

- 64bit
- Microsoft
- Openstack
- Parallels / virtuozzo / росплатформа
- Virtual i/o сервер – обзор
- Виртуализация представлений.
- Виртуальная машина
- Вычислительные комплексы масштаба предприятия на платформе ibm power
- Деревянко, солощук
- Диспетчеризация и задержки
- Диспетчеризация процессоров
- Исполнение программ
- Контейнеры 2.0
- Микроразделы – обзор
- Общие понятия виртуализации
- Процессорная емкость – пример
- Разделы в общем пуле
- Тип 1 (гибридный гипервизор)
- Affinity scheduling
64bit
Разумеется, даже без виртуализации в середине 2000х индустрия уже вовсю упиралась в ограничения 32 бит. Существовали частичные обходные пути в виде PAE (Physical Address Extension), но усложняли и замедляли код. Переход на 64 бита был предрешен.
AMD представила свою версию архитектуры, которую назвала AMD64. В Intel же возлагали надежды на платформу IA64 (Intel Architecture 64), которую мы также знаем под именем Itanium. Однако рынок встретил эту архитектуру без большого энтузиазма, и в итоге Intel были вынуждены реализовать собственную поддержку инструкций AMD64, которую сначал назвали EM64T, а потом просто Intel 64.
В конечном итоге мы все знаем эту архитектуру как AMD64, x86-64, x86_64 или иногда встречается x64.
Поскольку основное использование серверов на то время предполагалось в качестве физических, без виртуализации, то с первыми 64-битными процессорами в виртуализации случился технический курьез. В качестве лабораторных серверов часто использовались вложенные гипервизоры, далеко не все могли себе позволить несколько кластеров физических серверов. И в итоге оказывалось, что ВМ нагрузки во вложенном гипервизоре могла работать только в 32битном режиме.
В первых x86-64 процессорах разработчики, сохраняя полную совместимость с 32-битным режимом работы, в режиме 64 бит выбросили значительную часть функциональности. В данном случае проблема была в сильном упрощении сегментации памяти. Была убрана возможность гарантировать неприкосновенность небольшого участка памяти в ВМ, в котором работал обработчик исключений гипервизора.
Microsoft
Путь Microsoft в промышленную виртуализацию начался с покупки компании Connectix и ребрендинга Connectix Virtual PC в Microsoft Virtual PC 2004. Virtual PC развивался некоторое время, был включен под названием Windows Virtual PC в состав Windows 7. В Windows 8 и более поздних Virtual PC был заменен на десктопную версию Hyper-V.
На основе Virtual PC был создан серверный гипервизор Virtual Server, просуществовавший до начала 2008 года. Ввиду очевидного технологического проигрыша перед VMware ESX было принято решение о сворачивании разработки гипервизора второго типа в пользу собственного гипервизора первого типа, которым стал Hyper-V.
— Вы конечно можете подумать, что Microsoft украла идею Java. Но это неправда, Microsoft ей вдохновилась! — (из выступления представителя Microsoft на презентации Windows 2003 Server)
Из курьезных моментов можно отметить, что внутри Microsoft использование собственных продуктов по виртуализации в нулевых годах было, мягко говоря, опциональным. Существуют скриншоты Technet из статей по виртуализации, где явно присутствует в трее логотип VMware Tools. Также Марк Руссинович на Платформе 2009 в Москве проводил демонстрацию с VMware Workstation.
Стремясь занять новые рынки, Microsoft создали собственное публичное облако Azure, использовав в качестве платформы сильно модифицированный Nano Server с Hyper-V, поддержкой S2D и SDN. Стоит отметить, что изначально, Azure в некоторых моментах сильно отставал от on-premise систем.
Так например, поддержка виртуальных машин второго поколения (с поддержкой Secure Boot, загрузки с GPT-разделов, загрузки по PXE и т.д.) в Azure появилась только в 2021 году. В то время, как в On-Premise ВМ второго поколения известны еще с Windows Server 2021R2.
То же касается портальных решений: до 2021 года в Azure и Windows Azure Pack (Multi-Tenancy решение для облаков, с поддержкой SDN и Shielded VM, пришедшее на смену System Center App Controller в 2021 году) использовали одинаковый дизайн портала. После того, как Microsoft объявила курс на публичные облака, Azure вырвался вперед по разработке и внедрению различных ноу-хау.
Примерно с 2021 года можно наблюдать вполне закономерную картину: теперь все нововведения в Windows Server приходят из Azure, но никак не в обратную сторону. На это же указывает факт копирование частей документации из Azure в on-premise “как есть” (см. документацию по Azure SDN и Network Controller), что с одной стороны намекает на отношение к on-premise решениям, а с другой указывает на родство решений в части сущностей и архитектуры. Кто у кого списывал и как оно есть на самом деле — вопрос дискуссионный.
В марте 2021 года Сатья Надела (CEO Microsoft) официально объявил, что приоритетом компании становится публичное облако. Что, очевидно, символизирует постепенное сворачивание и угасание продуктов серверной линейки для on-premise (впрочем, стагнация наблюдалась еще в 2021м году, но подтвердилась с первыми бетами Windows Server и остальных линеек on-premise продуктов), за исключением Azure Edge — минимально необходимой серверной инфраструктуры в офисе заказчика для сервисов, которые никак не могут быть вынесены в облако.
Openstack
Исторически проект OpenStack появился как инициатива противопоставить что-то фактической монополии VMware в области тяжелой серверной виртуализации x86. Проект появился в 2021 благодаря совместным усилиям Rackspace Hosting (облачный провайдер) и NASA (открывшей код собственной платформы Nebula).
С течением времени к проекту присоединялись Canonical (Ubuntu Linux), Debian, SUSE, Red Hat, HP, Oracle.
Однако не все было гладко. В 2021 NASA вышла из проекта, сделав выбор в пользу AWS. В начале 2021 HPE полностью закрыла свой проект Helion на основе OpenStack.
В рамках проекта OpenStack в качестве стандартного гипервизора принят KVM. Однако в силу модульности подхода система на основе OpenStack может быть реализована с использованием иных гипервизоров, оставляя от OpenStack например только систему управления.
Существует значительный разброс мнений относительно проекта OpenStack от восторженного поклонения до серьезного скепсиса и жесткой критики. Критика не лишена оснований — были зафиксировано значительное количество проблем и потерь данных при использовании OpenStack. Что, впрочем, не мешает поклонникам все отрицать и ссылаться на криворукость при имплементации и эксплуатации систем.
Проект OpenStack не ограничивается исключительно виртуализацией, а с течением времени оброс значительным количеством разнообразных подпроектов и компонент для расширения в области стека услуг публичного облака. Причем значимость OpenStack стоит пожалуй оценивать именно в этой части — данные компоненты стали ключевыми во многих коммерческих продуктах и системах как в области виртуализации, так и за ее пределами.
В России OpenStack за пределами публичных облаков во многом известен прежде всего своей ролью в импортозамещении. Подавляющее количество решений и продуктов по виртуализации, включая гиперконвергентные системы, является упакованным OpenStack с разной степенью доработки.
Parallels / virtuozzo / росплатформа
Основанная в 1999 году Сергеем Белоусовым компания SWsoft занялась софтом для управления хостингом. В 2003 году приобретается новосибирская компания-конкурент Plesk.
В 2004 году SWsoft приобретает российскую компанию Parallels Николая Добровольского с ее продуктом Parallels Workstation (десктопный гипервизор второго типа под Windows). Объединенная компания оставляет себе имя Parallels и в скором времени взрывает рынок с Parallels Desktop для Mac (десктопный гипервизор второго типа под MacOS).
В рамках серверной виртуализации продолжается фокус на хостинг провайдерах и датацентрах, а не корпоративное использование. В силу специфики именно этого рынка ключевым продуктом стали контейнеры Virtuozzo и OpenVZ, а не системные виртуальные машины.
Впоследствии Parallels без особого успеха пытается выйти на рынок серверной корпоративной виртуализации с продуктом Parallels Bare Metal Server (впоследствии Parallels Hypervisor и Cloud Server, а затем Virtuozzo), добавляет гиперконвергентности со своим Cloud Storage. Продолжается работа над ПО автоматизации и оркестрации работы хостинг провайдеров.
В 2021 году на основе продуктов по серверной виртуализации создается проект Росплатформа — технически (опустив юридические и организационные моменты) тот же Virtuozzo, только с измененными обоями и в реестре российского ПО. На основе ПО Росплатформа и оборудования Depo компания IBS создает пакетное гиперконвергентное предложение Скала-Р.
До версии 7 Virtuozzo использовали гипервизор собственной разработки, в 7 версии был осуществлен переход на KVM. Соответственно, Росплатформа — тоже стала на основе KVM.После нескольких слияний, поглощений и ребрендингов складывается следующая картина к 2021 году.
Parallels Desktop выделен в компанию Parallels и продан Corel. Вся автоматизация ушла в компанию Odin и продана IngramMicro. Серверная виртуализация осталась под брендом Virtuozzo / Росплатформа.
Virtual i/o сервер – обзор
Рабочая среда для администрирования виртуального ввода-вывода
Минимальные аппаратные требования
Возможности Virtual I/O сервера
Технология виртуализации ввода-вывода состоит из четырех
отдельных функций:
- Virtual Ethernet (виртуальные соединения Ethernet),
- совместное использование адаптеров Ethernet,
- совместное использование адаптеров Fibre Channel, а также
- виртуализация дисков.
Совместное использование адаптеров и дисков снимает
необходимость установки отдельного адаптера на каждый
логический раздел, что делает модель ввода-вывода более
экономичной.
Инсталляционный CD – часть пакета
Advanced POWER Virtualization
Базируется на ОС AIX
Возможная конфигурация для обеспечения
высокой доступности
Адаптеры Ethernet и Fibre Channel общего пользования, а также
виртуальные диски реализуются с помощью механизма ведущих
логических разделов (Hosting LPARs). Ведущие логические
разделы, основаны на операционной системе AIX 5L,
инкапсулируются для облегчения администрирования системны.
Они владеют физическими ресурсами и распределяют их между
несколькими ведомыми разделами. Связь между ведущими и
ведомыми разделами осуществляется посредством набора
интерфейсов Hypervisor. Совместное использование физических
адаптеров Ethernet осуществляется с помощью механизма
передачи пакетов второго уровня (Layer 2 Packet Forwarder),
который пересылает пакеты между физическими сетевыми
адаптерами и логическими разделами.
Совместное
использование физических адаптеров Fibre Channel
осуществляется путем выделения логических номеров LUN сети
SAN и отображения их на клиентские логические разделы. ПО
ввода-вывода ведущего логического раздела поддерживает
связь по нескольким каналам, что позволяет защититься от
сбоев каналов Fibre Channel между ведущим разделом и
контроллерами устройств хранения SAN.
Виртуализация представлений.
Виртуализация представлений подразумевает эмуляцию интерфейса пользователя. Т.е. пользователь видит приложение и работает с ним на своём терминале, хотя на самом деле приложение выполняется на удалённом сервере, а пользователю передаётся лишь картинка удалённого приложения.
Виртуализация представлений
– это тип виртуализации, при котором приложение выполняется на удалённом сервере, а пользователю на экран выводятся результаты его выполнения.
Типичным представителем виртуализации представлений является служба терминалов Microsoft Terminal Services, которая появилась еще в конце 90-х годов, и изначально использовалась для одновременного удалённого доступа к рабочему столу сервера с нескольких компьютеров. Службы терминалов постоянно совершенствовались и предлагали всё новые возможности.
Основной принцип виртуализации представления заключается в том, что пользователь просто видит экран удалённого сеанса, а на сервер передаются нажатия кнопок на клавиатуре и манипуляции мышью. Для самого пользователя всё выглядит так, как будто он работает с обычным рабочим столом на обычном компьютере.
Рис. 1.3 Виртуализация представлений
Технология виртуализации представлений даёт целый ряд преимуществ для бизнеса:
· Сокращение затрат на приобретение рабочих станций. При использовании технологии виртуализации представлений, вместо рабочих станций могут быть закуплены дешёвые «тонкие» клиенты, которые не нужно будет ни обновлять, ни модернизировать многие годы.
· Сокращение затрат на приобретение программного обеспечения. «Тонкие» клиенты не требуют приобретения программного обеспечения, достаточно лишь иметь лицензии на подключение к серверам терминалов, цена которых значительно меньше.
· Сокращение затрат на обслуживание оборудования. «Тонкие» клиенты включают в себя маломощный процессор и видеокарту с пассивным охлаждением, не содержат жёсткого диска, и поэтому не требуют никакого обслуживания.
· Сокращение затрат на обслуживание программного обеспечения. В большинстве компаний количество системных администраторов, обслуживающих компьютеры пользователей, примерно в 10 раз больше, чем системных администраторов, обслуживающих сервера. И это естественно, т.к. число рабочих станций на порядок больше, чем серверов.
При этом, у каждой рабочей станции своя операционная система и свои приложения, с которыми могут быть свои проблемы: сбой драйвера, неудачное обновление, неверные действия пользователя, действия вирусов и т.д. При использовании служб терминалов все эти проблемы практически исключаются. Требуется обслуживать только несколько серверов терминалов и только один экземпляр каждого приложения.
Повсеместный доступ и безопасность. Сотрудники компании получают возможность работать со всеми корпоративными приложениями удалённо. Взяв с собой в командировку ноутбук или нетбук, просто воспользовавшись любым компьютером дома, пользователь получает доступ ко всем бизнес-приложениям, расположенным в корпоративной сети.
Высокая производительность и доступность. При использовании служб терминалов пользователи могут работать с ресурсоёмкими бизнес-приложениями, такими как SAP, 1С Предприятие, Oracle, Microsoft Dynamics, используя маломощные компьютеры, «тонкие» клиенты или даже нетбуки.
Все вычисления происходят на мощном сервере, совсем не нагружая компьютер пользователя. Терминальный сеанс полностью независим от компьютера, с которого работает пользователь. Так, например, бухгалтер может запустить длительный процесс формирования отчетов, выключить свой компьютер и пойти домой, а дома, подключившись к своему терминальному сеансу, может посмотреть результаты и продолжить работу. Ему будет доступен тот же рабочий стол с теми же открытыми приложениями.
Рис. 2.4 Виртуализация на базе Terminal Services
Внедрение служб терминалов на базе операционной системы Windows Server 2008 R2. В новом продукте службы терминалов были переименованы в Remote Desktop Services (RDS) и функционал был значительно расширен:
1. Появилась технология Terminal Services RemoteApp, позволяющая выводить на компьютер пользователя не весь рабочий стол удаленного сеанса, а лишь одно или несколько приложений (раньше это было возможно только с использованием решений Citrix). Теперь пользователь может просто запустить ярлычок приложения и работать с ним, как будто оно запущено локально, хотя на самом деле все вычисления по-прежнему будут выполняться на удалённом сервере.
Виртуальная машина
Виртуальная машина (VM, от англ. virtual machine) — программная и/или аппаратная система, эмулирующая аппаратное обеспечение некоторой платформы (target — целевая, или гостевая платформа) и исполняющая программы для target-платформы на host-платформе (host — хост-платформа, платформа-хозяин), или виртуализирующая некоторую платформу и создающая на ней среды, изолирующие друг от друга программы и даже операционные системы. Wikipedia.
Мы в данной статье будем говорить «виртуальная машина», подразумевая «системные виртуальные машины», позволяющие полностью имитировать все ресурсы и аппаратное обеспечение в виде программных конструктов.
Существует два основных вида ПО создания виртуальных машин — с полной и соотв. неполной виртуализацией.
Полная виртуализация — подход, при котором эмулируется вообще все аппаратное обеспечение, включая процессор. Позволяет создавать аппаратно независимые среды, и запускать например ОС и прикладное ПО для платформы x86 на системах SPARC, или всем известные эмуляторы Spectrum с процессором Z80 на привычных x86.
Неполная виртуализация — подход, при котором виртуализуются не 100% аппаратного обеспечения. Поскольку в индустрии наиболее распространена именно неполная виртуализация — мы будем говорить именно о ней. О платформах и технологиях системных виртуальных машин с неполной виртуализацией для архитектуры x86.
Вычислительные комплексы масштаба предприятия на платформе ibm power
Информационные технологии в настоящее время являются одной из основных движущих сил прогресса. Прикладные информационные системы, без которых уже никто не может себе представить существование любых организаций, постоянно совершенствуются, разработчики реагируют на быстро меняющиеся потребности заказчиков и реализуют новую функциональность – следовательно, растут требования к производительности оборудования и уже само собой разумеющейся считается высокая доступность всех информационных сервисов в режиме 24 х 7.
Рис. 1. Современная схема ВК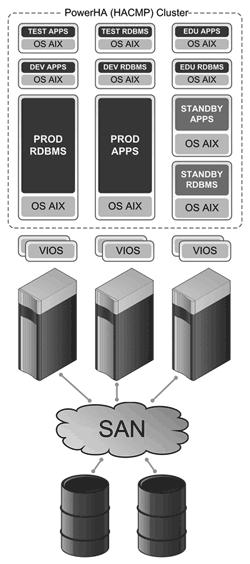
В любой организации рано или поздно принимается решение о построении новой серверной платформы, на которой будет происходить развертывание, промышленная эксплуатация и дальнейшее развитие больших корпоративных информационных систем. Иногда это связано с глобальным переходом на новый программный продукт (например, внедрение новой АБС или ERP-системы), иногда же просто приходит понимание, что существующая платформа перестала удовлетворять возросшим требованиям. Попытаемся обозначить эти требования и наметить пути, следуя которым, можно эти требования удовлетворить.
Доступность. Информационные сервисы, обеспечивающие поддержку критичных бизнес-процессов организации, должны работать всегда, чтобы ни случилось с компонентами поддерживающей инфраструктуры. Обеспечить доступность на уровне 99,9% и выше имеют возможность только кластерные архитектуры, способные автоматически изолировать сбойные участки и перераспределить нагрузку.
Производительность. В большинстве случаев нагрузка на информационные системы распределяется неравномерно в течение времени. Чтобы справиться с пиками, требуется запас по производительности. Оптимальным решением является не закупка оборудования с запасом, которое будет простаивать большую часть времени, а перераспределение ресурсов с целью использования временно свободных – технологии виртуализации и консолидации подходят для этого как нельзя лучше.
Масштабируемость. Нагрузка на оборудование обычно существенно растет в процессе развития системы. Необходимо предусмотреть оптимальную стратегию будущей модернизации (либо замены) серверов, систем хранения данных и подсистемы резервного копирования, обеспечив защиту первоначальных инвестиций и минимизировав последующие.
Поддержка развития. Серверная платформа должна поддерживать все стадии жизненного цикла информационной системы. Необходимо обеспечить возможность разработчикам развивать систему, гарантировать качественное тестирование вносимых в систему изменений и возможность их безопасного применения к промышленным окружениям.
Следовательно, является весьма востребованной функциональность создания и управления «снимками» файловых и дисковых ресурсов, используемая для создания клонов окружений и быстрого восстановления промышленного окружения, например, в случае внесения изменений, вызвавших серьезный сбой, либо устранения ошибки пользователя, повлекшей за собой потерю целостности данных.
Эффективность. В конечном счете, как всегда, речь идет только о двух ресурсах – это время и деньги. Иногда важнее одно, иногда другое, однако современные технологии позволяют избежать компромисса – минимальное время реакции на потребность увеличить производительность системы или экономия бюджета – программы CoD (Capacity on Demand) позволяют иметь в наличии аппаратный резерв мощности и мгновенно активировать его по требованию на постоянной либо временной основе. Весьма полезной является и технология Thin Provisioning, позволяющая оптимизировать требования к дисковой подсистеме.
Персонал. По сути это еще один аспект защиты инвестиций. Помимо совершенно очевидных инвестиций в оборудование и программное обеспечение следует помнить об инвестициях в технологии и персонал, поддерживающий эксплуатацию комплекса. Технологии не работают сами по себе, их реализуют конкретные специалисты, от компетентности которых зависит бoльшая часть успеха.
При смене аппаратной платформы, существенная часть знаний и опыта будет утеряна, потребуется дополнительное обучение сотрудников. Одной из кардинальных мер, позволяющих обойти эту проблему, является принятие решения о передаче поддержки на аутсорсинг, но следует понимать, что это решение должно быть осмысленным и сопровождаться комплексом мер по организации процесса управления качеством сервиса.
Чтобы построить перспективную программно-аппаратную платформу, удовлетворяющую всем вышеописанным требованиям, недостаточно просто провести закупку по спецификации – в этом случае получится всего лишь набор ящиков с оборудованием на складе и коробки с ПО на полках.
В итоговый комплекс должны войти оригинальные проектные решения (учитывающие специфику конкретного проекта), а также методики развертывания и настройки, основывающиеся на опыте квалифицированных специалистов. Результат в итоге должен получиться существенно больше, чем сумма составляющих его компонент – это и будет надежная и гибкая платформа для развития.
Из каких частей состоит современный вычислительный комплекс? Попробуем обозначить основные компоненты:
- серверная платформа (серверы, операционые системы и кластерное ПО);
- системы и сети хранения данных (СХД);
- подсистема резервного копирования и восстановления (ПРК);
- СПО управления комплексом и мониторинга его состояния.
Рис. 2. Аппаратная схема распределенного ВК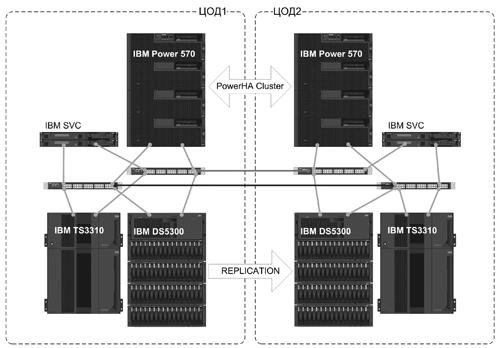
Переходя от теории к практике, рассмотрим оптимальную, с нашей точки зрения, реализацию вычислительного комплекса на оборудовании IBM.
Серверная платформа. Вычислительное ядро комплекса составляют высокопроизводительные серверы IBM Power. Система виртуализации IBM PowerVM, в целях сведения к минимуму накладных расходов, использует встроенные аппаратные возможности сетевой подсистемы (IVE – Integrated Virtual Ethernet)
и технологию NPIV (N_Port ID Virtualization). Создается два системных виртуальных раздела под управлением VIOS, которые дублируют друг друга и обеспечивают работу виртуальных устройств ввода/вывода. Каждой программной компоненте корпоративной ИС (СУБД либо серверу приложений) выделяется свой собственный виртуальный раздел.
Продвинутые возможности системы виртуализации по управлению утилизацией аппаратных ресурсов оборудования (Micro-Partitioning, Active Memory Sharing) позволяют оптимизировать требования к процессорам и оперативной памяти. В целях сокращения запланированного времени простоя системы инфраструктура подготавливается к использованию уникальной функциональности Live Partition Mobility, позволяющей переносить виртуальный раздел с одного физического сервера на другой без прекращения работы пользователей системы.
В случае возникновения незапланированной потребности в дополнительных вычислительных ресурсах, решение использует возможности программы CoD (Capacity on Demand). Функциональность CoD позволяет задействовать установленные, но неактивные процессоры и оперативную память на постоянной (активировать ресурсы) либо временной основе (активировать ресурсы по мере необходимости и платить по факту использования).
Виртуальные разделы объединены в кластеры IBM PowerHA, обеспечивающие высокую доступность информационных сервисов. Кластерное решение использует возможности тесной интерграции с удаленной репликацией дисковых систем хранения данных. Особое внимание уделено дублированию линий связи между узлами кластеров, находящихся на разных площадках – вероятность сегментирования кластера сведена к теоретическому минимуму.
СХД. В плане организации систем и сетей хранения данных, в решении могут быть использованы самые прогрессивные технологии и компоненты: дисковые массивы класса midrange IBM DS5000 либо high-end IBM DS8000, производительные SAN-коммутаторы и система виртуализации IBM SAN Volume Controller (SVC).
Решение готово к построению катастрофоустойчивой конфигурации, предусмотрена возможность разнесения оборудования по основной и резервной площадкам. Распределенная сеть хранения данных позволяет обеспечить работу системы удаленной репликации практически без ограничений по расстоянию между основным и резервным ЦОД. Выделение дискового пространства оптимизируется посредством технологии Thin Provisioning.
Тщательно продумана инфраструктура для дальнейшего развития информационных систем. Помимо продуктивных окружений для каждой подсистемы предусмотрены окружения для разработки и тестирования, включая тестирование качества и производительности после внесения изменений.
СРК. В качестве подсистемы резервного копирования и восстановления используются ленточные библиотеки семейства IBM TS3000 Tape Library, управляемые ПО IBM Tivoli Storage Manager (TSM). Подсистема управляет режимами и расписанием процессов резервного копирования, обеспечивает полную автоматизацию резервного копирования СУБД и файловых ресурсов.
СПО управления и мониторинга представляет собой программный комплекс, построенный на базе семейства продуктов IBM Tivoli и обеспечивающий эффективный, согласованный и централизованный мониторинг ключевых распределенных ресурсов с помощью единого интерфейса управления.
Система позволяет контролировать как актуальные данные, практически в режиме реального времени, так и ретроспективные данные. Элементы проактивного мониторинга существенно повышают общую надежность всего решения, позволяя персоналу реагировать на инциденты, предупреждая прерывание сервиса пользователям.
Опционально можно настроить интеграцию с системой управления инцидентами.
В процессе проектирования, на этапе уточнения требований, происходит адаптация решения и выбор оборудования под конкретные запросы заказчика. Решение обладает отличной вариативностью; если не требуется исключительная производительность, то можно использовать модели начального уровня (серверы Power 550 и дисковые массивы DS5020), однако можно масштабировать решение до уровня hi-end и построить его на серверах Power 595 и системах хранения данных DS8700.
Большие ИС требуют длительной доработки и тестирования перед запуском, поэтому достаточно часто используется принцип двухэтапного построения серверного комплекса.
На этап доработки и тестирования системы достаточно оборудования начального уровня (которое потом будет использовано для поддержки сред разработки и тестирования), а перед запуском в промышленную эксплуатацию настроенная система переносится на тяжелое решение, обеспечивающее требуемые производительность и надежность. При выборе стратегии модернизации оборудования следует рассматривать и сравнивать между собой несколько вариантов:
- старт на серверах начального уровня, затем закупка тяжелых серверов;
- использование возможностей модульного масштабирования серверов старших линеек (закупка в минимальной конфигурации, затем модернизация);
- использование программы CoD (закупка сразу целевой конфигурации комплекса с неактивными ресурсами и последующая активация перед запуском);
Выбор конкретного варианта производится исходя из экономической эффективности и реальной оценки рисков (например, если весьма вероятен сдвиг сроков запуска проекта в промышленную эксплуатацию, более привлекательным выглядит первый вариант).
Достаточно часто строящаяся платформа должна обеспечить функционирование не только новых корпоративных информационных систем, но и уже работающих, причем их платформа может быть самой разной. Миграция старых систем на новую платформу является одной из самых сложных задач в процессе реализации комплексного проекта, как из-за технических сложностей самого процесса миграции, так и по причине очень узких окон запланированного даунтайма у работающих промышленных систем.
Однако наши квалифицированные специалисты владеют самыми современными технологиями, и, обладая большим опытом проведения миграций различных корпоративных систем, способны решить самые сложные задачи заказчиков. При миграции на платформу Power, компания IBM совместно с системным интегратором, ведущим проект, предоставляет бесплатный сервис миграции – Migration Factory. Продвинутые программные решения обеспечивают надежную миграцию с минимальным временем простоя информационных сервисов.
После завершения проекта заказчик получает работоспособное и хорошо документированное комплексное решение, где все подсистемы взаимоувязаны между собой, что существенно облегчает задачу последующей поддержки инфраструктуры. Решение такого уровня будет удовлетворять всем требованиям заказчика на длительный период времени и способно адаптироваться к любым изменениям, обеспечивая управляемую, надежную и гибкую платформу для развития.
Деревянко, солощук
В корпоративной информационной системе с множеством серверов и других аппаратных средств, с множеством программных служб и приложений проблемой первостепенной важности и чрезвычайной сложности становится администрирование системы. Проблема состоит в том, что существует огромное разнообразие средств управления, большая часть которых рассчитана на применение для специфических ресурсов и служб в специфической среде и основывается на тех или иных фирменных технологиях. В гетерогенной распределенной системе обнаружение этих средств, подстройка под их требования и под их интерфейсы составляет задачу, которая не имеет легкого и экономичного решения. Однако технологии Grid подсказывают способ, как устранить эту проблемы. Виртуализация ресурсов и представление любых ресурсов распределенной системы как Web-сервисов дает возможность обращаться к любым ресурсам через стандартные интерфейсы. Расширение стандартных интерфейсов ресурсов таким образом, чтобы они описывали не только прикладные функции Web-сервисов, но и функции управления ими, даст возможность единообразного управления ресурсами и службами в гетерогенной среде.
От введения таких стандартов получат выгоду все: пользователям в гетерогенных средах легче будет совместно использовать средства управления от разных производителей и, возможно, они смогут даже обеспечить единое управление в масштабе корпорации. Производители программного обеспечения для управления при наличии стандартов идентификации, проверки и настройки характеристик ресурсов получат возможность снизить стоимость своих продуктов и расширить их функциональность и область применения. Производители устройств, выставляя интерфейсы управления в виде сервисов, обеспечат управляемость устройств большим числом средств управления и смогут снизить затраты на поддержку своих продуктов.
Диспетчеризация и задержки
Виртуальные процессоры имеют задержку диспетчеризации. Когда
виртуальные процессор становится готовым к работе, он помещается в
очередь гипервизора, где он и находится до момента диспетчеризации.
Время, проходящее между двумя этими событиями, называется задержкой
диспетчеризации.
Внешние прерывания также вызывают задержки. Внешние прерывания
передаются напрямую в раздел. Когда операционная система вызывает
гипервизор с запросом на ожидающее прерывание ( accept-pending-interrupt
hypervisor ), гипервизор, при необходимости, выделяет виртуальный
процессор на целевом разделе для обработки прерывания.
Задержки не должны вызывать функциональных проблем, но могут негативно
влиять на производительность приложений реального времени. Для оценки, в
худшем случае задержка диспетчеризации составляет 18 миллисекунд, так
как минимальный поддерживаемый цикл диспетчеризации на уровне
виртуального процессора составляет одну миллисекунду.
Эти цифры
основаны на минимальной мощности раздела, составляющей 1/10
физического процессора и периоде вращения колеса распределения
гипервизора в 10 миллисекунд. Их легко понять, если представить, что работа
виртуального процессора распределена на первую и последнюю часть двух
десятимиллисекундных интервалов.
Диспетчеризация процессоров
Управление набором процессоров в
системе (shared processor pool).
Квант времени в POWER5 – 10 мс
Общая емкость разделов
равномерно распределяется между
виртуальными процессорами
Логические разделы, работающие в общем процессорном пуле,
требуют надежного механизма гарантирования правильного
распределения свободных процессорных тактов.
Каждый микрораздел конфигурируется с конкретной
процессорной емкостью, базирующейся на количестве
processing units – entitled capacity или capacity entitlement (CE).
Выделенная емкость, вместе с определенным количеством
виртуальных процессоров, определяет физические
процессорные ресурсы, которые будут выданы разделу.
Объем времени, в течение которого работает виртуальный
процессор до окончания кванта, основывается на правах
раздела, определяемых системным администратором. Права
разделов равномерно распределяются между работающими
виртуальными процессорами, поэтому число виртуальных
процессоров влияет на продолжительность рабочего цикла
каждого процессора.
Гипервизор использует архитектурный принцип “колеса
распределения” с фиксированным периодом вращения, равным
X миллисекунд, в течение которого каждый процессор
своевременно получает свою долю ресурсов. Время
виртуальных процессоров распределяется с помощью
аппаратного вычитателя, подобно тому, как операционная
система разделяет время между процессами.
Исполнение программ
На первом занятии на спецкурсе по программированию Владимир Денисович Лелюх (земля ему пухом) говорил студентам: компьютер, несмотря на свое название, считать не умеет, он умеет делать вид, что умеет считать. Но если нечто выглядит как утка, ходит как утка и крякает как утка, с практической точки зрения это утка.
Попробуем это запомнить для дальнейшего практического использования.
Компьютер, а конкретно процессор, на самом деле ничего не исполняет — он всего лишь ожидает некоторых входных параметров в определенных местах, а после, посредством страшной черной магии, выдает некоторые результаты в определенных местах.
Программа в данном случае — это некоторый поток команд, исполняемых строго последовательно, в результате которых мы ожидаем увидеть определенный результат.Но если программа исполняется, то как можно данные вообще ввести? И вообще как-то взаимодействовать на компьютер?
Для этого были придуманы аппаратные прерывания. Пользователь нажимает на клавишу — контроллер клавиатуры сигнализирует об этом, и возникает прерывание исполнения текущей нити кода. В определенной области памяти записаны адреса обработчиков прерываний, и после сохранения текущего состояния управление передается обработчику прерывания.
У обработчиков прерываний (а основной вид обработчиков — драйверы устройств) есть возможность войти в специальный режим работы процессора, когда другие прерывания не могут осуществиться до выхода из этого режима. Что в итоге часто приводило к проблеме зависания — ошибка в драйвере не позволяла выйти из прерывания.
Контейнеры 2.0
История появления контейнеров 2.0 очень связана с изменением процесса разработки программного обеспечения. Стремление бизнеса уменьшить такой важный параметр как Time-to-market вынудило разработчиков пересмотреть подходы к созданию программных продуктов.
На смену методологии разработки Waterfall (длинные релизные циклы, обновляется приложение целиком) приходит Agile (короткие, фиксированные по времени релизные циклы, независимо обновляются составные части приложения) и заставляет разработчиков разделять монолитные приложения на компоненты.
Пока составные компоненты монолитных приложений все еще достаточно крупные и их не очень много их можно размещать и в виртуальных машинах, но когда одно приложение состоит из десятков или сотен компонент, то виртуальные машины уже не очень подходят.
Дополнительно возникает и проблема версий вспомогательного софта, библиотек и зависимостей, часто бывает ситуация, когда разные компоненты требуют разных версий или по-разному настроенных переменных окружений. Такие компоненты приходится разносить на разные виртуальные машины, т.к. практически невозможно одновременно запустить несколько версий программного обеспечения в рамках одной ОС.
Количество ВМ начинает лавинообразно расти. Тут на сцене и появляются контейнеры, позволяющие в рамках одной гостевой ОС создать несколько изолированных окружений для запуска компонент приложения. Контейнеризация приложений позволяет продолжить сегментацию монолитного приложения на еще более мелкие компоненты и перейти к парадигме одна задача = один компонент — контейнер, это и называется микросевисным походом, а каждый такой компонент — микросервис.
Микроразделы – обзор
В основе – технология мэйнфреймов
Виртуальные ресурсы совместно
используются разделами
Преимущества
Новая модель определения разделов
Микроразделы – технология, пришедшая из мэйнфреймов которая основана
на двух главных усовершенствованиях в области виртуализации сервера.
Физические процессоры и устройства ввода-вывода были виртуализированы,
давая возможность разделелять эти ресурсы между несколькими
виртуальными серверами.
Виртуализация процессоров требует новой модели разделения, так как она
существенно отличается от модели разделения, используемой на POWER4
серверах, где целые процессоры выделяются в разделы. Эти процессоры
принадлежат одному конкретному разделу. Они могут быть назначены
ручными процедурами динамического перераспределения ресурсов.
В новой
схеме, физические процессоры абстрагируются в виртуальные процессоры,
которые выделяются разделам. Эти виртуальные процессоры не могут быть
разделены, но основные физические процессоры разделены, так как они
используются, чтобы реализовать виртуальные процессоры на уровне
платформы. Это совместное использование – первичная особенность этой
новой модели разделения, и это происходит автоматически.
Администратор системы определяет количество виртуальных процессоров,
которое может использоваться разделом, а также фактическую физическую
процессорную емкость, которая должна быть выделена разделу.
Администратор системы может выделить разделу часть физического
процессора, допуская, т.о., дробное выделение процессорных ресурсов.
Общие понятия виртуализации
Пришлось увидеть множество трактовок что такое
виртуализация
и выслушать множество споров, ни на йоту не приблизивших спорящих к практическому результату. А как известно, спор двух умных людей сводится к спору об определениях. Давайте определим что такое виртуализация и что из этого проистекает.
Наверное, самым близким определением понятия “виртуализация” будет “абстрагирование” из объектно-ориентированного программирования. Или, если переводить на нормальный русский язык — это сокрытие реализации за абстрактным интерфейсом. Что, конечно, все сразу объяснило. Попробуем еще раз, но для тех, кто не изучал программирование.
Виртуализация — сокрытие конкретной реализации за универсальным стандартизованным методом обращения к ресурсам / данным.
Если попробовать применить на практике данное определение, то окажется, что оно вполне работает на совершенно неожиданных предметах. Скажем, часы. Вот были придуманы несколько тысяч лет назад солнечные часы, а в средневековье были придуманы механические. Что же там общего? Солнце и какие-то шестеренки? Бред какой-то. А потом кварцевые генераторы и все остальное.
Суть в том, что мы имеем стандартный интерфейс — стрелочный или цифровой указатель, который в универсальной стандартной форме указывает текущее время. Но имеет ли для нас значение как конкретно реализован этот механизм внутри коробки, если время указывается с достаточной для нас точностью?
— Позвольте, — можете сказать вы, — но я-то думал, что виртуализация про машины, процессоры там, и так далее!
Да, она и про машины, и про процессоры, но это лишь частный случай. Давайте рассмотрим более широко, раз уж статья смело претендует на общую теорию.
Процессорная емкость – пример
Следующая последовательность диаграмм показывает связь
между различными параметрами, используемыми для того,
чтобы управлять атрибутами производительности раздела,
работающего в общем пуле.
В примере, размер общего пула фиксирован – как процессорная
емкость раздела, в котором выполняется задача.
Никакой другой раздел не активен – это позволяет задаче
использовать весь доступный ресурс и означает, что мы
игнорируем эффекты весов.
Это – опорная линия для нашего примера. Раздел
сконфигурирован, чтобы иметь 16 виртуальных процессоров и
uncapped. Мы предполагаем, что больше активных разделов нет
и этот раздел может использовать все 16 реальных процессоров
в пуле.
Обратите внимание, что раздел мог бы иметь больше чем 16
виртуальных процессоров. Если бы это имело место, то все
виртуальные процессоры были бы спланированы гипервизором
за счет доступных реальных процессоров.
Темная область показывает количество доступных виртуальных
процессоров. Светлая область показывает общее количество
использованного процессорного времени. Задача выполняется
за 26 минут.
Это – точно та же самая задача, как прежде, и она использует
точно ту же самую общую сумму ресурса центрального
процессора. Однако, количество виртуальных процессоров было
уменьшено до 12. Следовательно, задача ограничена
использованием эквивалента 12 реальных процессоров, то есть
виртуальный процессор не может использовать ресурс больше
чем одного реального процессора.
Из-за уменьшенного количества мощности центрального
процессора, доступной в пределах любого данного интервала
времени, задача теперь выполняется за 27 минут.
Точно та же самая задача, как прежде. Теперь, однако, раздел
capped. Теперь вступает в силу ограничение процессорной
емкости и общая сумма ресурса, доступного в пределах любого
данного интервала времени (фактически, каждые 10 мс)
ограничены 9.5 процессорами.
Обратите внимание, что все 12 виртуальных процессоров
диспетчеризируются, но алгоритм планирования в гипервизоре
ограничивает время, которое каждый может работать.
Задача теперь выполняется за 28 минут.
Разделы в общем пуле
Технология микроразделов позволяет
нескольким разделам использовать один
физический процессор
До 10 разделов на 1 физический
процессор
До 254 разделов в системе (в
зависимости от конфигурации)
Определение ресурсов раздела
Микроразделы позволяют нескольким разделам совместно
использовать один физический процессор.
Раздел минимально может использовать 1/10 физического
процессора. Каждый процессор может быть разделен на 10 общих
разделов.
Микроразделы поддерживаются всеми системами на базе POWER5.
Разделы в общем пуле требуют выделенной памяти, слоты ввода-
вывода могут использоваться как выделенные, так и виртуальные.
Виртуальная абстракция процессора реализована в аппаратных
средствах и гипервизоре (компоненте встроенного программного
обеспечения – firmware). C перспективы операционной системы,
виртуальный процессор неотличим от физического процессора, если
операционная система не имеет специальных расширений, чтобы
знать о различии.
Ключевая выгода от осуществления разделения
аппаратными средствами состоит в том, чтобы позволить любой
операционной системе работать на POWER5 технологии с
небольшими изменениями или даже без них. Дополнительно, для
оптимальной производительности, операционная система может
быть расширена, чтобы эксплуатировать микроразделение более
глубоко, например, добровольно отдавая неиспользуемые такты
центрального процессора гипервизору. AIX 5L V5.3 – первая версия
AIX 5L, которая включает такие расширения.
Тип 1 (гибридный гипервизор)
Гипервизоры гибридного типа (они же тип 1 , 1a, 1.5) характеризуются изоляцией базовой ОС в особую сущность, которая называется родительский раздел (parent partition в терминологии Microsoft Hyper-V) или родительский домен (domain dom0 в терминологии Xen).
Так, после установки роли гипервизора, ядро переходит в режим поддержки виртуализации и за распределение ресурсов на хосте отвечает гипервизор. Но родительский раздел берет на себя функцию обработки обращений к драйверам устройств и операциям ввода-вывода.
По сути, родительский раздел становится неким провайдером между всеми сущностями стека виртуализации. Данный подход удобен с точки зрения совместимости с оборудованием: не требуется вшивать в гипервизор драйверы устройств, как в случае с ESXi, а значит, список устройств сильно расширяется и слабее зависит от HCL.
Верхнеуровневая архитектура гипервизоров типа 1 выглядит так:
К гипервизорам данного типа относятся: почивший VMware ESX, Microsoft Hyper-V, Xen-based гипервизоры (Citrix XenServer и реализации Xen в различных дистрибутивах Linux). Напомним, что Citrix XenServer – это немного урезанная RHEL-based OS, и ее версионность и функционал находились в прямой зависимости от текущей версии Red-Hat Enterprise Linux.
В случае с другими реализациями Xen ситуация не сильно отличается: это то же ядро Linux в режиме гипервизора Xen и базовая ОС в домене dom0. Отсюда следует однозначный вывод, что Xen-based гипервизоры относятся к гибридному типу и не являются честными гипервизорами 1 типа.
Affinity scheduling
При диспетчеризации виртуального
процессора гипервизор пытается сохранить
привязку (affinity) к ресурсам, используя
При простое физического процессора
гипервизор ищет рабочий виртуальный
процессор, который
- Имеет привязку к нему
- Не имеет привязки к какому-либо процессору
- Неограничен (uncapped)
В разделах с процессорами общего пользования нет четких
взаимоотношений между виртуальными и актуализирующими их
физическими процессорами. При выделении ресурсов
виртуальному процессору гипервизор может использовать
любой процессор из общего пула, к которому прикреплен
виртуальный процессор.
По умолчанию он пытается
использовать один и тот же физический процессор,
гарантировать это можно не всегда. В гипервизоре
употребляется понятие “домашнего узла” виртуальных
процессоров, которое позволяет выбрать наиболее подходящий
с точки зрения близости памяти физический процессор.
Планирование по близости (affinity scheduling) разработано для
сохранения содержимого кэшей памяти, что позволяет быстрее
читать и записывать рабочие наборы данных задания.
Механизмом близости активно управляет гипервизор, так как у
каждого раздела существует свой, полностью отличный от
других контекст.
На сегодняшний день поддерживается только один пул
процессоров общего пользования, поэтому подразумевается, что
все виртуальные процессоры пользуются одним и тем же пулом.





