологические уровни будет иметь следующий вид:
| Номер топологического уровня | Вершины графа |
| 1, 2, 6 | |
| 3, 4, 5 | |
| 7, 8, 10 | |
| 12, 13 | |
| 14, 15 |
Таким образом, каждому графу может соответствовать множество различных топологических сортировок.

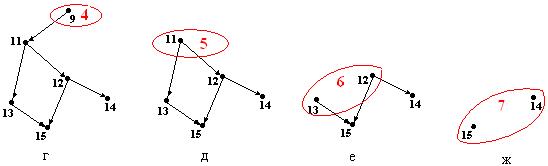
рис.9.2. Топологическая сортировка графа, содержащая минимальное количество уровней
Замечание 1000. Утверждение 123 остается в силе, если неравенство заменить неравенством  , однако ни одно из следствий уже выполняться не будет. Такая разметка вершин графа называется обобщенной топологической сортировкой.
, однако ни одно из следствий уже выполняться не будет. Такая разметка вершин графа называется обобщенной топологической сортировкой.
Обобщенная топологическая сортировка является удобным промежуточным объектом в процессе отыскания нужной топологической сортировки. Если найдена нетривиальная обобщенная топологическая сортировка, то для нахождения топологической сортировки не обязательно снова рассматривать весь граф. Довольно часто могут быть получены хорошие результаты, если отыскать подходящие топологические сортировки для подграфов, определяемых группами вершин обобщенной топологической сортировки, и из них составить топологическую сортировку исходного графа, используя предложенный ниже алгоритм построения топологической сортировки объединения графов Ниже обязательно привести пример.
Топологическая сортировка называется линейной, если индексы любых вершин различны. В этом случае говорят, что граф линейно упорядочен. Если топологическая сортировка (или обощенная топологическая сортировка) не являются линейными, то из нее легко получить другие сортировки с бóльшим числом индексов.
§
Как правило, чем сложнее устроен граф, чем больше его размерность, тем труднее построить его топологическую сортировку, тем больше времени занимает процесс его предобработки.
Предлагается алгоритм построения топологической сортировки графа алгоритма по сортировкам подграфов его разбиения; приводятся результаты вычислительного эксперимента, дающие возможность сравнить предлагаемый алгоритм с используемым ранее непосредственным построением топологической сортировки графа большой размерности [Воев].
Пусть граф  является сложным для исследования и обработки в силу своей размерности или других причин, некоторые из которых уже указаны. Разложим граф на подграфы. Построим разбиение
является сложным для исследования и обработки в силу своей размерности или других причин, некоторые из которых уже указаны. Разложим граф на подграфы. Построим разбиение  множества вершин :
множества вершин :  Ø, для
Ø, для 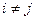 .Каждое подмножество
.Каждое подмножество  , определяет порожденный подграф
, определяет порожденный подграф  графа
графа  . Для любого множества
. Для любого множества  порожденным подграфом называется максимальный подгаф графа , множеством вершин которого является
порожденным подграфом называется максимальный подгаф графа , множеством вершин которого является  . Построение сортировки графа проведем на основе сортировок подграфов . Заметим, что
. Построение сортировки графа проведем на основе сортировок подграфов . Заметим, что  , поскольку при выделении подграфов , происходит потеря ребер, инцидентных вершинам из разных подмножеств . Вследствие такой потери разрываются связи между вершинами графа , проход по которым может определить топологический индекс вершины. Отметим, что связный граф невозможно разбить на непересекающиеся подграфы, объединение которых давало бы исходный. Например,
, поскольку при выделении подграфов , происходит потеря ребер, инцидентных вершинам из разных подмножеств . Вследствие такой потери разрываются связи между вершинами графа , проход по которым может определить топологический индекс вершины. Отметим, что связный граф невозможно разбить на непересекающиеся подграфы, объединение которых давало бы исходный. Например,  (рис.1), т.к. объединение не содержит ребро
(рис.1), т.к. объединение не содержит ребро  , а значит при построении топологической сортировки графа по топологическим сортировкам
, а значит при построении топологической сортировки графа по топологическим сортировкам  ,
,  не учитывается возможность получения
не учитывается возможность получения  вершинами исходного графа с индексами 5 и 6 топологических номеров по цепочке 1, 5, 6.
вершинами исходного графа с индексами 5 и 6 топологических номеров по цепочке 1, 5, 6.
Возникновение подобных ситуаций делает принципиально невозможным получение топологической сортировки графа , по сортировкам его подграфов, порождаемых разбиением множества вершин .
Определение 1. Множество

называется
множеством теряемых ребер графа при разбиении  множества .
множества .
 Определение 2. Вершины графа , являющиеся концевыми вершинами теряемых ребер, называются граничными вершинами.
Определение 2. Вершины графа , являющиеся концевыми вершинами теряемых ребер, называются граничными вершинами.
Во избежание потери ребер при разбиении графа заменим каждый его порожденный подграф  на другой порожденный подграф
на другой порожденный подграф  , где множество
, где множество  содержит вершины, входящие в , и дополнительно граничные вершины графа , каждая из которых смежна хотя бы с одной вершиной из множества . Полученная новая система порожденных подграфов, очевидно, обладает свойством:
содержит вершины, входящие в , и дополнительно граничные вершины графа , каждая из которых смежна хотя бы с одной вершиной из множества . Полученная новая система порожденных подграфов, очевидно, обладает свойством:

но пересечение этих подграфов не обязательно равно Ø. Например, для графа ,(см. рис.10.3) можно построить систему подграфов 
 . Построим сортировки наименьшей длины для каждого подграфа в отдельности, при этом каким-либо образом пометив граничные вершины. Без ограничения общности рассуждений, принимается, что запись каждого топологического уровня сортировки содержит сначала индексы всех вершин, не являющихся граничными, а если присутствуют граничные вершины, их индексы завершают запись. Такие топологические сортировки будут иметь минимальное количество уровней, равное длине критического пути подграфа плюс единица (следствие 2 утверждения 123).
. Построим сортировки наименьшей длины для каждого подграфа в отдельности, при этом каким-либо образом пометив граничные вершины. Без ограничения общности рассуждений, принимается, что запись каждого топологического уровня сортировки содержит сначала индексы всех вершин, не являющихся граничными, а если присутствуют граничные вершины, их индексы завершают запись. Такие топологические сортировки будут иметь минимальное количество уровней, равное длине критического пути подграфа плюс единица (следствие 2 утверждения 123).
При построении сортировки произвольного графа для простоты изложения предположим, что количество определенных выше порожденных подграфов равно двум:  ,
,  , а
, а  — их топологические сортировки, представляющие массивы, в которых последовательно выписаны топологические уровни, начиная с первого. Обозначим
— их топологические сортировки, представляющие массивы, в которых последовательно выписаны топологические уровни, начиная с первого. Обозначим  ,
, 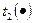 — топологические номера вершины в
— топологические номера вершины в  ,
,  соответственно,
соответственно,  — топологический номер граничной вершины в результирующей сортировке графа ,
— топологический номер граничной вершины в результирующей сортировке графа , , — корректировочные разности для
, — корректировочные разности для  . Корректировочной разностью подграфа , назовем разность между топологическим индексом вершины в сортировке
. Корректировочной разностью подграфа , назовем разность между топологическим индексом вершины в сортировке  и ее индексом в сортировке .
и ее индексом в сортировке .
Предлагаемый алгоритм содержит следующие основные этапы:
— инициализуются значения корректировочных разностей для подграфов  , и определяется порядок просмотра топологических сортировок:
, и определяется порядок просмотра топологических сортировок:  ;
;  ;
;  ;
;
— последовательный просмотр топологической сортировки .
Пусть  — индекс очередной вершины в сортировке .
— индекс очередной вершины в сортировке .
Если индекс соответствует неграничной вершине,
то
 =
=  , возврат в начало этапа;
, возврат в начало этапа;
иначе —
переход на следующий этап;
— последовательный просмотр топологической сортировки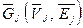 .
.
Пусть  — индекс очередной вершины в сортировке .
— индекс очередной вершины в сортировке .
Если индекс соответствует неграничной вершине,
то
 =
=  , возврат в начало этапа;
, возврат в начало этапа;
иначе —
М:если  ,
,
то
 ;обновление корректировочных разностей:
;обновление корректировочных разностей:
 ;
;  ; переход на предыдущий
; переход на предыдущий
этап;
если  ,
,
то
если в пределах рассматриваемого топологического уровня
существует такая граничная вершина с индексом
 , что
, что  ,
,
то
вывести вершину с индексом на первое место в списке
граничных вершин данного топологического уровня;
переход на метку М;
иначе —
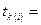 (
(  )- ,
)- ,
 ;
;  ; переход на
; переход на
предыдущий этап.
Обобщение предложенного алгоритма на граф с большим числом подграфов не вызывает труда: для присвоения окончательного топологического номера каждой граничной вершине необходимо будет исследовать не два, а более подграфов, что потребует и большего общего количества арифметических операций. Таким образом, можно ожидать, что эффективность предложенного алгоритма будет зависеть от числа подграфов, а наибольший выигрыш во времени по сравнению с непосредственным построением топологической сортировки исходного графа, очевидно, будет наблюдаться, когда количество подграфов минимально (два, три), что и подтверждается результатами проведенного вычислительного эксперимента.
В вычислительном эксперименте исследовалась эффективность с точки зрения временных затрат предложенного алгоритма построения топологической сортировки графа по топологическим сортировкам его подграфов по сравнению с непосредственным построением сортировки графа. Эксперимент проводился на графах различных по структуре последовательных алгоритмов. При этом изменялась размерность и количество подграфов, на которые разбивался граф. При проведении эксперимента фиксировалась размерность графа, начиная с которой новый алгоритм работал быстрее. Представлены примеры некоторых графов небольшой размерности (рис.10.4).
Из полученных результатов вычислительного эксперимента, проведенного в среде MATLAB (табл.10.1), очевидно, что даже при сравнительно небольшом количестве вершин графа построение его топологической сортировки по топологическим сортировкам его подграфов происходит быстрее, чем непосредственное построение топологической сортировки всего графа. Это количество вершин фиксировалось, как только преимущество во времени достигало порядка  с. С увеличением размерности графа преимущество возрастает. Например, для графа 1, количество вершин которого равно 250, а количество подграфов равно двум, время построения сортировки по предложенному алгоритму уже на 5 с меньше, чем при использовании алгоритма непосредственного построения топологической сортировки всего графа в целом. Кроме того, как следует из результатов эксперимента, чем больше количество подграфов разбиения графа, тем при большей его размерности достигается преимущество во времени по сравнению с построением топологической сортировки целого графа, как и предполагалось ранее.
с. С увеличением размерности графа преимущество возрастает. Например, для графа 1, количество вершин которого равно 250, а количество подграфов равно двум, время построения сортировки по предложенному алгоритму уже на 5 с меньше, чем при использовании алгоритма непосредственного построения топологической сортировки всего графа в целом. Кроме того, как следует из результатов эксперимента, чем больше количество подграфов разбиения графа, тем при большей его размерности достигается преимущество во времени по сравнению с построением топологической сортировки целого графа, как и предполагалось ранее.

Рис.10.4. Примеры используемых графов
При проведении вычислительного эксперимента отмечено, что эффективность построения топологической сортировки графа по топологическим сортировкам его подграфов в значительной степени зависит от способа его разбиения на подграфы. При разбиении следует стремиться к минимальному количеству теряемых ребер, а не равному количеству вершин в подграфах.
Таблица 10.1 –
Результаты вычислительного эксперимента
| Граф | Кол-во подграфов | Кол-во вершин в подграфах | Количество вершин графа, начиная с которого достигается преимущество предложенного алгоритма по времени |
| 96 / 105 | |||
| 97 / 92 / 101 | |||
| 122 / 76 / 62 / 60 | |||
| 256 / 257 | |||
| 161 / 161 / 161 / 160 | |||
| 176 / 175 | |||
| 139 / 138 / 139 / 138 | |||
| 105 / 296 | |||
| 150 / 173 / 177 | |||
| 288 / 289 | |||
| 217 / 218 / 216 | |||
| 177 / 177 / 178 / 178 | |||
| 98 / 139 | |||
| 102 / 128 / 96 / 133 |
Предложенный алгоритм построения топологической сортировки графов позволяет проводить это построение на графах большой размерности быстрее, чем алгоритм, основывающийся на непосредственной обработке графа, поэтому исследование графов реальных последовательных алгоритмов, размерность которых, как правило, велика, с целью их распараллеливания имеет смысл проводить с помощью разработанного алгоритма.
Вопросы
1. Когда возникает семейство «похожих» алгоритмов?
2. Всегда ли можно точно построить граф алгоритма, содержащего условные операции? Почему?
3. Можно ли по имеющейся топологической сортировке графа получить топологические сортировки его подграфов? Как это сделать? Когда возникает такая необходимость? Привести пример.
4. Что назыв ется множеством теряемых ребер графа, когда это множество возникает? Привести примеры.
5. Какие вершины графа называются граничными вершинами? Привести примеры.
6. Написать программу, реализующую алгоритм построения топологической сортировки объединения двух графов по имеющимся топологическим сортировкам этих графов.
Литература
1. Воеводин В.В. Параллельные вычисления / В.В.Воеводин, Вл.В.Воеводин. — СПб.: БХВ-Петербург, 2002. — 608 с.
2. Харари Ф. Теория графов / Ф.Харари; пер.с англ. В.П.Козырева. — М.: Мир, 1973. — 300 с.
3. Уилсон Р. Введение в теорию графов / Р.Уилсон. — М.: Мир, 1977. — 207 с.
4. Кристофидес Н. Теория графов. Алгоритмический подход / Н.Кристофидес. — М.: Мир, 1978. — 432 с.
5. Новиков Ф.А. Дискретная математика для программистов / Ф.А.Новиков. — СПб.: Питер, 2006. — 364 с.
6. Иванов Б.Н. Дискретная математика. Алгоритмы и программы / Б.Н.Иванов. — М.: Лаборатория Базовых Знаний, 2001. — 288с.
7. Кобозева А.А., Нариманова Е.В. Метод построения топологической сортировки объединения графов, используемый при распараллеливании последовательных алгоритмов / Труды Одесского политехнического университета. – 2006. – №2(26). – С. 156-161.
Лекция 11. Использование операций гомоморфизма при построении топологических сортировок графов
План
§
В процессе длительного использования последовательных компьютеров был накоплен и тщательно отработан огромный багаж численных алгоритмов и программ. Появление параллельных компьютеров вроде бы должно было привести к массовому созданию новых методов. Но этого не произошло [Воеводин]. Попытка разработать специальные параллельные методы, в частности, методы малой высоты, оказалась на практике несостоятельной. Как использовать старый алгоритмический и программный багаж на параллельных компьютерах?
Возьмем любой алгоритм, записанный в виде математических соотношений, последовательных программ или каким-либо иным способом. Допустим, что по этой записи для него удалось построить граф алгоритма. Предположим, что для этого графа обнаружена параллельная форма с достаточной шириной ярусов. Тогда рассматриваемый алгоритм принципиально можно реализовать на параллельном компьютере. Очень важно, что параллельная реализация алгоритма будет иметь такие же вычислительные свойства, как и любая другая [Воеводин]. В частности, если исходный алгоритм был численно устойчив, то он останется таким и в параллельной форме. Подобный параллелизм в алгоритмах называется внутренним.
В старых, давно используемых и хорошо отработанных алгоритмах довольно часто удается обнаружить хороший запас внутреннего параллелизма.
Использование внутреннего параллелизма имеет
· достоинство: не нужно тратить дополнительные усилия на изучение вычислительных свойств вновь создаваемых алгоритмов;
· недостатки: необходимость определять и исследовать графы алгоритмов.
В тех случаях, когда внутреннего параллелизма какого-либо алгоритма недостаточно для эффективного использования конкретного параллельного компьютера, приходится заменять его другим алгоритмом, имеющим лучшие свойства параллелизма. Для многих задач разработано большое количество различных алгоритмов, поэтому выбрать подходящий алгоритм почти всегда удается. Однако осуществить этот выбор не легко, т.к. нужно знать параллельную структуру алгоритмов. В силу этого чрезвычайно актуальными являются сведения о параллельных свойствах алгоритмов, а также знания, позволяющие эти сведения получать.
Пример. Необходимо вычислить произведение
 ,
,
где  –
–  -матрицы с элементами
-матрицы с элементами  соответственно. Элементы матрицы будем обозначать
соответственно. Элементы матрицы будем обозначать  :
:
 . (25)
. (25)
Формула (25) не определяет алгоритм вычисления элементов матрицы однозначно, т.к. не определен порядок суммирования произведений  . Отсутствие указания о соблюдении какого-либо порядка перебора индексов
. Отсутствие указания о соблюдении какого-либо порядка перебора индексов  говорит о возможном параллелизме вычислений.
говорит о возможном параллелизме вычислений.
Допустим, что выбран следующий алгоритм реализации (25):
 (35)
(35)
Построим граф алгорима (35). Будем считать, что вершины графа соответствуют операциям вида  . При построении графа не будем сначала показывать вершины и инцидентные им дуги, связанные с вводом элементов матриц и с присвоением элементам матрицы вычисленных значений
. При построении графа не будем сначала показывать вершины и инцидентные им дуги, связанные с вводом элементов матриц и с присвоением элементам матрицы вычисленных значений  Чтобы не вносить в исследование графа алгоритма дополнительные трудности, вершины графа нельзя располагать произвольно. Рассмотрим прямоугольную решетку в трехмерном пространстве с координатами
Чтобы не вносить в исследование графа алгоритма дополнительные трудности, вершины графа нельзя располагать произвольно. Рассмотрим прямоугольную решетку в трехмерном пространстве с координатами  . Во все целочисленные узлы решетки для
. Во все целочисленные узлы решетки для  поместим вершины графа. Анализируя (35), видно, что в вершину с координатами для
поместим вершины графа. Анализируя (35), видно, что в вершину с координатами для  будет передаваться результат выполнения операции, соответствующей вершине с координатами
будет передаваться результат выполнения операции, соответствующей вершине с координатами  .
.
Граф алгоритма распадается на  не связанных между собой подграфов. Каждый подграф содержит
не связанных между собой подграфов. Каждый подграф содержит  вершин и представляет один путь, расположенный параллельно оси
вершин и представляет один путь, расположенный параллельно оси  . Для
. Для  граф алгоритма представлен на рис. 12.1(а). В полном графе имеется множественная рассылка данных. Элемент
граф алгоритма представлен на рис. 12.1(а). В полном графе имеется множественная рассылка данных. Элемент  рассылается по всем вершинам, имеющим те же самые значения координат
рассылается по всем вершинам, имеющим те же самые значения координат  . Элемент
. Элемент  рассылается по всем вершинам, имеющим те же самые координаты
рассылается по всем вершинам, имеющим те же самые координаты  . Для все рассылки учтены на рис. 12.1(б).
. Для все рассылки учтены на рис. 12.1(б).
Этот пример хорошо иллюстрирует, насколько важно правильно выбрать расположение вершин графа алгоритма. Если, например, расположить вершины на прямой без какой-либо связи с индексами , то вряд ли в таком графе удалось бы разглядеть параллелизм. При выбранном расположении вершин параллелизм очевиден. Легко описать любой ярус любой параллельной формы.
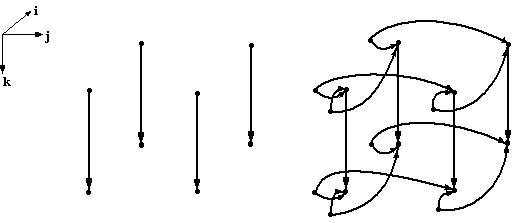
Рис. 12.1
§
Один из самых простых способов введения системы координат связан с простым перечислением всех операций, т.е. с линейным упорядочением вершин графа алгоритма.
При сохранении уровня достоверности результатов самой важной характеристикой процесса реализации алгоритма является время его выполнения. Если алгоритм реализуется каким-либо образом на какой-нибудь реальной или гипотетической, последоватьельной или параллельной вычислительной системе, то тем самым определяются моменты выполнения всех операций этого алгоритма. Перенумеруем вершины графа алгоритма любым способом и обозначим через  время окончания процесса реализации операции, соответствующего і-ой вершине. Таким образом, с каждой реальной или гипотетической реализацией алгоритма можно связать вектор
время окончания процесса реализации операции, соответствующего і-ой вершине. Таким образом, с каждой реальной или гипотетической реализацией алгоритма можно связать вектор  , который показывает, как протекает процесс реализации во времени.
, который показывает, как протекает процесс реализации во времени.
Сам по себе вектор не содержит никакой информации о характеристиках используемой вычислительной системы. Поэтому, если при этом координаты вектора оказываются связанными какими-нибудь ограничениями, то такие ограничения определяются исключительно графом алгоритма. В данном случае вектор будем называть вектором обобщенной временной развертки. Поскольку на реализующую алгоритм вычислительную систему не накладываются никакие ограничения, время выполнения любой операции может равняться нулю или быть сколь угодно малым.
Если при рассмотрении вектора принимаются во внимание хотя бы какие-нибудь параметры вычислительной системы, влияющие на допустимое множество векторов , то в этом случае вектор будем называть просто вектором временной развертки. Например, может задаваться время  , необходимое для реализации
, необходимое для реализации  ой операции. Если из
ой операции. Если из  ой вершины графа алгоритма идет дуга в ую вершину, то должно выполняться неравенство:
ой вершины графа алгоритма идет дуга в ую вершину, то должно выполняться неравенство:  . Поэтому параметр влияет на множество допустимых векторов временных разверток. Неотрицательный вектор
. Поэтому параметр влияет на множество допустимых векторов временных разверток. Неотрицательный вектор  будем называть вектором реализации. Для обобщенных временных разверток
будем называть вектором реализации. Для обобщенных временных разверток  .
.
Если из ой вершины графа алгоритма идет дуга в ую вершину, то этому факту можнодать следующую трактовку. Некоторая информация рождается в ой вершине в момент и передается ой вершине для использования. В какой-то момент времени между и  эта информация начинает использоваться устройством, относящимся к ой вершине, и ее использование заканчивается в момент . Следовательно, с каждой дугой графа можно связать не только какую-то информацию, передаваемую от одной вершины к другой. Любая временная развертка однозначно определяет время ее появления и время – ее существования, частично в неизменном, частичнов преобразованном в ой вершине виде. Будем считать, что в момент старая информация полностью заканчивает свое существование и рождается новая. Если в момент одна и та же информация начинает распространяться одновременно по нескольким дугам, то будем предполагать, что на каждой дуге возможна ее самостоятельная жизнь со своими процессами передачи и преобразования.
эта информация начинает использоваться устройством, относящимся к ой вершине, и ее использование заканчивается в момент . Следовательно, с каждой дугой графа можно связать не только какую-то информацию, передаваемую от одной вершины к другой. Любая временная развертка однозначно определяет время ее появления и время – ее существования, частично в неизменном, частичнов преобразованном в ой вершине виде. Будем считать, что в момент старая информация полностью заканчивает свое существование и рождается новая. Если в момент одна и та же информация начинает распространяться одновременно по нескольким дугам, то будем предполагать, что на каждой дуге возможна ее самостоятельная жизнь со своими процессами передачи и преобразования.
Время – будем называть временем задержки информации на дуге, связывающей ую и ую вершины, при временной развертке . Обобщенная временная развертка не накладывает никаких ограничений на времена задержек, кроме того, что они должны быть неотрицательными. Это ограничение есть необходимое условие выполнимости алгоритма. При реализации алгоритмов на реальных вычислительных машинах или системах на времена задержек накладываются ограничения снизу. Они вызываются временем реализации операции, временем передачи информации по каналам и линиям связи, временем хранения в памяти и рядом других факторов. Эти ограничения можно задавать аксиоматически и считать, например, что для всех  и
и  время задержки информации на дуге, связывающей ую и ую вершины, удовлетворяет –
время задержки информации на дуге, связывающей ую и ую вершины, удовлетворяет –  . Неотрицательный вектор с координатами
. Неотрицательный вектор с координатами  будем называть вектором задержек.
будем называть вектором задержек.
Рассмотрим временные ограничения, возникающие в процессе ввода-вывода информации. Обозначим через  вектор, координатами которого являются координаты вектора развертки , соответствующие входным вершинам. Задача может состоять в изучении множества разверток, удовлетворяющих дополнительным ограничениям вида
вектор, координатами которого являются координаты вектора развертки , соответствующие входным вершинам. Задача может состоять в изучении множества разверток, удовлетворяющих дополнительным ограничениям вида 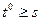 , где – заданный вектор, неравенство между векторами означает систему неравенств между соответствующими их координатами. Это говорит о том, что исследуются временные характеристики процессов реализации алгоритмов при условии, что заданы ограничения на моменты ввода информации. Вектор называется вектором граничных или начальных условий.
, где – заданный вектор, неравенство между векторами означает систему неравенств между соответствующими их координатами. Это говорит о том, что исследуются временные характеристики процессов реализации алгоритмов при условии, что заданы ограничения на моменты ввода информации. Вектор называется вектором граничных или начальных условий.
Пусть фиксирован алгоритм и определен его граф. Обозначим через множество всех обощенных временных разверток для этого алгоритма. Через  обозначим множество всех существующих и не существующих, реальных и гипотетических вычислительных систем, на которых алгоритм может быть реализован. Ясно, что любая конкретная ЭВМ входит во множество и этой ЭВМ соответствует во множестве некоторое подмножество, описывающее все возможные реализации на ней заданного алгоритма.
обозначим множество всех существующих и не существующих, реальных и гипотетических вычислительных систем, на которых алгоритм может быть реализован. Ясно, что любая конкретная ЭВМ входит во множество и этой ЭВМ соответствует во множестве некоторое подмножество, описывающее все возможные реализации на ней заданного алгоритма.
Если определены какие-то ограничения на параметры вычислительных систем, то тем самым определяется во множестве какое-то подмножество временных разверток. Например, задание вектора  или определяет подмножества
или определяет подмножества  или
или 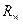 . В свою очередь в подмножествах , выделяются подмножества в зависимости от векторов начальных условий. Возможны и другие ограничения. Ясно, что в рассмотренных случаях ,
. В свою очередь в подмножествах , выделяются подмножества в зависимости от векторов начальных условий. Возможны и другие ограничения. Ясно, что в рассмотренных случаях ,  , а также =
, а также =  для некоторого вектора
для некоторого вектора  , выбираемого по вектору . Все эти множества и подмножества зависят от рассматриваемого алгоритма.
, выбираемого по вектору . Все эти множества и подмножества зависят от рассматриваемого алгоритма.
Время реализации алгоритма
Одной из важнейших характеристик, определяющих эффективность алгоритма, является время его реализации на вычислительной системе. Конечно, это время зависит не только от алгоритма, но и от структуры и временных характеристик вычислительной системы.
Алгоритмы, считавшиеся эффективными на однопроцессорных ЭВМ, нередко становятся очень неэффективными на многопроцессорных системах.
Как оценивать время реализации алгоритма? Очевидно, что прямое его измерение на конкретной ЭВМ дает возможность сравнивавть временные характеристики различных алгоритмов только по отношению к данной ЭВМ. По отношению к другой ЭВМ аналогичное сравнение, вообще говоря, дает другие результаты. Поэтому необходимо абстрагироваться от вычислительной системы. Для однопроцессорных ЭВМ это происходит за счет сравнения количества арифметических операций. Формально можно считать, что число операций – это время реализации алгоритма на абстрактной однопроцессорной машине, у которой время реализации любой операции равно 1, а время выполнения всех других процедур (ввод-вывод данных, взаимодействие с памятью, передача данных по каналам связи и т.п.) равно 0. При этом предполагается, что операции выполняются подряд без какого-либо простоя в работе ЭВМ.
Как было показано на примерах, сравнение времен реализации алгоритмов по числу операций становится неприемлемым, если реализацию алгоритмов проводить на параллельных вычислительных системах. Поэтому и абстрактная последовательная ЭВМ, используемая для сравнения времен реализации алгоритмов, также оказыванется неприемлемой для этой цели. Теперь в качестве подходящей модельной вычислительной системы выступает граф-машина.
Есть одно принципиальное отличие между абстрактной последовательной ЭВМ и граф-машиной. Именно, на первой реализуются все алгоритимы, на второй – только один.
Будем исследовать множество временных разверток , определяемым временем задержек , поскольку частным выбором векторов можно описать развертки других типов. Например,  определяет совокупность обобщенных временных разверток. Задание вектора реализации также эквивалентно заданию некоторого вектора . При этом основной целью является изучение в точек минимума функционала времени реализации алгоритма.
определяет совокупность обобщенных временных разверток. Задание вектора реализации также эквивалентно заданию некоторого вектора . При этом основной целью является изучение в точек минимума функционала времени реализации алгоритма.
Вопросы
1. Можно ли любой ориентированный ациклический граф считать графом некоторого алгоритма? Почему?
2. Как должны соотносится между собой время работы алгоритма и время, которое затрачивается на его анализ?
3. В чем состоит основная проблема анализа алгоритмов при помощи соответствующих им графов?
4. Что представляет из себя вектор обобщенной временной развертки, чем он отличается от вектора временной развертки?
5. Что такое вектор реализации алгоритма? Когда вектор реализации нулевой?
6. Как временная развертка определяет время появления и время существования информации?
7. Как определяется время задержки информации на дуге? Определение вектора задержек.
8. Какие временные ограничения возникают в процессе ввода-вывода информации? Как формируется вектор начальных условий?
9. Как связаны между собой , , ? Пояснить.
10. От чего зависит время реализации алгоритма на вычислительной системе?
11. Есть ли прямая связь между эффективностью алгоритма на однопроцессорных ЭВМ и многопроцессорных системах? Пояснить.
Литература
1. Воеводин В.В. Параллельные вычисления / В.В.Воеводин, Вл.В.Воеводин. — СПб.: БХВ-Петербург, 2002. — 608 с.
2. Харари Ф. Теория графов / Ф.Харари; пер.с англ. В.П.Козырева. — М.: Мир, 1973. — 300 с.
3. Уилсон Р. Введение в теорию графов / Р.Уилсон. — М.: Мир, 1977. — 207 с.
4. Кристофидес Н. Теория графов. Алгоритмический подход / Н.Кристофидес. — М.: Мир, 1978. — 432 с.
5. Новиков Ф.А. Дискретная математика для программистов / Ф.А.Новиков. — СПб.: Питер, 2006. — 364 с.
6. Иванов Б.Н. Дискретная математика. Алгоритмы и программы / Б.Н.Иванов. — М.: Лаборатория Базовых Знаний, 2001. — 288с.
§
Утверждение 3.При фиксированном векторе задержек множество временных разверток обладает следующими свойствами:
Пусть векторы , являются временными развертками для вектора задержек . Тогда:
 –
– 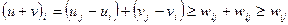 ,
,
Следовательно  .
.
 ,
,
Следовательно 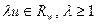 .
.
Для любого  имеем:
имеем:
 ,
,
Т.е. вектор  , – выпукло.
, – выпукло.
При фиксированном ненулевом векторе задержек множество временных разверток не является конусом. Однако при любом развертки из входят во множество  . Несмотря на то, что множество содержит в себе все множества , само оно, в свою очередь, содержится в некотором смысле в каждом .
. Несмотря на то, что множество содержит в себе все множества , само оно, в свою очередь, содержится в некотором смысле в каждом .
Утверждение 4.Пусть – какая-нибудь фиксированная временная развертка из . Тогда для любой обобщенной временной развертки вектор 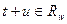 .
.
Действительно: – ,  –
– 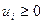 для всех подходящих пар . Тогда
для всех подходящих пар . Тогда
 –
– 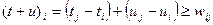 .
.
Таким образом, конус обобщенных временных разверток , сдвинутый параллельно на любую развертку из , содержится в при любом .
Надо выяснить, когда множества и совпадают с точностью до параллельного переноса.
Утверждение 5.Пусть СЛАУ
 –
–  (3)
(3)
совместна и вектор  является ее решением. Тогда множества и совпадают с точностью до параллельного переноса на вектор .
является ее решением. Тогда множества и совпадают с точностью до параллельного переноса на вектор .
Действительно, 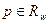 . Тогда в силу утверждения 4, множество , сдвинутое на вектор , содержится в . Остается показать, что любую развертку из можно представить, как некоторую обобщенную развертку из , сдвинутую на вектор . Пусть – произвольная развертка из ,
. Тогда в силу утверждения 4, множество , сдвинутое на вектор , содержится в . Остается показать, что любую развертку из можно представить, как некоторую обобщенную развертку из , сдвинутую на вектор . Пусть – произвольная развертка из , 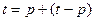 . Рассмотрим вектор
. Рассмотрим вектор  . Имеем – . Вычитая отсюда (3), получим
. Имеем – . Вычитая отсюда (3), получим  –
– 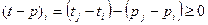 , т.е.
, т.е.  .
.
Совместимость (3) дает достаточное условие совпадения и . Какие необходимые условия? Предположим, что множество получается из множества с помощью параллельного переноса на вектор . Чем характерна временная развертка ?
Какова бы ни была развертка 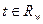 , она получается как сумма развертки из и , тогда вектор
, она получается как сумма развертки из и , тогда вектор  является обобщенной временной разверткой. Пусть дуга идет из в . Т.к. – замкнутое, то при фиксированных и существует развертка, на которой величина – достигает в своего минимального значения. В силу того, что вектор является обобщенной временной разверткой, выполняется
является обобщенной временной разверткой. Пусть дуга идет из в . Т.к. – замкнутое, то при фиксированных и существует развертка, на которой величина – достигает в своего минимального значения. В силу того, что вектор является обобщенной временной разверткой, выполняется 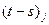 –
– 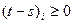 . Отсюда вытекает
. Отсюда вытекает 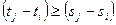 . Это означает, что имеет место
. Это означает, что имеет место
Утверждение 6.Пусть множество получается из множества с помощью параллельного переноса на вектор . Тогда для любых пар , , соответствующих дугам графа алгоритма, минимальное значение – для всех разверток равно 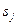 – .
– .
Таким образом, координаты развертки обеспечивают наилучшее удовлетворение неравенств (1), максимально приближая каждое из них к равенству. При совместимости СЛАУ (3) все неравенства (1) становятся на развертке равенствами.
Вопросы
1. Сформулировать критерий того, что вектор является вектором временной развертки, соответствующим вектору .
2. Как связана временная развертка для суммы векторов задержек с временными развертками слагаемых? Показать.
3. Как связана временная развертка для для вектора задержек  с временной разверткой для вектора задержек
с временной разверткой для вектора задержек  ? Показать.
? Показать.
4. Показать, что множество обобщеных временных разверток является линейным конусом.
5. Показать, что множество обобщеных временных разверток выпукло и замкнуто.
6. Свойства множества временных разверток при фиксированном векторе задержек. Доказать.
Литература
1. Воеводин В.В. Параллельные вычисления / В.В.Воеводин, Вл.В.Воеводин. — СПб.: БХВ-Петербург, 2002. — 608 с.
2. Харари Ф. Теория графов / Ф.Харари; пер.с англ. В.П.Козырева. — М.: Мир, 1973. — 300 с.
3. Уилсон Р. Введение в теорию графов / Р.Уилсон. — М.: Мир, 1977. — 207 с.
4. Кристофидес Н. Теория графов. Алгоритмический подход / Н.Кристофидес. — М.: Мир, 1978. — 432 с.
5. Новиков Ф.А. Дискретная математика для программистов / Ф.А.Новиков. — СПб.: Питер, 2006. — 364 с.
6. Иванов Б.Н. Дискретная математика. Алгоритмы и программы / Б.Н.Иванов. — М.: Лаборатория Базовых Знаний, 2001. — 288с.
Лекция 15. Векторные свойства временных разверток (продолжение)
План
- Ориентированная задержка цикла. Уравновешенный цикл.
- Условие совпадения множеств и с точностью до параллельного переноса.
- Пространственно-временные развертки
§
Задание вектора реализации порождает некоторый вектор задержек . В этом случае величину невязки –  можно трактовать как время незапланированного простоя в процессе использования в качестве аргумента -ой операции результата, полученного -ой операцией. Аналогичная трактовка имеет смысл и в случае произвольного вектора задержек . Если какой-то результат не используется, то его надо где-то хранить, поэтому невязки –
можно трактовать как время незапланированного простоя в процессе использования в качестве аргумента -ой операции результата, полученного -ой операцией. Аналогичная трактовка имеет смысл и в случае произвольного вектора задержек . Если какой-то результат не используется, то его надо где-то хранить, поэтому невязки –  характеризуют времена дополнительного хранения данных, как входных, так и промежуточных, обусловленные взаимной «несогласованностью» развертки и вектора задержек . Согласно утверждению 6, временная развертка минимизирует каждое из таких времен.
характеризуют времена дополнительного хранения данных, как входных, так и промежуточных, обусловленные взаимной «несогласованностью» развертки и вектора задержек . Согласно утверждению 6, временная развертка минимизирует каждое из таких времен.
Выясним, какие свойства графа алгоритма приводят к совместимости системы (3).
 Пусть задан вектор задержек . Выберем какую-нибудь последовательность вершин графа, образующую цикл: любые две соседние вершины связаны дугой, а также связаны дугой первая и последняя вершины. Установим в цикле направление обхода вершин. Будем считать, что дуга проходится в положительном направлении, если сначала встречается ее начальная вершина, а затем конечная. В противном случае считаем, что дуга проходится в отрицательном направлении.Пусть при обходе цикла
Пусть задан вектор задержек . Выберем какую-нибудь последовательность вершин графа, образующую цикл: любые две соседние вершины связаны дугой, а также связаны дугой первая и последняя вершины. Установим в цикле направление обхода вершин. Будем считать, что дуга проходится в положительном направлении, если сначала встречается ее начальная вершина, а затем конечная. В противном случае считаем, что дуга проходится в отрицательном направлении.Пусть при обходе цикла  -ая дуга проходится
-ая дуга проходится  раз в положительном направлении и
раз в положительном направлении и  раз в отрицательном. Сумму величин
раз в отрицательном. Сумму величин  по всем , соответствующим дугам цикла, будем называть ориентированной задержкой цикла. Цикл, у которого ориентированная задержка равна 0, будем называть уравновешенным.
по всем , соответствующим дугам цикла, будем называть ориентированной задержкой цикла. Цикл, у которого ориентированная задержка равна 0, будем называть уравновешенным.
Пример. Пусть  . На рис.15.1(а) дан пример уравновешенного цикла, а на рис. 15.1(б) – неуравновешенного.
. На рис.15.1(а) дан пример уравновешенного цикла, а на рис. 15.1(б) – неуравновешенного.
2. Условие совпадения множеств и с точностью до параллельного переноса
Утверждение 7.СЛАУ (3) совместна тогда и только тогда, когда все циклы графа алгоритма уравновешены, или граф алгоритма не имеет циклов.
Доказательство. Предположим, что СЛАУ (3)
–
 совместна и вектор задает ее решение. Выберем в графе алгоритма любой цикл, если он в нем имеется, и установим направление обхода. Каждому проходу -ой дуги в положительном направлении поставим в соответствие равенство – , каждому проходу той же дуги в отрицательном направлении поставим в соответствие равенство
совместна и вектор задает ее решение. Выберем в графе алгоритма любой цикл, если он в нем имеется, и установим направление обхода. Каждому проходу -ой дуги в положительном направлении поставим в соответствие равенство – , каждому проходу той же дуги в отрицательном направлении поставим в соответствие равенство  –
–  . Просуммируем все равенства согласно обходу дуг цикла. В правой части суммы будет стоять ориентированная задержка цикла. Левая часть суммы будет равна нулю, т.е. цикл уравновешенный. Действительно, при каждом проходе соседних дуг цикла инцидентная им вершина учитывается дважды. Соответствующая этой вершине величина всегда будет встречаться в двух соседних или последнем и первом уравнениях также дважды: сначала со знаком « », а затем со знаком «-» (рис.15.2). На рис.15.2(а): дуге соответствует – , следующей дуге
. Просуммируем все равенства согласно обходу дуг цикла. В правой части суммы будет стоять ориентированная задержка цикла. Левая часть суммы будет равна нулю, т.е. цикл уравновешенный. Действительно, при каждом проходе соседних дуг цикла инцидентная им вершина учитывается дважды. Соответствующая этой вершине величина всегда будет встречаться в двух соседних или последнем и первом уравнениях также дважды: сначала со знаком « », а затем со знаком «-» (рис.15.2). На рис.15.2(а): дуге соответствует – , следующей дуге  :
:  –
–  . При сложении в левой части взаимно уничтожается.
. При сложении в левой части взаимно уничтожается.
На рис 15.2(б): дуге также соответствует – , следующей дуге  : –
: –  . Но поскольку эта дуга обходится в отрицательном направлении, то ей ставится в соответствие –
. Но поскольку эта дуга обходится в отрицательном направлении, то ей ставится в соответствие –  . При сложении в левой части снова взаимно уничтожается.
. При сложении в левой части снова взаимно уничтожается.
Пусть теперь граф алгоритма либо не имеет циклов, либо все его циклы уравновешены. Покажем, что СЛАУ (3) будет совместной. Не ограничивая общности будем считать граф алгоритма односвязным. Возьмем, например, первую вершину и припишем  какое-нибудь значение. Предположим, что построен односвязный подграф, и его вершинам приписаны такие значения , что уравнения из (3) выполняются для всех дуг подграфа. Добавим новую дугу, у которой хотя бы одна вершина принадлежит построенному подграфу. Если вторая вершина не принадлежит подграфу, то соответствующее ей значение однозначно определяется из того уравнения (3), которое соответствует добавленной дуге .
какое-нибудь значение. Предположим, что построен односвязный подграф, и его вершинам приписаны такие значения , что уравнения из (3) выполняются для всех дуг подграфа. Добавим новую дугу, у которой хотя бы одна вершина принадлежит построенному подграфу. Если вторая вершина не принадлежит подграфу, то соответствующее ей значение однозначно определяется из того уравнения (3), которое соответствует добавленной дуге .
Пусть вторая вершина также принадлежит подграфу. В силу сделанного предположения об односвязности подграфа это означает, что добавленная дуга образует с некоторыми дугами подграфа какие-то циклы. Выберем любой из таких циклов и установим в нем направление обхода, при котором добавленая дуга проходится в положительном направлении. Пусть начальная вершина добавленной дуги иммет номер  , конечная – номер . Соответствующие значения
, конечная – номер . Соответствующие значения  и
и  определены раньше.Обойдем все дуги цикла, начиная с -ой вершины и кончая -ой вершиной. Снова поставим в соответствие каждому проходу -ой дуги в положительном направлении равенство – , в отрицательном направлении – равенство – . Просуммируем эти равенства. Согласно сделанному выше замечанию, сумма левых частей даст выражение
определены раньше.Обойдем все дуги цикла, начиная с -ой вершины и кончая -ой вершиной. Снова поставим в соответствие каждому проходу -ой дуги в положительном направлении равенство – , в отрицательном направлении – равенство – . Просуммируем эти равенства. Согласно сделанному выше замечанию, сумма левых частей даст выражение  . Сумма правых частей, принимая во внимание уравновешенность цикла, даст
. Сумма правых частей, принимая во внимание уравновешенность цикла, даст  . Следовательно, уравнение (3) для
. Следовательно, уравнение (3) для  -ой дуги уже выполнено. Продолжая процесс присоединения новых дуг, припишем в конце концов всем вершинам графа алгоритма такие значения , что будут выполняться все уравнения (3). Тем самым получено какое-то решение (3), т.е. установлено совместность этой системы.
-ой дуги уже выполнено. Продолжая процесс присоединения новых дуг, припишем в конце концов всем вершинам графа алгоритма такие значения , что будут выполняться все уравнения (3). Тем самым получено какое-то решение (3), т.е. установлено совместность этой системы.
Решение системы (3) в случае односвязности графа однозначно определяется при фиксации значения любой из его координат и остается решением при добавлении вектора (1,1,…,1).
§
До сих пор форма представления временных разверток не имела для нас существенного значения: допускалась произвольная нумерация вершин графовалгоритмов, временные развертки рассматривались как векторы. Это дало возможность выявить наиболее общие свойства..
Представление временных разверток в виде векторов соответствует такому описанию алгоритма, где множество выполняемых операций идентифицируется одним целочисленным параметром. Это в общем случае не очень удобно.
Для повышения эффективности исследований необходимо более тесно связывать как граф алгоритма, так и формы представления временных разверток с формами записи алгоритмов.
При практической реализации алгоритмов устанавливается по сути дела взаимно-однозначное соответствие между множеством вектор-индексов (параметрами циклов) и множеством операций, выполняемых в процессе реализации алгоритма. Это подсказывает естественный путь размещения вершин графа алгоритма. Будем отождествлять вершины с вектор-индексами и считать их точками конечномерных пространств. Тогда множество вершин будет заполнять некоторую область, которая может быть многосвязной и состоять из подобластей разной размерности. Напомним, что точки-вершины имеют целочисленные координаты, хотя это требование, вообще говоря, не обязательно. Теперь ясно, что и временые развертки нужно рассматривать как функции, заданные на множестве точек-вершин.
Будем считать, что вершины графа алгоритма размещены в некоторой области  . Если задана какая-то временная развертка, то тем самым каждой из точек вершин приписывается вполне определенное число, совпадающее с времененм выполнения соответствующей операции. Таким образом, временные развертки – это функции
. Если задана какая-то временная развертка, то тем самым каждой из точек вершин приписывается вполне определенное число, совпадающее с времененм выполнения соответствующей операции. Таким образом, временные развертки – это функции  , определенные на некотором дискретном множестве точек из области . Множество значений также будет дискретным. Временные развертки, представленные в таком виде, будем называть пространственно-временными.
, определенные на некотором дискретном множестве точек из области . Множество значений также будет дискретным. Временные развертки, представленные в таком виде, будем называть пространственно-временными.
Одна из основных задач исследования структуры алгоритма – изучение множества параллельных форм. Каждая параллельная форма определяет группы одновременно выполняемых операций, называемые ярусами. В целом любая параллельная форма определяет некоторое множество временных разверток. Если же развертки задавать функциями , то элементы параллельных форм, в частности их ярусы будут иметь четкий геометрический смысл. Действительно, рассмотрим поверхность уровня  . Пусть это множество содержит какие-то вершины графа алгоритма. Тогда соответствующие этим вершинам операции выполняются в один и тот же момент, т.е. образуют ярус параллельной формы. Различные ярусы задаются различными поверхностями уровня пространственно-временных разверток.
. Пусть это множество содержит какие-то вершины графа алгоритма. Тогда соответствующие этим вершинам операции выполняются в один и тот же момент, т.е. образуют ярус параллельной формы. Различные ярусы задаются различными поверхностями уровня пространственно-временных разверток.
Исследование параллельных форм будет осуществляться тем эффективнее, чем проще устроено множество допустимых функций .поэтому очень неудобно задавать эти функции поточечно с точки зрения удобства их обработки. При чина – огромное число выполняемых операций, совпадающих с числом точек, на которых определяются пространственно-временные развертки. Поэтому надо задавать пространственно-временные развертки не поточечно, а с помощью некоторых правил.
Предположим, что пространственно-временные развертки каким-то приемлемым образом продолжены на всю область , содержащую вершины графа алгоритма.
Будем считать, что пространственно-временные развертки обладают определеными свойствами гладкости.
 Пусть для простоты область односвязная. Рассмотрим поверхности уровней
Пусть для простоты область односвязная. Рассмотрим поверхности уровней  пространственно-временные развертки . Поверхности уровней могут иметь сложное строение, в том числе, они могут быть многосвязными. Однако, если с изменением они меняются непрерывно, то по одну их сторону всегда будут находиться вершины, для которых выполнение соответствующих операций происходит до момента , а по другую сторону – вершины, для которых выполнение операций происходит после момента . Тогда перенос информации от вершин одной группы к вершинам другой группы осуществляется лишь теми дугамиграфа алгоритма, которые пересекают поверхности уровней развертки нечетное число раз. Очевидно, что совокупность всех таких дуг для любой поверхности уровня пространственно-временной развертки определяет ориентированный разрез графа алгоритма. Поверхности уровней показывают в области распределение потоков информации, перенос которой осуществляется в процессе реализации алгоритма.
пространственно-временные развертки . Поверхности уровней могут иметь сложное строение, в том числе, они могут быть многосвязными. Однако, если с изменением они меняются непрерывно, то по одну их сторону всегда будут находиться вершины, для которых выполнение соответствующих операций происходит до момента , а по другую сторону – вершины, для которых выполнение операций происходит после момента . Тогда перенос информации от вершин одной группы к вершинам другой группы осуществляется лишь теми дугамиграфа алгоритма, которые пересекают поверхности уровней развертки нечетное число раз. Очевидно, что совокупность всех таких дуг для любой поверхности уровня пространственно-временной развертки определяет ориентированный разрез графа алгоритма. Поверхности уровней показывают в области распределение потоков информации, перенос которой осуществляется в процессе реализации алгоритма.
Предположим, что граф алгоритма имеет хотя бы одну подходящую временную развертку. Она определяет систему поверхностей уровней. Эти поверхности могут быть односвязными (рис.15.3(а)), многосвязными (рис.15.3(б)). Здесь цифрами отмечены поверхности уровней, соответствующие последовательным значениям . Т.к. есть время, то систему поверхностей уровня можно трактовать как систему фиксированных состояний некоторой перемещающейся во времени поверхности.
Системам поверхностей уровней одной пространственно-временной развертки определяет некоторую параллельную форму алгоритма.
Вопросы
1. Что характеризует время дополнительного хранения данных?
2. Что называется ориентированной задержкой цикла?
3. Какой цикл называется уравновешенным?
4. Сформулировать и доказать критерий совпадения множеств и с точностью до параллельного переноса.
5. Какие временные развертки называются пространственно-временными?
Литература
1. Воеводин В.В. Параллельные вычисления / В.В.Воеводин, Вл.В.Воеводин. — СПб.: БХВ-Петербург, 2002. — 608 с.
2. Харари Ф. Теория графов / Ф.Харари; пер.с англ. В.П.Козырева. — М.: Мир, 1973. — 300 с.
3. Уилсон Р. Введение в теорию графов / Р.Уилсон. — М.: Мир, 1977. — 207 с.
4. Кристофидес Н. Теория графов. Алгоритмический подход / Н.Кристофидес. — М.: Мир, 1978. — 432 с.
5. Новиков Ф.А. Дискретная математика для программистов / Ф.А.Новиков. — СПб.: Питер, 2006. — 364 с.
6. Иванов Б.Н. Дискретная математика. Алгоритмы и программы / Б.Н.Иванов. — М.: Лаборатория Базовых Знаний, 2001. — 288с.





